Over the past few months, we’ve documented how the vast majority of AI’s applications today are based on the category of algorithms known as deep learning, and how deep-learning algorithms find patterns in data. We’ve also covered how these technologies affect people’s lives: how they can perpetuate injustice in hiring, retail, and security and may already be doing so in the criminal legal system.
But it’s not enough just to know that this bias exists. If we want to be able to fix it, we need to understand the mechanics of how it arises in the first place.
How AI bias happens
We often shorthand our explanation of AI bias by blaming it on biased training data. The reality is more nuanced: bias can creep in long before the data is collected as well as at many other stages of the deep-learning process. For the purposes of this discussion, we’ll focus on three key stages.
Framing the problem. The first thing computer scientists do when they create a deep-learning model is decide what they actually want it to achieve. A credit card company, for example, might want to predict a customer’s creditworthiness, but “creditworthiness” is a rather nebulous concept. In order to translate it into something that can be computed, the company must decide whether it wants to, say, maximize its profit margins or maximize the number of loans that get repaid. It could then define creditworthiness within the context of that goal. The problem is that “those decisions are made for various business reasons other than fairness or discrimination,” explains Solon Barocas, an assistant professor at Cornell University who specializes in fairness in machine learning. If the algorithm discovered that giving out subprime loans was an effective way to maximize profit, it would end up engaging in predatory behavior even if that wasn’t the company’s intention.
Collecting the data. There are two main ways that bias shows up in training data: either the data you collect is unrepresentative of reality, or it reflects existing prejudices. The first case might occur, for example, if a deep-learning algorithm is fed more photos of light-skinned faces than dark-skinned faces. The resulting face recognition system would inevitably be worse at recognizing darker-skinned faces. The second case is precisely what happened when Amazon discovered that its internal recruiting tool was dismissing female candidates. Because it was trained on historical hiring decisions, which favored men over women, it learned to do the same.
Preparing the data. Finally, it is possible to introduce bias during the data preparation stage, which involves selecting which attributes you want the algorithm to consider. (This is not to be confused with the problem-framing stage. You can use the same attributes to train a model for very different goals or use very different attributes to train a model for the same goal.) In the case of modeling creditworthiness, an “attribute” could be the customer’s age, income, or number of paid-off loans. In the case of Amazon’s recruiting tool, an “attribute” could be the candidate’s gender, education level, or years of experience. This is what people often call the “art” of deep learning: choosing which attributes to consider or ignore can significantly influence your model’s prediction accuracy. But while its impact on accuracy is easy to measure, its impact on the model’s bias is not.
Why AI bias is hard to fix
Given that context, some of the challenges of mitigating bias may already be apparent to you. Here we highlight four main ones.
Unknown unknowns. The introduction of bias isn’t always obvious during a model’s construction because you may not realize the downstream impacts of your data and choices until much later. Once you do, it’s hard to retroactively identify where that bias came from and then figure out how to get rid of it. In Amazon’s case, when the engineers initially discovered that its tool was penalizing female candidates, they reprogrammed it to ignore explicitly gendered words like “women’s.” They soon discovered that the revised system was still picking up on implicitly gendered words—verbs that were highly correlated with men over women, such as “executed” and “captured”—and using that to make its decisions.
Imperfect processes. First, many of the standard practices in deep learning are not designed with bias detection in mind. Deep-learning models are tested for performance before they are deployed, creating what would seem to be a perfect opportunity for catching bias. But in practice, testing usually looks like this: computer scientists randomly split their data before training into one group that’s actually used for training and another that’s reserved for validation once training is done. That means the data you use to test the performance of your model has the same biases as the data you used to train it. Thus, it will fail to flag skewed or prejudiced results.
Lack of social context. Similarly, the way in which computer scientists are taught to frame problems often isn’t compatible with the best way to think about social problems. For example, in a new paper, Andrew Selbst, a postdoc at the Data & Society Research Institute, identifies what he calls the “portability trap.” Within computer science, it is considered good practice to design a system that can be used for different tasks in different contexts. “But what that does is ignore a lot of social context,” says Selbst. “You can’t have a system designed in Utah and then applied in Kentucky directly because different communities have different versions of fairness. Or you can’t have a system that you apply for ‘fair’ criminal justice results then applied to employment. How we think about fairness in those contexts is just totally different.” Advertisementnull
The definitions of fairness. It’s also not clear what the absence of bias should look like. This isn’t true just in computer science—this question has a long history of debate in philosophy, social science, and law. What’s different about computer science is that the concept of fairness has to be defined in mathematical terms, like balancing the false positive and false negative rates of a prediction system. But as researchers have discovered, there are many different mathematical definitions of fairness that are also mutually exclusive. Does fairness mean, for example, that the same proportion of black and white individuals should get high risk assessment scores? Or that the same level of risk should result in the same score regardless of race? It’s impossible to fulfill both definitions at the same time (here’s a more in-depth look at why), so at some point you have to pick one. But whereas in other fields this decision is understood to be something that can change over time, the computer science field has a notion that it should be fixed. “By fixing the answer, you’re solving a problem that looks very different than how society tends to think about these issues,” says Selbst.
Where we go from here
If you’re reeling from our whirlwind tour of the full scope of the AI bias problem, so am I. But fortunately a strong contingent of AI researchers are working hard to address the problem. They’ve taken a variety of approaches: algorithms that help detect and mitigate hidden biases within training data or that mitigate the biases learned by the model regardless of the data quality; processes that hold companies accountable to the fairer outcomes and discussions that hash out the different definitions of fairness.
“‘Fixing’ discrimination in algorithmic systems is not something that can be solved easily,” says Selbst. “It’s a process ongoing, just like discrimination in any other aspect of society.”
This originally appeared in our AI newsletter The Algorithm. To have it directly delivered to your inbox, sign up here for free.
Implementing a global set of standards on AI ethics can lead to a more collaborative future. Image: Pexels.
