The General Services Administration is putting the security and stability of government supply chains front and center in this planned procurement.
The General Services Administration has given industry its first draft of a potential 10-year, $919.7 million blanket purchase agreement for acquiring supply chain risk illumination software tools and related analytic support services.
GSA envisions the Supply Chain Risk Illumination Professional Tools and Services, or SCRIPTS, BPA as helping the agency bolster its ability to mitigate the risks of fraud, abuse and other adversaries’ actions against supply chains the U.S. government relies on.
Nov. 14 is the due date for questions and comments on the draft request for quotes. An industry day is scheduled for Dec. 12, and registration closes on Nov. 8, GSA said in a Friday notice to Sam.gov.
The security and stability of supply chains has been front-and-center over the past three years for essentially all sectors including public sector, given the well-documented shortages of people and parts needed to make products and systems.
While the situation has shown more improvement over recent months, GSA’s unveiling of this SCRIPTS BPA is an indication that the government wants to better position itself for responding to and helping mitigate future disruptions.
GSA designed the BPA as being available to both defense and civilian agencies seeking new illumination tools to evaluate vendors, build up cyber hygiene and gain visibility into foreign investments that may present risks to supply chains.
SCRIPTS will be a multiple-award contract with an initial five-year base period followed by a single option for five additional years. A portion of the BPA will be set aside for small businesses.
GSA will compete the BPA through its Multiple Award Schedules program for acquiring commercially oriented products and services.
The agency also encourages parties that are interested in participating in the SCRIPTS BPA to submit an e-offer via the FASt Lane process no later than Dec. 31.
Two studies find “self-supervised” models, which learn about their environment from unlabeled data, can show activity patterns similar to those of the mammalian brain.
Anne Trafton | MIT News
Publication Date: October 30, 2023
To make our way through the world, our brain must develop an intuitive understanding of the physical world around us, which we then use to interpret sensory information coming into the brain.
How does the brain develop that intuitive understanding? Many scientists believe that it may use a process similar to what’s known as “self-supervised learning.” This type of machine learning, originally developed as a way to create more efficient models for computer vision, allows computational models to learn about visual scenes based solely on the similarities and differences between them, with no labels or other information.
A pair of studies from researchers at the K. Lisa Yang Integrative Computational Neuroscience (ICoN) Center at MIT offers new evidence supporting this hypothesis. The researchers found that when they trained models known as neural networks using a particular type of self-supervised learning, the resulting models generated activity patterns very similar to those seen in the brains of animals that were performing the same tasks as the models.
The findings suggest that these models are able to learn representations of the physical world that they can use to make accurate predictions about what will happen in that world, and that the mammalian brain may be using the same strategy, the researchers say.
“The theme of our work is that AI designed to help build better robots ends up also being a framework to better understand the brain more generally,” says Aran Nayebi, a postdoc in the ICoN Center. “We can’t say if it’s the whole brain yet, but across scales and disparate brain areas, our results seem to be suggestive of an organizing principle.”
Nayebi is the lead author of one of the studies, co-authored with Rishi Rajalingham, a former MIT postdoc now at Meta Reality Labs, and senior authors Mehrdad Jazayeri, an associate professor of brain and cognitive sciences and a member of the McGovern Institute for Brain Research; and Robert Yang, an assistant professor of brain and cognitive sciences and an associate member of the McGovern Institute. Ila Fiete, director of the ICoN Center, a professor of brain and cognitive sciences, and an associate member of the McGovern Institute, is the senior author of the other study, which was co-led by Mikail Khona, an MIT graduate student, and Rylan Schaeffer, a former senior research associate at MIT.
Both studies will be presented at the 2023 Conference on Neural Information Processing Systems (NeurIPS) in December.
Modeling the physical world
Early models of computer vision mainly relied on supervised learning. Using this approach, models are trained to classify images that are each labeled with a name — cat, car, etc. The resulting models work well, but this type of training requires a great deal of human-labeled data.
To create a more efficient alternative, in recent years researchers have turned to models built through a technique known as contrastive self-supervised learning. This type of learning allows an algorithm to learn to classify objects based on how similar they are to each other, with no external labels provided.
“This is a very powerful method because you can now leverage very large modern data sets, especially videos, and really unlock their potential,” Nayebi says. “A lot of the modern AI that you see now, especially in the last couple years with ChatGPT and GPT-4, is a result of training a self-supervised objective function on a large-scale dataset to obtain a very flexible representation.”
These types of models, also called neural networks, consist of thousands or millions of processing units connected to each other. Each node has connections of varying strengths to other nodes in the network. As the network analyzes huge amounts of data, the strengths of those connections change as the network learns to perform the desired task.
As the model performs a particular task, the activity patterns of different units within the network can be measured. Each unit’s activity can be represented as a firing pattern, similar to the firing patterns of neurons in the brain. Previous work from Nayebi and others has shown that self-supervised models of vision generate activity similar to that seen in the visual processing system of mammalian brains.
In both of the new NeurIPS studies, the researchers set out to explore whether self-supervised computational models of other cognitive functions might also show similarities to the mammalian brain. In the study led by Nayebi, the researchers trained self-supervised models to predict the future state of their environment across hundreds of thousands of naturalistic videos depicting everyday scenarios.
“For the last decade or so, the dominant method to build neural network models in cognitive neuroscience is to train these networks on individual cognitive tasks. But models trained this way rarely generalize to other tasks,” Yang says. “Here we test whether we can build models for some aspect of cognition by first training on naturalistic data using self-supervised learning, then evaluating in lab settings.”
Once the model was trained, the researchers had it generalize to a task they call “Mental-Pong.” This is similar to the video game Pong, where a player moves a paddle to hit a ball traveling across the screen. In the Mental-Pong version, the ball disappears shortly before hitting the paddle, so the player has to estimate its trajectory in order to hit the ball.
The researchers found that the model was able to track the hidden ball’s trajectory with accuracy similar to that of neurons in the mammalian brain, which had been shown in a previous study by Rajalingham and Jazayeri to simulate its trajectory — a cognitive phenomenon known as “mental simulation.” Furthermore, the neural activation patterns seen within the model were similar to those seen in the brains of animals as they played the game — specifically, in a part of the brain called the dorsomedial frontal cortex. No other class of computational model has been able to match the biological data as closely as this one, the researchers say.
“There are many efforts in the machine learning community to create artificial intelligence,” Jazayeri says. “The relevance of these models to neurobiology hinges on their ability to additionally capture the inner workings of the brain. The fact that Aran’s model predicts neural data is really important as it suggests that we may be getting closer to building artificial systems that emulate natural intelligence.”
Navigating the world
The study led by Khona, Schaeffer, and Fiete focused on a type of specialized neurons known as grid cells. These cells, located in the entorhinal cortex, help animals to navigate, working together with place cells located in the hippocampus.
While place cells fire whenever an animal is in a specific location, grid cells fire only when the animal is at one of the vertices of a triangular lattice. Groups of grid cells create overlapping lattices of different sizes, which allows them to encode a large number of positions using a relatively small number of cells.