19 Nov 2021
Pascale Fung Director of the Centre for Artificial Intelligence Research (CAiRE) and Professor of Electrical & Computer Engineering, The Hong Kong University of Science and Technology
Hubert Etienne Ph.D candidate in AI ethics, Ecole Normale Supérieure, Paris
As the use of AI increases so does the need for a global governance framework.
The cultural differences between China and Europe present a unique set of challenges when it comes to aligning core ethical principles.
We examine the historical influences which inform current societal thinking and how they might work together in the future.
As a driving force in the Fourth Industrial Revolution, AI systems are increasingly being deployed in many areas of our lives around the world. A shared realisation about their societal implications has raised awareness about the necessity to develop an international framework for the governance of AI, more than 160 documents aim to contribute by proposing ethical principles and guidelines. This effort faces the challenge of moral pluralism grounded in cultural diversity between nations.
To better understand the philosophical roots and cultural context underlying these challenges, we compared the ethical principles endorsed by the Chinese National New Generation Artificial Intelligence Governance Professional Committee (CNNGAIGPC) and those promoted by the European High-level Expert Group on AI (HLEGAI).
Table comparing the ethical principles endorsed by the Chinese National New Generation Artificial Intelligence Governance Professional Committee (CNNGAIGPC) and those promoted by the European High-level Expert Group on AI (HLEGAI).
Collective vs individualistic view of cultural heritage
In many aspects the Chinese principles seem similar to the EU’s, both promoting fairness, robustness, privacy, safety and transparency. Their prescribed methodologies however reveal clear cultural differences.
The Chinese guidelines derive from a community-focused and goal-oriented perspective. “A high sense of social responsibility and self-discipline” is expected from individuals to harmoniously partake into a community promoting tolerance, shared responsibilities and open collaboration. This emphasis is clearly informed by the Confucian value of “harmony”, as an ideal balance to be achieved through the control of extreme passions – conflicts should be avoided. Other than a stern admonition against “illegal use of personal data”, there is little room for regulation. Regulation is not the aim of these principles, which are rather conceived to guide AI developers in the “right way” for the collective elevation of society.
The European principles, emerging from a more individual-focused and rights-based approach, express a different ambition, rooted in the Enlightenment and coloured by European history. Their primary goal is to protect individuals against well identified harms. Whereas the Chinese principles emphasize the promotion of good practices, the EU focuses on the prevention of malign consequences. The former draws a direction for the development of AI, so that it contributes to the improvement of society, the latter sets the limitations to its uses, so that it does not happen at the expense of certain people.
This distinction is clearly illustrated by the presentation of fairness, diversity and inclusiveness. While the EU emphasizes fairness and diversity with regard to individuals from specific demographic groups (specifying gender, ethnicity, disability, etc.), Chinese guidelines urge for the upgrade of “all industries”, reduction of “regional disparities” and prevention of data monopoly. While the EU insists on the protection of vulnerable persons and potential victims, the Chinese encourage “inclusive development through better education and training, support”.
In the promotion of these values, we also recognize two types of moral imperatives. Centred on initial conditions to fulfil, the European requirements express a strict abidance by deontologist rules in the pure Kantian tradition. In contrast, and as referring to an ideal to aim, the Chinese principles expresses softer constraints that could be satisfied on different levels, as part of a process to improve society. For the Europeans the development of AI “must be fair”, for the Chinese it should “eliminate prejudices and discriminations as much as possible”. The EU “requires processes to be transparent”, China’s requires them to “continuously improve” transparency.
Utopian vs dystopian view
Even when promoting the same concepts in a similar way, Europeans and Chinese mean different things by “privacy” and “safety”.
Aligned with the The General Data Protection Regulation (GDPR), the European promotion of privacy encompasses the protection of individual’s data from both state and commercial entities. The Chinese privacy guidelines in contrast only target private companies and their potential malicious agents. Whereas personal data is strictly protected both in the EU and in China from commercial entities, the state retains full access in China. Shocking to Europeans, this practice is readily accepted by Chinese citizens, accustomed to living in a protected society and have consistently shown the highest trust in their government. Chinese parents routinely have access to their children’s personal information to provide guidance and protection. This difference goes back to the Confucian tradition of trusting and respecting the heads of state and family.
AI, MACHINE LEARNING, TECHNOLOGY
How is the Forum helping governments to responsibly adopt AI technology?
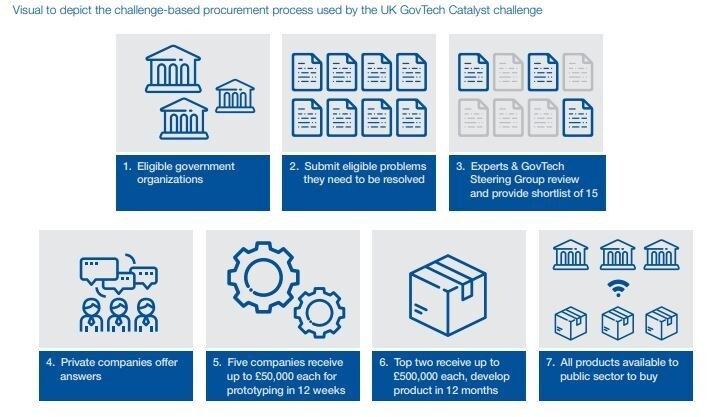
The World Economic Forum’s Centre for the Fourth Industrial Revolution, in partnership with the UK government, has developed guidelines for more ethical and efficient government procurement of artificial intelligence (AI) technology. Governments across Europe, Latin America and the Middle East are piloting these guidelines and to improve their AI procurement processes.
Our guidelines not only serve as a handy reference tool for governments looking to adopt AI technology, but also set baseline standards for effective, responsible public procurement and deployment of AI – standards that can be eventually adopted by industries.
Example of a challenge-based procurement process mentioned in the guidelines
We invite organizations that are interested in the future of AI and machine learning to get involved in this initiative. Read more about our impact.