In recent studies, researchers have trained supervised neural networks to mimic grid cell function by predicting an animal’s next location based on its starting point and velocity, a task known as path integration. However, these models hinged on access to privileged information about absolute space at all times — information that the animal does not have.
Inspired by the striking coding properties of the multiperiodic grid-cell code for space, the MIT team trained a contrastive self-supervised model to both perform this same path integration task and represent space efficiently while doing so. For the training data, they used sequences of velocity inputs. The model learned to distinguish positions based on whether they were similar or different — nearby positions generated similar codes, but further positions generated more different codes.
“It’s similar to training models on images, where if two images are both heads of cats, their codes should be similar, but if one is the head of a cat and one is a truck, then you want their codes to repel,” Khona says. “We’re taking that same idea but applying it to spatial trajectories.”
Once the model was trained, the researchers found that the activation patterns of the nodes within the model formed several lattice patterns with different periods, very similar to those formed by grid cells in the brain.
“What excites me about this work is that it makes connections between mathematical work on the striking information-theoretic properties of the grid cell code and the computation of path integration,” Fiete says. “While the mathematical work was analytic — what properties does the grid cell code possess? — the approach of optimizing coding efficiency through self-supervised learning and obtaining grid-like tuning is synthetic: It shows what properties might be necessary and sufficient to explain why the brain has grid cells.”
The research was funded by the K. Lisa Yang ICoN Center, the National Institutes of Health, the Simons Foundation, the McKnight Foundation, the McGovern Institute, and the Helen Hay Whitney Foundation.
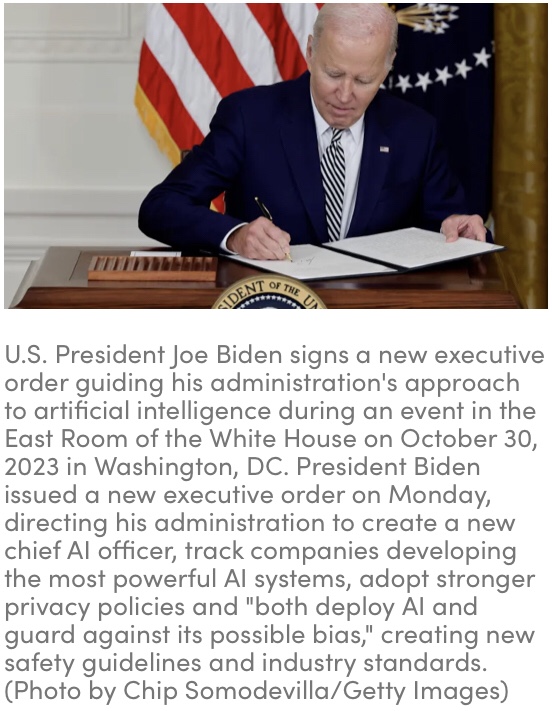
President Biden on Monday signed an executive order that, among other things, would require the Department of Defense to conduct a pilot aimed at finding ways to use AI to protect national security networks.
The EO on the “Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence,” gives the Pentagon 180 days to conduct the pilot.
The secretary of defense and the secretary of homeland security “shall, consistent with applicable law, each develop plans for, conduct, and complete an operational pilot project to identify, develop, test, evaluate, and deploy AI capabilities, such as large-language models, to aid in the discovery and remediation of vulnerabilities in critical United States Government software, systems, and networks,” the directive states.
Within the next 270 days, the two secretaries must each deliver a report to the White House on the results of actions taken “pursuant to the plans and operational pilot projects … including a description of any vulnerabilities found and fixed through the development and deployment of AI capabilities and any lessons learned on how to identify, develop, test, evaluate, and deploy AI capabilities effectively for cyber defense,” according to the EO.
The Defense Department has already set up a group known as Task Force Lima to look at potential use cases for generative AI tools such as large language models. More broadly, the Pentagon’s Chief Digital and AI Office is focused on helping deploy artificial intelligence capabilities across the department. A number of other DOD agencies and offices are also involved in artificial intelligence and cybersecurity efforts, and it wasn’t immediately clear which DOD organizations will execute the pilot that Biden directed.
Biden highlighted cybersecurity concerns during remarks at the White House on Monday before he signed the order.
“In the wrong hands, AI can make it easier for hackers to exploit vulnerabilities in the software that makes our society run. That’s why I’m directing the Department of Defense and Department of Homeland Security — both of them — to develop game-changing cyber protections that will make our computers and our critical infrastructure more secure than it is today,” he said.
Additionally, in the next six months the Pentagon chief must also deliver a report about ways to fix “gaps in AI talent” related to national defense, including recommendations for addressing challenges in the DOD’s ability to hire certain noncitizens; streamlining processes for certain noncitizens to access classified information through “Limited Access Authorization” at department labs; the appropriate use of enlistment authority under 10 U.S.C. 504(b)(2) for experts in artificial intelligence and other critical and emerging technologies; and ways that DOD and DHS can “enhance the use of appropriate authorities for the retention of certain noncitizens of vital importance to national security,” according to the directive.
Meanwhile, White House officials have been tasked with overseeing the development of a national security memorandum that will provide guidance to the Pentagon, intelligence community and other relevant agencies on the continued adoption of AI capabilities for national security missions, including as it relates to AI assurance and risk-management practices for use cases that “may affect the rights or safety of United States persons and, in appropriate contexts, non-United States persons,” per the EO.
Notably, the memo will also include directives to address the potential adversarial use of AI systems “in ways that threaten the capabilities or objectives of the Department of Defense or the Intelligence Community, or that otherwise pose risks to the security of the United States or its allies and partners.”
That document is expected to be delivered to the president within the next 270 days.
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
The US has set out its most sweeping set of AI rules and guidelines yet in an executive orderissued by President Joe Biden today. The order will require more transparency from AI companies about how their models work and will establish a raft of new standards, most notably for labeling AI-generated content.
The goal of the order, according to the White House, is to improve “AI safety and security.” It also includes a requirement that developers share safety test results for new AI models with the US government if the tests show that the technology could pose a risk to national security. This is a surprising move that invokes the Defense Production Act, typically used during times of national emergency.
The executive order advances the voluntary requirements for AI policy that the White House set back in August, though it lacks specifics on how the rules will be enforced. Executive orders are also vulnerable to being overturned at any time by a future president, and they lack the legitimacy of congressional legislation on AI, which looks unlikely in the short term.
“The Congress is deeply polarized and even dysfunctional to the extent that it is very unlikely to produce any meaningful AI legislation in the near future,” says Anu Bradford, a law professor at Columbia University who specializes in digital regulation.
Nevertheless, AI experts have hailed the order as an important step forward, especially thanks to its focus on watermarking and standards set by the National Institute of Standards and Technology (NIST). However, others argue that it does not go far enough to protect people against immediate harms inflicted by AI.
Here are the three most important things you need to know about the executive order and the impact it could have.
What are the new rules around labeling AI-generated content?
The White House’s executive order requires the Department of Commerce to develop guidance for labeling AI-generated content. AI companies will use this guidance to develop labeling and watermarking tools that the White House hopes federal agencies will adopt. “Federal agencies will use these tools to make it easy for Americans to know that the communications they receive from their government are authentic—and set an example for the private sector and governments around the world,” according to a fact sheet that the White House shared over the weekend.
The hope is that labeling the origins of text, audio, and visual content will make it easier for us to know what’s been created using AI online. These sorts of tools are widely proposed as a solution to AI-enabled problems such as deepfakes and disinformation, and in a voluntary pledge with the White House announced in August, leading AI companies such as Google and Open AI pledged to develop such technologies.
The trouble is that technologies such as watermarks are still very much works in progress. There currently are no fully reliable ways to label text or investigate whether a piece of content was machine generated. AI detection tools are still easy to fool.
The executive order also falls short of requiring industry players or government agencies to use these technologies.
On a call with reporters on Sunday, a White House spokesperson responded to a question from MIT Technology Review about whether any requirements are anticipated for the future, saying, “I can imagine, honestly, a version of a call like this in some number of years from now and there’ll be a cryptographic signature attached to it that you know you’re actually speaking to [the White House press team] and not an AI version.” This executive order intends to “facilitate technological development that needs to take place before we can get to that point.”
The White House says it plans to push forward the development and use of these technologies with the Coalition for Content Provenance and Authenticity, called the C2PA initiative. As we’ve previously reported, the initiative and its affiliated open-source communityhas been growing rapidly in recent months as companies rush to label AI-generated content. The collective includes some major companies like Adobe, Intel, and Microsoft and has devised a new internet protocol that uses cryptographic techniques to encode information about the origins of a piece of content.
The coalition does not have a formal relationship with the White House, and it’s unclear what that collaboration would look like. In response to questions, Mounir Ibrahim, the cochair of the governmental affairs team, said, “C2PA has been in regular contact with various offices at the NSC [National Security Council] and White House for some time.”
The emphasis on developing watermarking is good, says Emily Bender, a professor of linguistics at the University of Washington. She says she also hopes content labeling systems can be developed for text; current watermarking technologies work best on images and audio. “[The executive order] of course wouldn’t be a requirement to watermark, but even an existence proof of reasonable systems for doing so would be an important step,” Bender says.
Will this executive order have teeth? Is it enforceable?
While Biden’s executive order goes beyond previous US government attempts to regulate AI, it places far more emphasis on establishing best practices and standards than on how, or even whether, the new directives will be enforced.
The order calls on the National Institute of Standards and Technology to set standards for extensive “red team” testing—meaning tests meant to break the models in order to expose vulnerabilities—before models are launched. NIST has been somewhat effective at documenting how accurate or biased AI systems such as facial recognition are already. In 2019, a NIST study of over 200 facial recognition systems revealed widespread racial bias in the technology.
However, the executive order does not require that AI companies adhere to NIST standards or testing methods. “Many aspects of the EO still rely on voluntary cooperation by tech companies,” says Bradford, the law professor at Columbia.
The executive order requires all companies developing new AI models whose computational size exceeds a certain threshold to notify the federal government when training the system and then share the results of safety tests in accordance with the Defense Production Act. This law has traditionally been used to intervene in commercial production at times of war or national emergencies such as the covid-19 pandemic, so this is an unusual way to push through regulations. A White House spokesperson says this mandate will be enforceable and will apply to all future commercial AI models in the US, but will likely not apply to AI models that have already been launched. The threshold is set at a point where all major AI models that could pose risks “to national security, national economic security, or national public health and safety” are likely to fall under the order, according to the White House’s fact sheet.
The executive order also calls for federal agencies to develop rules and guidelines for different applications, such as supporting workers’ rights, protecting consumers, ensuring fair competition, and administering government services. These more specific guidelines prioritize privacy and bias protections.
“Throughout, at least, there is the empowering of other agencies, who may be able to address these issues seriously,” says Margaret Mitchell, researcher and chief ethics scientist at AI startup Hugging Face. “Albeit with a much harder and more exhausting battle for some of the people most negatively affected by AI, in order to actually have their rights taken seriously.”
What has the reaction to the order been so far?
Major tech companies have largely welcomed the executive order.
Brad Smith, the vice chair and president of Microsoft, hailed it as “another critical step forward in the governance of AI technology.” Google’s president of global affairs, Kent Walker, said the company looks “forward to engaging constructively with government agencies to maximize AI’s potential—including by making government services better, faster, and more secure.”
“It’s great to see the White House investing in AI’s growth by creating a framework for responsible AI practices,” said Adobe’s general counsel and chief trust officer, Dana Rao.
The White House’s approach remains friendly to Silicon Valley, emphasizing innovation and competition rather than limitation and restriction. The strategy is in line with the policy priorities for AI regulation set forth by Senate Majority Leader Chuck Schumer, and it further crystallizes the lighter touch of the American approach to AI regulation.
However, some AI researchers say that sort of approach is cause for concern. “The biggest concern to me in this is it ignores a lot of work on how to train and develop models to minimize foreseeable harms,” says Mitchell.
Instead of preventing AI harms before deployment—for example, by making tech companies’ data practices better—the White House is using a “whack-a-mole” approach, tackling problems that have already emerged, she adds.
The highly anticipated executive order on artificial intelligence comes two days before the UK’s AI Safety Summit and attempts to position the US as a global leader on AI policy.
It will likely have implications outside the US, adds Bradford. It will set the tone for the UK summit and will likely embolden the European Union to finalize its AI Act, as the executive order sends a clear message that the US agrees with many of the EU’s policy goals.
“The executive order is probably the best we can expect from the US government at this time,” says Bradford.
A vector database is designed to store, manage and index massive quantities of high-dimensional vector data efficiently. These databases are rapidly growing in interest to create additional value for generative artificial intelligence (AI) use cases and applications. According to Gartner, by 2026, more than 30 percent of enterprises will have adopted vector databases to ground their foundation models with relevant business data.1
Unlike traditional relational databases with rows and columns, data points in a vector database are represented by vectors with a fixed number of dimensions, clustered based on similarity. This design enables low latency queries, making them ideal for AI-driven applications.
Vector databases vs. traditional databases
The nature of data has undergone a profound transformation. It’s no longer confined to structured information easily stored in traditional databases. Unstructured data is growing 30 to 60 percent year over year, comprising social media posts, images, videos, audio clips and more.2 Typically, if you wanted to load unstructured data sources into a traditional relational database to store, manage and prepare for AI, the process is labor-intensive and far from efficient, especially when it comes to new generative use cases such as similarity search. Relational databases are great for managing structured and semi-structured datasets in specific formats, while vector databases are best suited for unstructured datasets through high-dimensional vector embeddings.
What are vectors?
Enter vectors. Vectors are arrays of numbers that can represent complex objects like words, images, videos and audio, generated by a machine learning(ML) model. High-dimensional vector data is essential to machine learning, natural language processing (NLP) and other AI tasks. Some examples of vector data include:
Text: Think about the last time you interacted with a chatbot. How do they understand natural language? They rely on vectors which can represent words, paragraphs and entire documents, that are converted via machine learning algorithms.