With regards to safety, the Chinese guidelines express an optimism which contrasts with the EU’s more pessimistic tone. They approach safety as something that needs to be “improved continuously”, whereas the European vision urges for a “fall back plan”, associating the loss of control as a no-way back situation. The gap in the cultural representation of AI – perceived as a force for good in Asian cultures, and as a deep seated wariness of a dystopian technological future in the Western world – helps make sense of this difference. Robots are pets and companions in the utopian Chinese vision, they tend to become insurrectional machines as portrayed by a Western media heavily influenced by the cyberpunk subgenre of sci-fi, embodied by films like Blade Runner and The Matrix, and the TV series Black Mirror.
Where is the common ground on AI ethics?
Despite the seemingly different, though not contradictory, approaches on AI ethics from China and the EU, the presence of major commonalities between them points to a more promising and collaborative future in the implementation of these standards.
One of these is the shared tradition of Enlightenment and the Science Revolution in which all members of the AI research community are trained today. AI research and development is an open and collaborative process across the globe. The scientific method was first adopted by China among other Enlightenment values during the May Fourth Movement in 1919. Characterised as the “Chinese Enlightenment”, this movement resulted in the first ever repudiation of traditional Confucian values, and it was then believed that only by adopting Western ideas of “Mr. Science” and “Mr. Democracy” in place of “Mr. Confucius” could the nation be strengthened.
Despite the seemingly different … approaches on AI ethics from China and the EU, the presence of major commonalities between them points to a more promising and collaborative future in the implementation of these standards.—Pascale Fung and Hubert Etienne.
This anti-Confucian movement took place again during the Cultural Revolution which, given its disastrous outcome, is discredited. In the years since the third generation of Chinese leaders, the Confucian value of the “harmonious society” is again promoted as a cultural identity of the Chinese nation. Nevertheless, “Mr. Science” and “technological development” continue to be seen as a major engines for economic growth, leading to the betterment of the “harmonious society”.
Another common point between China and Europe relates to their adherence to the United Nations Sustainable Development goals. Both guidelines refer to some of these goals, including poverty and inequality reduction, gender equality, health and well-being, environmental sustainability, peace and justice, economic growth, etc., which encompass both societal and individual development and rights.
The Chinese and the EU guidelines on ethical AI may ultimately benefit from being adopted together. They provide different levels of operational details and exhibit complementary perspectives to a comprehensive framework for the governance of AI.
Pascale Fung, Director of the Centre for Artificial Intelligence Research (CAiRE) and Professor of Electrical & Computer Engineering, The Hong Kong University of Science and Technology
Hubert Etienne, Ph.D candidate in AI ethics, Ecole Normale Supérieure, Paris
The views expressed in this article are those of the author alone and not the World Economic Forum.
ARTIFICIAL INTELLIGENCE could perform more quickly, accurately, reliably, and impartially than humans on a wide range of problems, from detecting cancer to deciding who receives an interview for a job. But AIs have also suffered numerous, sometimes deadly, failures. And the increasing ubiquity of AI means that failures can affect not just individuals but millions of people.
Increasingly, the AI community is cataloging these failures with an eye toward monitoring the risks they may pose. “There tends to be very little information for users to understand how these systems work and what it means to them,” says Charlie Pownall, founder of the AI, Algorithmic and Automation Incident & Controversy Repository. “I think this directly impacts trust and confidence in these systems. There are lots of possible reasons why organizations are reluctant to get into the nitty-gritty of what exactly happened in an AI incident or controversy, not the least being potential legal exposure, but if looked at through the lens of trustworthiness, it’s in their best interest to do so.”
Part of the problem is that the neural network technology that drives many AI systems can break down in ways that remain a mystery to researchers. “It’s unpredictable which problems artificial intelligence will be good at, because we don’t understand intelligence itself very well,” says computer scientist Dan Hendrycksat the University of California, Berkeley
Here are seven examples of AI failures and what current weaknesses they reveal about artificial intelligence. Scientists discuss possible ways to deal with some of these problems; others currently defy explanation or may, philosophically speaking, lack any conclusive solution altogether.
1) Brittleness
Take a picture of a school bus. Flip it so it lays on its side, as it might be found in the case of an accident in the real world. A 2018 study found that state-of-the-art AIs that would normally correctly identify the school bus right-side-up failed to do so on average 97 percent of the time when it was rotated.
“They will say the school bus is a snowplow with very high confidence,” says computer scientist Anh Nguyen at Auburn University, in Alabama. The AIs are not capable of a task of mental rotation “that even my 3-year-old son could do,” he says.
Such a failure is an example of brittleness. An AI often “can only recognize a pattern it has seen before,” Nguyen says. “If you show it a new pattern, it is easily fooled.”
One possible way to make AIs more robust against such failures is to expose them to as many confounding “adversarial” examples as possible, Hendrycks says. However, they may still fail against rare ” black swan” events. “Black-swan problems such as COVID or the recession are hard for even humans to address—they may not be problems just specific to machine learning,” he notes.
2) Embedded Bias
Increasingly, AI is used to help support major decisions, such as who receives a loan, the length of a jail sentence, and who gets health care first. The hope is that AIs can make decisions more impartially than people often have, but much research has found that biases embedded in the data on which these AIs are trained can result in automated discrimination en masse, posing immense risks to society.
For example, in 2019, scientists found a nationally deployed health care algorithm in the United States was racially biased, affecting millions of Americans. The AI was designed to identify which patients would benefit most from intensive-care programs, but it routinely enrolled healthier white patients into such programs ahead of black patients who were sicker.
Physician and researcher Ziad Obermeyer at the University of California, Berkeley, and his colleagues found the algorithm mistakenly assumed that people with high health care costs were also the sickest patients and most in need of care. However, due to systemic racism, “black patients are less likely to get health care when they need it, so are less likely to generate costs,” he explains.null
After working with the software’s developer, Obermeyer and his colleagues helped design a new algorithm that analyzed other variables and displayed 84 percent less bias. “It’s a lot more work, but accounting for bias is not at all impossible,” he says. They recentlydrafted a playbook that outlines a few basic steps that governments, businesses, and other groups can implement to detect and prevent bias in existing and future software they use. These include identifying all the algorithms they employ, understanding this software’s ideal target and its performance toward that goal, retraining the AI if needed, and creating a high-level oversight body.
3) Catastrophic Forgetting
Deepfakes—highly realistic artificially generated fake images and videos, often of celebrities, politicians, and other public figures—are becoming increasingly common on the Internet and social media, and could wreak plenty of havoc by fraudulently depicting people saying or doing things that never really happened. To develop an AI that could detect deepfakes, computer scientist Shahroz Tariqand his colleagues at Sungkyunkwan University, in South Korea, created a website where people could upload images to check their authenticity.
In the beginning, the researchers trained their neural network to spot one kind of deepfake. However, after a few months, many new types of deepfake emerged, and when they trained their AI to identify these new varieties of deepfake, it quickly forgot how to detect the old ones.
This was an example of catastrophic forgetting—the tendency of an AI to entirely and abruptly forget information it previously knew after learning new information, essentially overwriting past knowledge with new knowledge. “Artificial neural networks have a terrible memory,” Tariq says.
AI researchers are pursuing a variety of strategies to prevent catastrophic forgetting so that neural networks can, as humans seem to do, continuously learn effortlessly. A simple technique is to create a specialized neural network for each new task one wants performed—say, distinguishing cats from dogs or apples from oranges—”but this is obviously not scalable, as the number of networks increases linearly with the number of tasks,” says machine-learning researcher Sam Kessler at the University of Oxford, in England.
One alternative Tariq and his colleagues explored as they trained their AI to spot new kinds of deepfakes was to supply it with a small amount of data on how it identified older types so it would not forget how to detect them. Essentially, this is like reviewing a summary of a textbook chapter before an exam, Tariq says.
However, AIs may not always have access to past knowledge—for instance, when dealing with private information such as medical records. Tariq and his colleagues were trying to prevent an AI from relying on data from prior tasks. They had it train itself how to spot new deepfake types while also learning from another AI that was previously trained how to recognize older deepfake varieties. They found this “knowledge distillation” strategy was roughly 87 percent accurate at detecting the kind of low-quality deepfakes typically shared on social media.
4) Explainability
Why does an AI suspect a person might be a criminal or have cancer? The explanation for this and other high-stakes predictions can have many legal, medical, and other consequences. The way in which AIs reach conclusions has long been considered a mysterious black box, leading to many attempts to devise ways to explain AIs’ inner workings. “However, my recent work suggests the field of explainability is getting somewhat stuck,” says Auburn’s Nguyen.
Nguyen and his colleaguesinvestigated seven different techniques that researchers have developed to attribute explanations for AI decisions—for instance, what makes an image of a matchstick a matchstick? Is it the flame or the wooden stick? They discovered that many of these methods “are quite unstable,” Nguyen says. “They can give you different explanations every time.”
In addition, while one attribution method might work on one set of neural networks, “it might fail completely on another set,” Nguyen adds. The future of explainability may involve building databases of correct explanations, Nguyen says. Attribution methods can then go to such knowledge bases “and search for facts that might explain decisions,” he says.
5) Quantifying Uncertainty
In 2016, a Tesla Model S car on autopilot collided with a truck that was turning left in front of it in northern Florida, killing its driver— the automated driving system’s first reported fatality. According to Tesla’s official blog, neither the autopilot system nor the driver “noticed the white side of the tractor trailer against a brightly lit sky, so the brake was not applied.”
One potential way Tesla, Uber, and other companies may avoid such disasters is for their cars to do a better job at calculating and dealing with uncertainty. Currently AIs “can be very certain even though they’re very wrong,” Oxford’s Kessler says that if an algorithm makes a decision, “we should have a robust idea of how confident it is in that decision, especially for a medical diagnosis or a self-driving car, and if it’s very uncertain, then a human can intervene and give [their] own verdict or assessment of the situation.”
For example, computer scientistMoloud Abdar at Deakin University in Australia and his colleagues applied several different uncertainty quantification techniques as an AI classified skin-cancer images as malignant or benign, or melanoma or not. The researcher found these methods helped prevent the AI from making overconfident diagnoses.
Autonomous vehicles remain challenging for uncertainty quantification, as current uncertainty-quantification techniques are often relatively time consuming, “and cars cannot wait for them,” Abdar says. “We need to have much faster approaches.”
6) Common Sense
AIs lack common sense—the ability to reach acceptable, logical conclusions based on a vast context of everyday knowledge that people usually take for granted, says computer scientist Xiang Ren at the University of Southern California. “If you don’t pay very much attention to what these models are actually learning, they can learn shortcuts that lead them to misbehave,” he says.
For instance, scientists may train AIs to detect hate speech on data where such speech is unusually high, such as white supremacist forums. However, when this software is exposed to the real world, it can fail to recognize that black and gay people may respectively use the words “black” and “gay” more often than other groups. “Even if a post is quoting a news article mentioning Jewish or black or gay people without any particular sentiment, it might be misclassified as hate speech,” Ren says. In contrast, “humans reading through a whole sentence can recognize when an adjective is used in a hateful context.”
Previous research suggested that state-of-the-art AIs could draw logical inferences about the world with up to roughly 90 percent accuracy, suggesting they were making progress at achieving common sense. However, when Ren and his colleagues tested these models, they found even the best AI could generate logically coherent sentences with slightly less than 32 percent accuracy. When it comes to developing common sense, “one thing we care a lot [about] these days in the AI community is employing more comprehensive checklists to look at the behavior of models on multiple dimensions,” he says.