Images: Image pixels can be described by numerical data and combined to make up a high-dimensional vector for that image.
Speech/Audio: Like images, sound waves can also be broken down into numerical data and represented as vectors, enabling AI applications such as voice recognition.
What are vector embeddings?
The volume of unstructured datasets your organization needs for AI will only continue to grow, so how do you handle millions of vectors? This is where vector embeddings and vector databases come into play. These vectors are represented in a continuous, multi-dimensional space known as an embedding, which are generated by embedding models, specialized to convert your vector data into an embedding. Vector databases serve to store and index the output of an embedding model. Vector embeddings are a numerical representation of data, grouping sets of data based on semantic meaning or similar features across virtually any data type.
For example, take the words “car” and “vehicle.” They both have similar meanings even though they are spelled differently. For an AI application to enable effective semantic search, vector representations of “car” and “vehicle” must capture their semantic similarity. When it comes to machine learning, embeddings represent high-dimensional vectors that encode this semantic information. These vector embeddings are the backbone of recommendations, chatbots and generative apps like ChatGPT.
Vector database vs graph database
Knowledge graphs represent a network of entities such as objects or events and depicts the relationship between them. A graph database is a fit-for-purpose database for storing knowledge graph information and visualizing it as a graph structure. Graph databases are built on nodes and edges that represent the known entities and complex relationships between them, while vector databases are built on high-dimensional vectors. As a result, graph databases are preferred for processing complex relationships between data points while vector databases are better for handling different forms of data such as images or videos.
How vector embeddings and vector databases work
Enterprise vector data can be fed into an embedding model such as IBM’s watsonx.ai models or Hugging Face (link resides outside ibm.com), which are specialized to convert your data into an embedding by transforming complex, high-dimensional vector data into numerical forms that computers can understand. These embeddings represent the attributes of your data used in AI tasks such as classification and anomaly detection.
Vector storage
Vector databases store the output of an embedding model algorithm, the vector embeddings. They also store each vector’s metadata, which can be queried using metadata filters. By ingesting and storing these embeddings, the database can then facilitate fast retrieval of a similarity search, matching the user’s prompt with a similar vector embedding.
Vector indexing
Storing data as embeddings isn’t enough. The vectors need to be indexed to accelerate the search process. Vector databases create indexes on vector embeddings for search functionality. The vector database indexes vectors using a machine learning algorithm. Indexing maps vectors to new data structures that enable faster similarity or distance searches, such as nearest neighbor search between vectors.
Similarity search based on querying or prompting
Querying vectors can be done via calculations measuring the distance between vectors using algorithms, such as nearest neighbor search. This measuring can be based on various similarity metrics such as cosine similarity, used by that index to measure how close or distant those vectors are. When a user queries or prompts an AI model, an embedding is computed using the same embedding model algorithm. The database calculates distances and performs similarity calculations between query vectors and vectors stored in the index. They return the most similar vectors or nearest neighbors according to the similarity ranking. These calculations support various machine learning tasks such as recommendation systems, semantic search, image recognition and other natural language processing tasks.
Vector databases and retrieval augmented generation (RAG)
Enterprises are increasingly favoring retrieval augmented generation (RAG)approach in generative AI workflows for its faster time-to-market, efficient inference and reliable output, particularly in key use cases such as customer care and HR/Talent. RAG ensures that the model is linked to the most current, reliable facts and that users have access to the model’s sources, so that its claims can be checked for accuracy. RAG is core to our ability to anchor large language models in trusted data to reduce model hallucinations. This approach relies on leveraging high-dimensional vector data to enrich prompts with semantically relevant information for in-context learning by foundation models. It requires effective storage and retrieval during the inference stage, which handles the highest volume of data. Vector databases excel at efficiently indexing, storing and retrieving these high-dimensional vectors, providing the speed, precision and scale needed for applications like recommendation engines and chatbots.
Enterprises are increasingly favoring retrieval augmented generation (RAG)approach in generative AI workflows for its faster time-to-market, efficient inference and reliable output, particularly in key use cases such as customer care and HR/Talent. RAG ensures that the model is linked to the most current, reliable facts and that users have access to the model’s sources, so that its claims can be checked for accuracy. RAG is core to our ability to anchor large language models in trusted data to reduce model hallucinations. This approach relies on leveraging high-dimensional vector data to enrich prompts with semantically relevant information for in-context learning by foundation models. It requires effective storage and retrieval during the inference stage, which handles the highest volume of data. Vector databases excel at efficiently indexing, storing and retrieving these high-dimensional vectors, providing the speed, precision and scale needed for applications like recommendation engines and chatbots.
Advantages of vector databases
While it’s clear that vector database functionality is rapidly growing in interest and adoption to enhance enterprise AI-based applications, the following benefits have also demonstrated business value for adopters:
Speed and performance: Vector databases use various indexing techniques to enable faster searching. Vector indexing along with distance-calculating algorithms such as nearest neighbor search, are particularly helpful with searching for relevant results across millions if not billions of data points, with optimized performance.
Scalability: Vector databases can store and manage massive amounts of unstructured data by scaling horizontally, maintaining performance as query demands and data volumes increase.
Cost of ownership: Vector databases are a valuable alternative to training foundation models from scratch or fine-tuning them. This reduces the cost and speed of inferencing of foundation models.
Flexibility: Whether you have images, videos or other multi-dimensional data, vector databases are built to handle complexity. Given the multiple use cases ranging from semantic search to conversational AI applications, the use of vector databases can be customized to meet your business and AI requirements.
Long term memory of LLMs: Organizations can start with a general-purpose models like IBM watsonx.ai’s Granite series models, Meta’s Llama-2 or Google’s Flan models, and then provide their own data in a vector database to enhance the output of the models and AI applications critical to retrieval augmented generation.
Data management components: Vector databases also typically provide built-in features to easily update and insert new unstructured data.
Considerations for vector databases and your data strategy
There is a breadth of options when it comes to choosing a vector database capability to meet your organization’s data and AI needs.
Types of vector databases
There are a few alternatives to choose from.
Standalone, proprietary vector databases such as Pinecone
Open-source solutions such as weaviate or milvus, which provide built-in RESTful APIs and support for Python and Java programming languages
Platforms with vector database capabilities integrated, coming soon to IBM watsonx.data
Vector database/search extensions such as PostgreSQL’s open source pgvector extension, providing vector similarity search capabilities
Integration with your data ecosystem
Vector databases should not be considered as standalone capabilities, but rather a part of your broader data and AI ecosystem. Many offer APIs, native extensions or can be integrated with your databases. Since they are built to leverage your own enterprise data to enhance your models, you must also have proper data governance and security in place to ensure the data with which you are grounding these LLMs can be trusted.
This is where a trusted data foundation plays an important role in AI, and that starts with your data and how it’s stored, managed and governed before being used for AI. Central to this is adata lakehouse, one that is open, hybrid and governed, suchIBM watsonx.data, part of thewatsonxAI data platform that fits seamlessly into a data fabric architecture. For example, IBM watsonx.data, is built to access, catalog, govern and transform all of your structured, semi-structured and unstructured data and metadata. You can then leverage this governed data and watsonx.data’s integrated vector database capabilities (tech preview Q4, 2023) for machine learning and generative AI use cases.
When vector indexing is not optimal
Using a vector store and index is well suited for applications that are based on facts or fact-based querying. For example, asking about a company’s legal terms last year or extracting specific information from complex documents. The set of retrieval context you would get would be those that are most semantically similar to your query through embedding distance. However, if you want to get a summary of topics, this doesn’t lend itself well to a vector index. In this case you would want the LLM to go through all of the different possible contexts on that topic within your data. Instead, you may use a different kind of index, such as a list index rather than a vector index, since a vector index would only fetch the most relevant data.
Use Cases of Vector Databases
The applications of vector databases are vast and growing. Some key use cases include:
Semantic search: Perform searches based on the meaning or context of a query, enabling more precise and relevant results. As not only words but phrases can be represented as vectors, semantic vector search functionality understands user intent better than general keywords.
Similarity search and applications: Find similar images, text, audio or video data with ease, for content retrieval including advanced image and speech recognition, natural language processing and more.
Recommendation engines: E-commerce sites, for instance, can use vector databases and vectors to represent customer preferences and product attributes. This enables them to suggest items similar to past purchases based on vector similarity, enhancing user experience and increasing retention.Conversational AI: Improving virtual agent interactions by enhancing the ability to parse through relevant knowledge bases efficiently and accurately to provide real-time contextual answers to user queries, along with the source documents and page numbers for reference.
Vector database capabilities
watsonx.ai
A next generation enterprise studio for AI builders to build, train, validate, tune and deploy both traditional machine learning and new generative AI capabilities powered by foundation models. Build a Q&A resource from a broad internal or external knowledge base with the help of AI tasks in watsonx.ai, such as retrieval augmented generation.
Our PostgreSQL database-as-a-service offering lets teams spend more time building with high availability, backup orchestration, point-in-time-recovery (PITR) and read replica with ease. PostgreSQL offers pgvector, an open-source vector extension that will be able to be configured with IBM Cloud PostgreSQL extensions (coming soon), providing vector similarity search capabilities.
Our Elasticsearch database-as-a-service comes with a full-text search engine, which makes it the perfect home for your unstructured text data. Elasticsearch also support various forms of semantic (link resides outside ibm.com) similarity search. It supports dense vectors (link resides outside ibm.com) for exact nearest neighbor search, but it also provides built-in AI models to compute sparse vectors and conduct advanced similarity search (link resides outside ibm.com).
VA sounds confident enough to give a timeline for when it will make selections for the T4NG2 contract, even as one protest remains active in the courts.
In a one sentence notice, the Veterans Affairs Department has announced its plan to make awards for the recompete of a $60 billion IT services contract vehicle within the next few weeks.
The Transformation Twenty-one Total Technology Next Generation 2 contract is the next iteration of T4NG, which is VA’s main vehicle for buying the services it needs to run its systems as well as modernize those systems.
VA plans to make 30 awards, with half of those reserved for veteran-owned small businesses and the remainder will be competed as full-and-open.
Much of the filings are still under seal, but we do know that the judge issued a stay on Oct. 15. It isn’t clear what the stay covers. Stays generally are an order to stop something from happening.
But if VA plans to make awards in the next couple weeks, the stay likely isn’t to stop that from happening. Attempts to get clarification from attorneys representing Booz Allen have been unsuccessful.
It is worth noting that Booz Allen is the largest prime contractor under the current T4NG iteration that opened for business in 2016.
Booz Allen has received approximately $2.9 billion in task order spend, according to GovTribe data. That translates to about 20% of VA’s total $14 billion in obligations against T4NG.
In its filing at the court, Booz Allen objected to VA’s evaluation criteria and claimed that didn’t allow the department to draw meaningful distinctions between bidders.
VA uses the T4NG program for a whole host of IT requirements to include program management, strategy, enterprise architecture, software engineering, operations, maintenance and training.
The new version will have a $60 billion ceiling and a potential 10-year period of performance, beginning with a five-year base and one option for five additional years.
Like the current iteration, T4NG2 will have an on-ramp process in later years to keep offerings and competition fresh.
FBI Director Christopher Wray called China the ‘defining threat of this generation’ in ’60 Minutes’ panel
Published 10/22/23 11:00 PM ET
Mary Papenfuss
In a chilling, riveting warning Sunday, the so-called “Five Eyes” intelligence chiefs from across the globe laid bare the unprecedented threat of China‘s historically massive theft of intellectual property, trade secrets and personal data.
FBI Director Christopher Wraywarned on 60 Minutes on CBS that he believes China represents the “defining threat of this generation.”
“There is no country that presents a broader, more comprehensive threat to our ideas, our innovation, our economic security, and ultimately, our national security,” Wray told correspondent Scott Pelley.
“We have seen efforts by the Chinese government … trying to steal intellectual property, trade secrets, personal data — all across the country,” he added, revealing that there are currently 2,000 active U.S. investigations related to Chinese government efforts to steal information.
“We’re talking about agriculture, biotech, health care, robotics, aviation, academic research,” said Wray, who noted it’s not just a “Wall Street problem,” it’s a “Main Street problem” that costs workers their jobs.
“You have [in China] the biggest hacking program in the world by far, bigger than every other major nation combined,” he noted.
In 2015, the Laser Interferometer Gravitational-Wave Observatory (LIGO), made history when it made the first direct detection of gravitational waves—ripples in space and time—produced by a pair of colliding black holes.
Since then, LIGO and its sister detector in Europe, Virgo, have detected gravitational waves from dozens of mergers between black holes as well as from collisions between a related class of stellar remnants called neutron stars. At the heart of LIGO’s success is its ability to measure the stretching and squeezing of the fabric of space-time on scales 10 thousand trillion times smaller than a human hair.
As incomprehensibly small as these measurements are, LIGO’s precision has continued to be limited by the laws of quantum physics. At very tiny, subatomic scales, empty space is filled with a faint crackling of quantum noise, which interferes with LIGO’s measurements and restricts how sensitive the observatory can be.
Now, writing in a paper accepted for publication in Physical Review X, LIGO researchers report a significant advance in a quantum technology called “squeezing” that allows them to skirt around this limit and measure undulations in space-time across the entire range of gravitational frequencies detected by LIGO.
This new “frequency-dependent squeezing” technology, in operation at LIGO since it resumed operation in May 2023, means that the detectors can now probe a larger volume of the universe and are expected to detect about 60% more mergers than before. This greatly boosts LIGO’s ability to study the exotic events that shake space and time.
“We can’t control nature, but we can control our detectors,” says Lisa Barsotti, a senior research scientist at MIT who oversaw the development of the new LIGO technology, a project that originally involved research experiments at MIT led by Matt Evans, professor of physics, and Nergis Mavalvala, the Curtis and Kathleen Marble Professor of Astrophysics and the dean of the School of Science. The effort now includes dozens of scientists and engineers based at MIT, Caltech, and the twin LIGO observatories in Hanford, Washington, and Livingston, Louisiana.