7) Math
Although conventional computers are good at crunching numbers, AIs “are surprisingly not good at mathematics at all,” Berkeley’s Hendrycks says. “You might have the latest and greatest models that take hundreds of GPUs to train, and they’re still just not as reliable as a pocket calculator.”
For example, Hendrycks and his colleagues trained an AI on hundreds of thousands of math problems with step-by-step solutions. However, when tested on 12,500 problems from high school math competitions, “it only got something like 5 percent accuracy,” he says. In comparison, a three-time International Mathematical Olympiad gold medalist attained 90 percent success on such problems “without a calculator,” he adds.
Neural networks nowadays can learn to solve nearly every kind of problem “if you just give it enough data and enough resources, but not math,” Hendrycks says. Many problems in science require a lot of math, so this current weakness of AI can limit its application in scientific research, he notes.
It remains uncertain why AI is currently bad at math. One possibility is that neural networks attack problems in a highly parallel manner like human brains, whereas math problems typically require a long series of steps to solve, so maybe the way AIs process data is not as suitable for such tasks, “in the same way that humans generally can’t do huge calculations in their head,” Hendrycks says. However, AI’s poor performance on math “is still a niche topic: There hasn’t been much traction on the problem,” he adds.
Insurance companies, banks, and health-care organizations can dramatically improve their risk models by analyzing images of policyholders’ houses, say researchers.
Google Street View has become a surprisingly useful way to learn about the world without stepping into it. People use it to plan journeys, to explore holiday destinations, and to virtually stalk friends and enemies alike.
But researchers have found more insidious uses. In 2017 a team of researchers used the images to study the distribution of car types in the US and then used that data to determine the demographic makeup of the country. It turns out that the car you drive is a surprisingly reliable proxy for your income level, your education, your occupation, and even the way you vote in elections.
Now a different group has gone even further. Łukasz Kidziński at Stanford University in California and Kinga Kita-Wojciechowska at the University of Warsaw in Poland have used Street View images of people’s houses to determine how likely they are to be involved in a car accident. That’s valuable information that an insurance company could use to set premiums.
The result raises important questions about the way personal information can leak from seemingly innocent data sets and whether organizations should be able to use it for commercial purposes.
Insurance data
The researchers’ method is straightforward. They began with a data set of 20,000 records of people who had taken out car insurance in Poland between 2013 and 2015. These were randomly selected from the database of an undisclosed insurance company.
Each record included the address of the policyholder and the number of damage claims he or she made during the 2013–’15 period. The insurer also shared its own prediction of future claims, calculated using its state-of-the-art risk model that takes into account the policyholder’s zip code and the driver’s age, sex, claim history, and so on.
The question that Kidziński and Kita-Wojciechowska investigated is whether they could make a more accurate prediction using a Google Street View image of the policyholder’s house.
To find out, the researchers entered each policyholder’s address into Google Street View and downloaded an image of the residence. They classified this dwelling according to its type (detached house, terraced house, block of flats, etc.), its age, and its condition. Finally, the researchers number-crunched this data set to see how it correlated with the likelihood that a policyholder would make a claim.
The results are something of a surprise. It turns out that a policyholder’s residence is a surprisingly good predictor of the likelihood that he or she will make a claim. “We found that features visible on a picture of a house can be predictive of car accident risk, independently from classically used variables such as age or zip code,” say Kidziński and Kita-Wojciechowska.
When these factors are added to the insurer’s state-of-the-art risk model, they improve its predictive power by 2%. To put that in perspective, the insurer’s model is better than a null model by only 8% and is based on a much larger data set that includes variables such as age, sex, and claim history. Advertisementnull
So the Google Street View technique has the potential to significantly improve the prediction. And the current work is merely a proof of principle. The researchers say its accuracy could be improved using larger data sets and better data analysis.
Informed consent
The researchers’ approach raises a number of important questions about how personal data should be used. Policyholders in Poland might be startled to learn that their home addresses had been fed into Google Street View to obtain and analyze an image of their residence.
An interesting question is whether they gave informed consent to this activity and whether an insurance company can use data in this way, given Europe’s strict data privacy laws. “The consent given by the clients to the company to store their addresses does not necessarily mean a consent to store information about the appearance of their houses,” say Kidziński and Kita-Wojciechowska.
And the approach could open a Pandora’s box of data analytics. If insurance companies can benefit, why not other businesses? “The insurance industry could be quickly followed by the banks, as there is a proven correlation between insurance risk models and credit-risk scoring,” say Kidziński and Kita-Wojciechowska.
The ability to collect, analyze, and exploit information has increased dramatically in recent years. This ability has outstripped most people’s understanding of what is possible with their data, and it has certainly outstripped the speed at which legislation can be passed to control it.
Of course, Google is not the only company to collect street-level images. “Such practice, however, raises concerns about the privacy of data stored in publicly available Google Street View, Microsoft’s Bing Maps Streetside, Mapillary, or equivalent privately held data sets like CycloMedia,” say Kidziński and Kita-Wojciechowska.
This kind of work is likely to raise the question of whether these companies should be able to collect and store these images at all. In Germany, where privacy is an important issue of public debate, Google is already banned from collecting Street View images. It may not be the last place to introduce such a ban.
Ref: arxiv.org/abs/1904.05270: Google Street View Image of a House Predicts Car Accident Risk of Its Resident
Algorithms are software products, and should have a product owner subject to liability in the same way physical products have liability implications. Every algorithm can cause potential harm. Accordingly, those who produce them should be held responsible for their impact on society writ large. Too many big tech firms hide behind the anonymity of their algorithms. Separating themselves from their actions. https://www.technologyreview.com/2021/11/20/1039076/facebook-google-disinformation-clickbait/
BOSTON (16 November 2021) – The U.S. Air Force’s Platform One and Kessel Run signed a memorandum recently, titled ‘We Believe’ to continue to collaborate and support one another, their ally organizations and their end users.