“A project of this scale requires multiple people, from facilities to engineering and optics—basically the full extent of the LIGO Lab with important contributions from the LIGO Scientific Collaboration. It was a grand effort made even more challenging by the pandemic,” Barsotti says.
“Now that we have surpassed this quantum limit, we can do a lot more astronomy,” explains Lee McCuller, assistant professor of physics at Caltech and one of the leaders of the new study. “LIGO uses lasers and large mirrors to make its observations, but we are working at a level of sensitivity that means the device is affected by the quantum realm.”
The results also have ramifications for future quantum technologies such as quantum computers and other microelectronics as well as for fundamental physics experiments. “We can take what we have learned from LIGO and apply it to problems that require measuring subatomic-scale distances with incredible accuracy,” McCuller says.
“When NSF first invested in building the twin LIGO detectors in the late 1990s, we were enthusiastic about the potential to observe gravitational waves,” says NSF Director Sethuraman Panchanathan. “Not only did these detectors make possible groundbreaking discoveries, they also unleashed the design and development of novel technologies. This is truly exemplary of the DNA of NSF—curiosity-driven explorations coupled with use-inspired innovations. Through decades of continuing investments and expansion of international partnerships, LIGO is further poised to advance rich discoveries and technological progress.”
The laws of quantum physics dictate that particles, including photons, will randomly pop in and out of empty space, creating a background hiss of quantum noise that brings a level of uncertainty to LIGO’s laser-based measurements. Quantum squeezing, which has roots in the late 1970s, is a method for hushing quantum noise, or more specifically, for pushing the noise from one place to another with the goal of making more precise measurements.
The term squeezing refers to the fact that light can be manipulated like a balloon animal. To make a dog or giraffe, one might pinch one section of a long balloon into a small precisely located joint. But then the other side of the balloon will swell out to a larger, less precise size. Light can similarly be squeezed to be more precise in one trait, such as its frequency, but the result is that it becomes more uncertain in another trait, such as its power. This limitation is based on a fundamental law of quantum mechanics called the uncertainty principle, which states that you cannot know both the position and momentum of objects (or the frequency and power of light) at the same time.
Since 2019, LIGO’s twin detectors have been squeezing light in such a way as to improve their sensitivity to the upper frequency range of gravitational waves they detect. But, in the same way that squeezing one side of a balloon results in the expansion of the other side, squeezing light has a price. By making LIGO’s measurements more precise at the high frequencies, the measurements became less precise at the lower frequencies.
“At some point, if you do more squeezing, you aren’t going to gain much. We needed to prepare for what was to come next in our ability to detect gravitational waves,” Barsotti explains.
Now, LIGO’s new frequency-dependent optical cavities—long tubes about the length of three football fields—allow the team to squeeze light in different ways depending on the frequency of gravitational waves of interest, thereby reducing noise across the whole LIGO frequency range.
“Before, we had to choose where we wanted LIGO to be more precise,” says LIGO team member Rana Adhikari, a professor of physics at Caltech. “Now we can eat our cake and have it too. We’ve known for a while how to write down the equations to make this work, but it was not clear that we could actually make it work until now. It’s like science fiction.”
Uncertainty in the quantum realm
Each LIGO facility is made up of two 4-kilometer-long arms connected to form an “L” shape. Laser beams travel down each arm, hit giant suspended mirrors, and then travel back to where they started. As gravitational waves sweep by Earth, they cause LIGO’s arms to stretch and squeeze, pushing the laser beams out of sync. This causes the light in the two beams to interfere with each other in a specific way, revealing the presence of gravitational waves.
However, the quantum noise that lurks inside the vacuum tubes that encase LIGO’s laser beams can alter the timing of the photons in the beams by minutely small amounts. McCuller likens this uncertainty in the laser light to a can of BBs.
“Imagine dumping out a can full of BBs. They all hit the ground and click and clack independently. The BBs are randomly hitting the ground, and that creates a noise. The light photons are like the BBs and hit LIGO’s mirrors at irregular times,” he said in a Caltech interview.
The squeezing technologies that have been in place since 2019 make “the photons arrive more regularly, as if the photons are holding hands rather than traveling independently,” McCuller said. The idea is to make the frequency, or timing, of the light more certain and the amplitude, or power, less certain as a way to tamp down the BB-like effects of the photons.
This is accomplished with the help of specialized crystals that essentially turn one photon into a pair of two entangled (connected) photons with lower energy. The crystals don’t directly squeeze light in LIGO’s laser beams; rather, they squeeze stray light in the vacuum of the LIGO tubes, and this light interacts with the laser beams to indirectly squeeze the laser light.
“The quantum nature of the light creates the problem, but quantum physics also gives us the solution,” Barsotti says.
An idea that began decades ago
The concept for squeezing itself dates back to the late 1970s, beginning with theoretical studies by the late Russian physicist Vladimir Braginsky; Kip Thorne, the Richard P. Feynman Professor of Theoretical Physics, Emeritus at Caltech; and Carlton Caves, professor emeritus at the University of New Mexico.
The researchers had been thinking about the limits of quantum-based measurements and communications, and this work inspired one of the first experimental demonstrations of squeezing in 1986 by H. Jeff Kimble, the William L. Valentine Professor of Physics, Emeritus at Caltech. Kimble compared squeezed light to a cucumber; the certainty of the light measurements are pushed into only one direction, or feature, turning “quantum cabbages into quantum cucumbers,” he wrote in an article in Caltech’s Engineering & Science magazine in 1993.
In 2002, researchers began thinking about how to squeeze light in the LIGO detectors, and in 2008, the first experimental demonstration of the technique was achieved at the 40-meter test facility at Caltech. In 2010, MIT researchers developed a preliminary design for a LIGO squeezer, which they tested at LIGO’s Hanford site. Parallel work done at the GEO600 detector in Germany also convinced researchers that squeezing would work. Nine years later, in 2019, after many trials and careful teamwork, LIGO began squeezing light for the first time.
“We went through a lot of troubleshooting,” says Sheila Dwyer, who has been working on the project since 2008, first as a graduate student at MIT and then as a scientist at the LIGO Hanford Observatory beginning in 2013. “Squeezing was first thought of in the late 1970s, but it took decades to get it right.”
Too much of a good thing
However, as noted earlier, there is a tradeoff that comes with squeezing. By moving the quantum noise out of the timing, or frequency, of the laser light, the researchers put the noise into the amplitude (power) of the laser light. The more powerful laser beams then push LIGO’s heavy mirrors around causing a rumbling of unwanted noise corresponding to lower frequencies of gravitational waves. These rumbles mask the detectors’ ability to sense low-frequency gravitational waves.
“Even though we are using squeezing to put order into our system, reducing the chaos, it doesn’t mean we are winning everywhere,” says Dhruva Ganapathy, a graduate student at MIT and one of four co-lead authors of the new study. “We are still bound by the laws of physics.” The other three lead authors of the study are MIT graduate student Wenxuan Jia, LIGO Livingston postdoc Masayuki Nakano, and MIT postdoc Victoria Xu.