The software principles memo serves as a nod to each platform’s working relationship in the Department of Defense as the premier software factories in the military software ecosystem. Both organizations have a similar ethos, culture and purpose; the memo, signed by their respective commands, was also drafted as a way to formalize collaboration efforts and blur the lines between each service, helping to prevent siloing and duplication of efforts in the DoD.
“Kessel Run and Platform One are both such huge thought leaders and cultural leaders for the department, starting with Kessel Run smuggling DevSecOps into the DOD, and continuing with Platform One leading the way to Kubernetes, a common repo, and a desire to bring the entire community together and leverage common enterprise services,” said Lauren Knausenberger, Chief Information Officer of the Air Force. “Together, these teams are moving the department forward by deploying awesome warfighting software and giving more and more Airmen the opportunity to learn agile processes. It’s a huge shift to the way we execute our mission and we need more of it.”
Platform One and Kessel Run’s respective mottos of “Only You Can Prevent Waterfall” and “Ideas Over Rank” are synthesized into key points such as “collaboration over mandates” and “flexibility is the key to staying relevant.” Key points in the memo highlight how the future of DevSecOps and agile software development depend on collaboration toward identical goals, together.
Some calls-to-action in the memo even elicit cooperation from other software teams to help build collaboration across multiple programs, as well as contributing to open source and prioritizing talent pipelines.
Kessel Run, officially known as the Air Force Life Cycle Management Center, Detachment 12, has a proven track record in enhancing efficiency, saving cost and modernizing the way the Air Force operates with its agile software development. With its user-centered approach to development, Kessel Run’s mission is to rapidly deliver combat capabilities to warfighters and revolutionize the Air Force software acquisition process.
“This statement solidifies our commitment to synergize our efforts in modernizing the Air Force with the software solutions we need today to win tomorrow,” said Col. Brian Beachkofski, Commander of Kessel Run. “Platform One and Kessel Run are building the future together.”
Platform One is a software factory focused on merging top talent from other software factories across the Department of Defense. Platform One assists software factories by helping them focus on building mission applications. They provide: collaboration and cybersecurity tools, source code repositories, artifact repositories, development tools, DevSecOps as a service, and more.
“Tomorrow’s conflict will begin with the weapon systems we’ve acquired, but will be won by our ability to adapt faster than our adversary,” said Lt. Col. Brian Viola, Commander of Platform One. “I look forward to our continued collaboration with Kessel Run and laying the foundation necessary to field at the speed of relevance, at enterprise scale.”Air Force Life Cycle Management Center Detachment 12, Kessel Run Media and Communications Engagement Email: media@kr.af.mil
2018, when Google employees found out about their company’s involvement in Project Maven, a controversial US military effort to develop AI to analyze surveillance video, they weren’t happy. Thousands protested. “We believe that Google should not be in the business of war,” they wrote in a letter to the company’s leadership. Around a dozen employees resigned. Google did not renew the contract in 2019.
Project Maven still exists, and other tech companies, including Amazon and Microsoft, have since taken Google’s place. Yet the US Department of Defense knows it has a trust problem. That’s something it must tackle to maintain access to the latest technology, especially AI—which will require partnering with Big Tech and other nonmilitary organizations.
A new survey shows the controversial systems are poised to play an even bigger role in federal business.
In a bid to promote transparency, the Defense Innovation Unit, which awards DoD contracts to companies, has released what it calls “responsible artificial intelligence” guidelines that it will require third-party developers to use when building AI for the military, whether that AI is for an HR system or target recognition.
The guidelines provide a step-by-step process for companies to follow during planning, development, and deployment. They include procedures for identifying who might use the technology, who might be harmed by it, what those harms might be, and how they might be avoided—both before the system is built and once it is up and running.
“There are no other guidelines that exist, either within the DoD or, frankly, the United States government, that go into this level of detail,” says Bryce Goodman at the Defense Innovation Unit, who coauthored the guidelines.
The work could change how AI is developed by the US government, if the DoD’s guidelines are adopted or adapted by other departments. Goodman says he and his colleagues have given them to NOAA and the Department of Transportation and are talking to ethics groups within the Department of Justice, the General Services Administration, and the IRS.
The purpose of the guidelines is to make sure that tech contractors stick to the DoD’s existing ethical principles for AI, says Goodman. The DoD announced these principles last year, following a two-year study commissioned by the Defense Innovation Board, an advisory panel of leading technology researchers and businesspeople set up in 2016 to bring the spark of Silicon Valley to the US military. The board was chaired by former Google CEO Eric Schmidt until September 2020, and its current members include Daniela Rus, the director of MIT’s Computer Science and Artificial Intelligence Lab.
Yet some critics question whether the work promises any meaningful reform.
During the study, the board consulted a range of experts, including vocal critics of the military’s use of AI, such as members of the Campaign for Killer Robots and Meredith Whittaker, a former Google researcher who helped organize the Project Maven protests.
Whittaker, who is now faculty director at New York University’s AI Now Institute, was not available for comment. But according to Courtney Holsworth, a spokesperson for the institute, she attended one meeting, where she argued with senior members of the board, including Schmidt, about the direction it was taking. “She was never meaningfully consulted,” says Holsworth. “Claiming that she was could be read as a form of ethics-washing, in which the presence of dissenting voices during a small part of a long process is used to claim that a given outcome has broad buy-in from relevant stakeholders.”
If the DoD does not have broad buy-in, can its guidelines still help to build trust? “There are going to be people who will never be satisfied by any set of ethics guidelines that the DoD produces because they find the idea paradoxical,” says Goodman. “It’s important to be realistic about what guidelines can and can’t do.”
For example, the guidelines say nothing about the use of lethal autonomous weapons, a technology that some campaigners argue should be banned. But Goodman points out that regulations governing such tech are decided higher up the chain. The aim of the guidelines is to make it easier to build AI that meets those regulations. And part of that process is to make explicit any concerns that third-party developers have. “A valid application of these guidelines is to decide not to pursue a particular system,” says Jared Dunnmon at the DIU, who coauthored them. “You can decide it’s not a good idea.”