Unfortunately, this troublesome rumbling becomes even more of a problem when the LIGO team turns up the power on its lasers. “Both squeezing and the act of turning up the power improve our quantum-sensing precision to the point where we are impacted by quantum uncertainty,” McCuller says. “Both cause more pushing of photons, which leads to the rumbling of the mirrors. Laser power simply adds more photons, while squeezing makes them more clumpy and thus rumbly.”
A win-win
The solution is to squeeze light in one way for high frequencies of gravitational waves and another way for low frequencies. It’s like going back and forth between squeezing a balloon from the top and bottom and from the sides.
This is accomplished by LIGO’s new frequency-dependent squeezing cavity, which controls the relative phases of the light waves in such a way that the researchers can selectively move the quantum noise into different features of light (phase or amplitude) depending on the frequency range of gravitational waves.
“It is true that we are doing this really cool quantum thing, but the real reason for this is that it’s the simplest way to improve LIGO’s sensitivity,” Ganapathy says. “Otherwise, we would have to turn up the laser, which has its own problems, or we would have to greatly increase the sizes of the mirrors, which would be expensive.”
LIGO’s partner observatory, Virgo, will likely also use frequency-dependent squeezing technology within the current run, which will continue until roughly the end of 2024. Next-generation larger gravitational-wave detectors, such as the planned ground-based Cosmic Explorer, will also reap the benefits of squeezed light.
With its new frequency-dependent squeezing cavity, LIGO can now detect even more black hole and neutron star collisions. Ganapathy says he’s most excited about catching more neutron star smashups. “With more detections, we can watch the neutron stars rip each other apart and learn more about what’s inside.”
“We are finally taking advantage of our gravitational universe,” Barsotti says. “In the future, we can improve our sensitivity even more. I would like to see how far we can push it.”
The study is titled “Broadband quantum enhancement of the LIGO detectors with frequency-dependent squeezing.” Many additional researchers contributed to the development of the squeezing and frequency-dependent squeezing work, including Mike Zucker of MIT and GariLynn Billingsley of Caltech, the leads of the “Advanced LIGO Plus” upgrades that includes the frequency-dependent squeezing cavity; Daniel Sigg of LIGO Hanford Observatory; Adam Mullavey of LIGO Livingston Laboratory; and David McClelland’s group from the Australian National University.
As the government’s prime contracting goal for Small Disadvantaged Businesses continues to climb, the U.S. Small Business Administration’s Office of Inspector General is sounding the alarm, saying that many of those contracts may be going to ineligible companies.
The SBA OIG’s concern: a big chunk of the SDB dollars the government takes credit for each year go to self-certified SDBs. In a recent report, the SBA OIG points out that in Fiscal Year 2022 “as much as $16.5 billion in prime contracts was awarded to small, disadvantaged businesses without a certification overseen by SBA.” The SBA OIG says that counting awards to self-certified SDBs is “inherently risky” and questions whether the SBA has effective measures in place to identify unqualified self-certified SDBs.
This is a complicated topic, but here are a a few of my thoughts.
First, I think it is very likely that a significant percentage of the self-certified SDBs in SAM don’t meet the eligibility criteria.
The criteria to qualify as a self-certified SDB are essentially the same as for the 8(a) Program, which means they are complex and can be quite confusing. I think that many businesses either misunderstand what it takes to qualify, or don’t bother taking the time to do their due diligence before checking the SDB box in SAM. I have spoken to plenty of folks who didn’t realize that SDB status includes income and net worth tests; they believed that they could check the SDB box simply because their company was minority-owned. I even had one gentleman several years ago tell me he self-certified because he “felt” disadvantaged.
Second, I think that when it comes to SDB oversight, SBA has largely acted like Charlie Brown’s parents–that is, SBA has been almost completely out of the picture. For instance, SBA has told self-certified SDBs that the 8(a) Program eligibility criteria apply, but hasn’t provided guidance about how fit the square SDB peg into the round 8(a) hole in cases where the 8(a) rules don’t seem to make sense for self-certified companies. SBA’s SDB website simply links to the 8(a) regulations with an implicit “good luck!” for companies trying to figure out how the rules apply to them.
Where could this sort of 8(a)/SDB confusion arise? Well, for example, in the wake of the Ultima federal court decision, most 8(a) Program applicants must provide written narratives demonstrating that they qualify as socially disadvantaged. SBA has provided fairly extensive guidance to 8(a) Program applicants and participants regarding the narratives. But how are self-certified SDBs supposed to meet the requirement to demonstrate their social disadvantage? Do they need to write a narrative and keep it in a desk drawer or in the cloud somewhere? Just ignore the whole discussion about narratives and hope that if they “feel” disadvantaged, that’s good enough? As far as I know, SBA has been completely silent.
Likewise, SBA hasn’t explained how a self-certified company is supposed to address 13 C.F.R. 124.106(a)(4), which says:
Any disadvantaged manager who wishes to engage in outside employment must notify SBA of the nature and anticipated duration of the outside employment and obtain the prior written approval of SBA. SBA will deny a request for outside employment which could conflict with the management of the firm or could hinder it in achieving the objectives of its business development plan.
SBA presumably wouldn’t process an “outside employment” request for approval from a self-certified SDB, but the regulation certainly seems to suggest that SBA’s approval is required. After all, nothing in the regulations exempts self-certified firms from this requirement–and again, to my knowledge, SBA hasn’t explained what SDBs are supposed to do to comply.
And what about all the 8(a) rules that call for something of a subjective judgment call? How does a self-certified company appropriately assess its own “potential for success” under 13 C.F.R. 124.107? How does it decide if the top officer has “managerial experience of the extent and complexity needed to run the concern” or if “[b]usiness relationships exist with non-disadvantaged individuals or entities which cause such dependence that the applicant or Participant cannot exercise independent business judgment without great economic risk” under 13 C.F.R. 124.106? And on and on.
The fact is that when it comes to complying with a set of eligibility rules that weren’t written for them, SDBs have been left without any concrete guidance–at leat, that I’m aware of–from SBA. Without SBA guidance, even the the SDBs that do their best due diligence have no choice but to guess how some of these 8(a) rules apply to them.
And that brings me to my third and final point. I think it’s almost inevitable that at some point in the not-too-distant future, the GAO or another watchdog will audit the self-certified component of the SDB program.
The report following this audit will make headlines and give SBA a black eye. The government’s SDB achievement on the annual scorecard will (appropriately) be called into question. Some unlucky and essentially random self-certified SDBs will be proposed for debarment and/or assessed other penalties to make an example of them and show that the government is super serious about getting tough on SDB misrepresentation. False Claims Act attorneys will suggest that anyone who won a federal contract while improperly certifying as an SDB should be liable for three times the contract’s value in damages.
Maybe for some companies, the SDB self-certification is worth it–perhaps because large primes they work with need SDB credit for their subcontracting goals. In my experience, though, many companies check the SDB box because there doesn’t seem to be any downside, and why not add “small disadvantaged business” to your marketing materials if you can?