One Defense Department advisor suggests that “constructive engagement” will be more successful than opting out.
Margaret Mitchell, an AI researcher at Hugging Face, who co-led Google’s Ethical AI team with Timnit Gebrubefore both were forced out of the company, agrees that ethics guidelines can help make a project more transparent for those working on it, at least in theory. Mitchell had a front-row seat during the protests at Google. One of the main criticisms employees had was that the company was handing over powerful tech to the military with no guardrails, she says: “People ended up leaving specifically because of the lack of any sort of clear guidelines or transparency.”
For Mitchell, the issues are not clear cut. “I think some people in Google definitely felt that all work with the military is bad,” she says. “I’m not one of those people.” She has been talking to the DoD about how it can partner with companies in a way that upholds their ethical principles.
She thinks there’s some way to go before the DoD gets the trust it needs. One problem is that some of the wording in the guidelines is open to interpretation. For example, they state: “The department will take deliberate steps to minimize unintended bias in AI capabilities.” What about intended bias? That might seem like nitpicking, but differences in interpretation depend on this kind of detail.
Monitoring the use of military technology is hard because it typically requires security clearance. To address this, Mitchell would like to see DoD contracts provide for independent auditors with the necessary clearance, who can reassure companies that the guidelines really are being followed. “Employees need some guarantee that guidelines are being interpreted as they expect,” she says.
Though most executives recognize the importance of breaking down silos to help people collaborate across boundaries, they struggle to make it happen. That’s understandable: It is devilishly difficult. Think about your own relationships at work—the people you report to and those who report to you, for starters. Now consider the people in other functions, units, or geographies whose work touches yours in some way. Which relationships get prioritized in your day-to-day job?
We’ve posed that question to managers, engineers, salespeople, and consultants in companies around the world. The response we get is almost always the same: vertical relationships.
But when we ask, “Which relationships are most important for creating value for customers?” the answers flip. Today the vast majority of innovation and business-development opportunities lie in the interfaces between functions, offices, or organizations. In short, the integrated solutions that most customers want—but companies wrestle with developing—require horizontal collaboration.
The value of horizontal teamwork is widely recognized. Employees who can reach outside their silos to find colleagues with complementary expertise learn more, sell more, and gain skillsfaster. Harvard’s Heidi Gardner has found that firms with more cross-boundary collaboration achieve greater customer loyalty and higher margins. As innovation hinges more and more on interdisciplinary cooperation, digitalization transforms business at a breakneck pace, and globalization increasingly requires people to work across national borders, the demand for executives who can lead projects at interfaces keeps rising.
Our research and consulting work with hundreds of executives and managers in dozens of organizations confirms both the need for and the challenge of horizontal collaboration. “There’s no doubt. We should focus on big projects that call for integration across practices,” a partner in a global accounting firm told us. “That’s where our greatest distinctive value is developed. But most of us confine ourselves to the smaller projects that we can handle within our practice areas. It’s frustrating.” A senior partner in a leading consulting firm put it slightly differently: “You know you should swim farther to catch a bigger fish, but it is a lot easier to swim in your own pond and catch a bunch of small fish.”
One way to break down silos is to redesign the formal organizational structure. But that approach has limits: It’s costly, confusing, and slow. Worse, every new structure solves some problems but creates others. That’s why we’ve focused on identifying activities that facilitate boundary crossing. We’ve found that people can be trained to see and connect with pools of expertise throughout their organizations and to work better with colleagues who think very differently from them. The core challenges of operating effectively at interfaces are simple: learning about people on the other side and relating to them. But simple does not mean easy; human beings have always struggled to understand and relate to those who are different.
Leaders need to help people develop the capacity to overcome these challenges on both individual and organizational levels. That means providing training in and support for four practices that enable effective interface work.
1. Develop and Deploy Cultural Brokers
Fortunately, in most companies there are people who already excel at interface collaboration. They usually have experiences and relationships that span multiple sectors, functions, or domains and informally serve as links between them. We call these people cultural brokers. In studies involving more than 2,000 global teams, one of us—Sujin—found that diverse teams containing a cultural broker significantly outperformed diverse teams without one. (See “The Most Creative Teams Have a Specific Type of Cultural Diversity,”HBR.org, July 24, 2018.) Companies should identify these individuals and help them increase their impact.
Cultural brokers promote cross-boundary work in one of two ways: by acting as a bridge or as an adhesive.
A bridge offers himself as a go-between, allowing people in different functions or geographies to collaborate with minimal disruption to their day-to-day routine. Bridges are most effective when they have considerable knowledge of both sides and can figure out what each one needs. This is why the champagne and spirits distributor Moët Hennessy España hired two enologists, or wine experts, to help coordinate the work of its marketing and sales groups, which had a history of miscommunication and conflict. The enologists could relate to both groups equally: They could speak to marketers about the emotional content (the ephemeral “bouquet”) of brands, while also providing pragmatic salespeople with details on the distinctive features of products they needed to win over retailers. Understanding both worlds, the enologists were able to communicate the rationale for each group’s modus operandi to the other, allowing marketing and sales to work more synergistically even without directly interacting. This kind of cultural brokerage is efficient because it lets disparate parties work around differences without investing in learning the other side’s perspective or changing how they work. It’s especially valuable for one-off collaborations or when the company is under intense time pressure to deliver results.
Employees who can reach outside their silos learn more and sell more.
Adhesives, in contrast, bring people together and help build mutual understanding and lasting relationships. Take one manager we spoke with at National Instruments, a global producer of automated test equipment. He frequently connects colleagues from different regions and functions. “I think of it as building up the relationships between them,” he told us. “If a colleague needs to work with someone in another office or function, I would tell them, ‘OK, here’s the person to call.’ Then I’d take the time to sit down and say, ‘Well, let me tell you a little bit about how these guys work.’” Adhesives facilitate collaboration by vouching for people and helping them decipher one another’s language. Unlike bridges, adhesives develop others’ capacity to work across a boundary in the future without their assistance.