If I were a self-certified SDB, though, I’d think twice about keeping that box checked. Are you really sure you qualify? And are the limited upsides of this self-certification really worth the risk, particularly given that the government no longer offers set-aside contracts for self-certified SDBs?
Stay tuned–I’m quite confident we haven’t heard the end of this one.
The phrase “cognitive warfare” doesn’t often appear in news stories, but it’s the crucial concept behind China’s latest efforts to use social media to target its foes.
Recent stories have ranged from Meta’s “Biggest Single Takedown” of thousands of false-front accounts on Facebook, Instagram, TikTok, X, and Substack to an effort to spread disinformation about the Hawaii fires to a campaign that used AI-generated images to amplify divisive U.S. political topics. Researchers and officials expect similar efforts to target the 2024 U.S. election, as well as in any Taiwan conflict.
Chinese government and military writings say cognitive operations aim to “capture the mind” of one’s foes, shaping an adversary’s thoughts and perceptions and consequently their decisions and actions. Unlike U.S. defense documents and strategic thinkers, the People’s Liberation Army puts cognitive warfare on par with the other domains of warfare like air, sea, and space, and believes it key to victory—particularly victory without war.
Social media platforms are viewed as the main battlefield of this fight. China, through extensive research and development of their own platforms, understands the power of social media to shape narratives and cognition over events and actions. When a typical user spends 2.5 hours a day on social media—36 full days out of the year, 5.5 years in an average lifespan—it is perhaps no surprise that the Chinese Communist Party believes it can, over time, shape and even control the cognition of individuals and whole societies.
A recent PLA Daily article lays out four social-media tactics, dubbed “confrontational actions”: Information Disturbance, Discourse Competition, Public Opinion Blackout, and Block Information. The goal is to achieve an “invisible manipulation” and “invisible embedding” of information production “to shape the target audience’s macro framework for recognizing, defining, and understanding events,” write Duan Wenling and Liu Jiali, professors of the Military Propaganda Teaching and Research Department of the School of Political Science at China’s National Defense University.
Information Disturbance (信息扰动). The authors describe it as “publishing specific information on social media to influence the target audience’s understanding of the real combat situation, and then shape their positions and change their actions.” Information Disturbance uses official social media accounts (such as CGTN, Global Times, and Xinhua News) to push and shape a narrative in specific ways.
While these official channels have taken on a more strident “Wolf Warrior” tone, recently, Information Disturbance is not just about appearing strong, advise the analysts. Indeed, they cite how during 2014’s “Twitter War” between the Israeli Defense Force and the Palestinian Qassam Brigade, the Palestinians managed to “win international support by portraying an image of being weak and the victim.” The tactic, which predates social media, is reminiscent of Deng Xiaoping’s Tao Guang Yang Hui (韬光养晦)—literally translated as “Hide brightness, nourish obscurity.” China created a specific message to target the United States (and the West more broadly) under the official messaging of the CCP, that China was a humble nation focused on economic development and friendly relationships with other countries. This narrative was very powerful for decades; it shaped the U.S. and other nations’ policy towards China.
Discourse Competition (话语竞争)The second type is a much more subtle and gradual approach to shaping cognition. The authors describe a “trolling strategy” [拖钓], “spreading narratives through social media and online comments, gradually affecting public perception, and then helping achieve war or political goals.”
Here, the idea is to “fuel the flames” of existing biases and manipulate emotional psychology to influence and deepen a desired narrative. The authors cite the incredible influence that “invisible manipulation” and “invisible embedding” can have on social media platforms such as Facebook and Twitter in international events, and recommend that algorithm recommendations be used to push more and more information to target audiences with desired biases. Over time, the emotion and bias will grow and the targeted users will reject information that does not align with their perspective.
Public Opinion Blackout (舆论遮蔽). This tactic aims to flood social media with a specific narrative to influence the direction of public opinion. The main tool to “blackout” public opinion are bots that drive the narrative viral, stamping out alternative views and news. Of note to the growing use of AI in Chinese influence operations, the authors reference studies that show that a common and effective method of exerting cognitive influence is to use machine learning to mine user emotions and prejudices to screen and target the most susceptible audiences, and then quickly and intensively “shoot” customized “spiritual ammunition” to the target group.
This aligned withIn another PLA article entitled, “How ChatGPT will Affect the Future of Warfare,” .” Here, the authors write that generative AI can “efficiently generate massive amounts of fake news, fake pictures, and even fake videos to confuse the public” at a n overall societal level of significance[8]. Their The idea is to create, in their words, a “flooding of lies”” while by the dissemination and Internet trolls to create “altered facts” creates confusion about facts and . The goal is to create confusion in the target audience’s cognition regarding the truth of “facts” and play on emotions of fear, anxiety and suspicion. to create an atmosphere of insecurity, uncertainty, and mistrust. The end-state for the targeted society is an atmosphere of insecurity, uncertainty, and mistrust.
Block Information (信息封锁). The fourth type focuses on “carrying out technical attacks, blockades, and even physical destruction of the enemy’s information communication channels”. The goal is to monopolize and control information flow by preventing an adversary from disseminating information. In this tactic, and none of the others, the Chinese analysts believe the United States has a huge advantage. They cite that in 2009, for example, the U.S. government authorized Microsoft to cut off the Internet instant messaging ports of Syria, Iran, Cuba and other countries, paralyzing their networks and trying to “erase” them from the world Internet. The authors also mention in 2022, Facebook announced restrictions on some media in Russia, Iran, and other countries, but falsely claim that the company did so to delete posts negative toward the United States, for the US to gain an advantage in “cognitive confrontation.”
However, this disparity in power over the network is changing. With the rise in popularity of TikTok, it is conceivable China has the ability to shape narratives and block negative information. For example, in 2019 TikTok reportedly suspended the account of a 17-year-old user in New Jersey after she posted a viral video criticizing the Chinese government’s treatment of the Uyghur ethnic minority. China has also demonstrated its influence over the Silicon Valley owners of popular social media platforms. Examples range from Mark Zuckerberg literally asking Xi what he should name his daughter to Elon Musk’s financial dependence on Communist China’s willingness to manufacture and sell Tesla cars. Indeed, Newsguard has found that since Musk purchased Twitter, engagement of Chinese, Russian, and Iranian disinformation sources has soared by roughly 70 percent.
China has also begun to seek greater influence over the next versions of the Internet, where its analysts describe incredible potential to better control how the CCP’s story is told. While the U.S. lacks an overall strategy or policy for the metaverse (which uses augmented and virtual reality technologies), the Chinese Ministry of Industry and Information Technology released in 2022 a five-year actionplan to lead in this space. The plan includes investing in 100 “core” companies and “form 10 public service platforms” by 2026.
China did not invent the internet, but it seeks to be at the forefront of its future as a means of not just communication and commerce but conflict. Its own analysts openly discuss the potential power of this space to achieve regime goals not previously possible. The question is not whether it will wage cognitive warfare, but are its target’s minds and networks ready?
Opinions, conclusions, and recommendations expressed or implied within are solely those of the author(s) and do not necessarily represent the views of the Air University, the Department of the Air Force, the Department of Defense, or any other U.S. government agency.