Company leaders can build both bridging and adhesive capabilities in their organizations by hiring people with multifunctional or multicultural backgrounds who have the strong interpersonal skills needed to build rapport with multiple parties. Because it takes resilience to work with people across cultural divides, firms should also look for a growth mindset—the desire to learn and to take on challenges and “stretch” opportunities.
In addition, leaders can develop more brokers by giving people at all levels the chance to move into roles that expose them to multiple parts of the company. This, by the way, is good training for general managers and is what many rotational leadership-development programs aim to accomplish. Claudine Wolfe, the head of talent and development at the global insurer Chubb, maintains that the company’s capacity to serve customers around the world rests on giving top performers opportunities to work in different geographies and cultivate an international mindset. “We give people their critical development experiences steeped in the job, in the region,” she says. “They get coaching in the cultural norms and the language, but then they live it and internalize it. They go to the local bodega, take notice of the products on the shelves, have conversations with the merchant, and learn what it really means to live in that environment.”
Matrix organizational structures, in which people report to two (or more) groups, can also help develop cultural brokers. Despite their inherent challenges (they can be infuriatingly hard to navigate without strong leadership and accountability), matrices get people used to operating at interfaces.
We’re not saying that everyone in your organization needs to be a full-fledged cultural broker. But consciously expanding the ranks of brokers and deploying them to grease the wheels of collaboration can go a long way.
2. Encourage People to Ask the Right Questions
It’s nearly impossible to work across boundaries without asking a lot of questions. Inquiry is critical because what we see and take for granted on one side of an interface is not the same as what people experience on the other side.
Indeed, a study of more than 1,000 middle managers at a large bank that Tiziana conducted with Bill McEvily and Evelyn Zhang of the University of Toronto and Francesca Gino of Harvard Business School highlights the value of inquisitiveness in boundary-crossing work. It showed that managers with high levels of curiosity were more likely to build networks that spanned disconnected parts of the company.
But all of us are vulnerable to forgetting the crucial practice of asking questions as we move up the ladder. High-achieving people in particular frequently fail to wonder what others are seeing. Worse, when we do recognize that we don’t know something, we may avoid asking a question out of (misguided) fear that it will make us look incompetent or weak. “Not asking questions is a big mistake many professionals make,” Norma Kraay, the managing partner of talent for Deloitte Canada, told us. “Expert advisers want to offer a solution. That’s what they’re trained to do.”
Leaders can encourage inquiry in two important ways—and in the process help create an organization where it’s psychologically safe to ask questions.
Be a role model.
When leaders show interest in what others are seeing and thinking by asking questions, it has a stunning effect: It prompts people in their organizations to do the same.
Asking questions also conveys the humility that more and more business leaders and researchers are pointing to as vital to success. According to Laszlo Bock,Google’s former senior vice president of people operations, humble people are better at bringing others together to solve tough problems. In a fast-changing business environment, humility—not to be confused with false modesty—is simply a strength. Its power comes from realism (as in It really is a complex, challenging world out there; if we don’t work together, we don’t stand a chance).
Gino says one way a leader can make employees feel comfortable asking questions is by openly acknowledging when he or she doesn’t know the answer. Another, she says, is by having days in which employees are explicitly encouraged to ask “Why?” “What if…?” and “How might we…?” (See “The Business Case for Curiosity,” HBR, September–October 2018.)
Teach employees the art of inquiry.
Training can help expand the range and frequency of questions employees ask and, according to Hal Gregersen of the MIT Leadership Center, can reinvigorate their sense of curiosity. But some questions are better than others. And if you simply tell people to raise more questions, you might unleash interrogation tactics that inhibit rather than encourage the development of new perspectives. As MIT’s Edgar Schein explains in his book Humble Inquiry,questions are the secret to productive work relationships—but they must be driven by genuine interest in understanding another’s view.
It’s also important to learn how to request information in the least biased way possible. This means asking open-ended questions that minimize preconceptions, rather than yes-or-no questions. For instance, “What do you see as the key opportunity in this space?” will generate a richer dialogue than “Do you think this is the right opportunity to pursue?”
As collaborations move forward, it’s helpful for team leaders or project managers to raise queries that encourage others to dive more deeply into specific issues and express related ideas or experiences. “What do you know about x?” and “Can you explain how that works?” are two examples. These questions are focused but neither limit responses nor invite long discourses that stray too far from the issue at hand.
How you process the answers also matters. It’s natural, as conversations unfold, to assume you understand what’s being said. But what people hear is biased by their expertise and experiences. So it’s important to train people to check whether they’re truly getting their colleagues’ meaning, by using language like “This is what I’m hearing—did I miss anything?” or “Can you help me fill in the gaps?” or “I think what you said means the project is on track. Is that correct?”
Finally, periodic temperature taking is needed to examine the collaborative process itself. The only way to find out how others are experiencing a project or relationship is by asking questions such as “How do you think the project is going?” and “What could we do to work together more effectively?”
3. Get People to See the World Through Others’ Eyes
Leaders shouldn’t just encourage employees to be curious about different groups and ask questions about their thinking and practices; they should also urge their people to actively consider others’ points of view. People from different organizational groups don’t see things the same way. Studies (including research on barriers to successful product innovation that the management professor Deborah Dougherty conducted at Wharton) consistently reveal that this leads to misunderstandings in interface work. It’s vital, therefore, to help people learn how to take the perspectives of others. One of us, Amy, has done research showingthat ambitious cross-industry innovation projects succeed when diverse participants discover how to do this. New Songdo, a project to build a city from scratch in South Korea that launched a decade ago, provides an instructive example. Early in the effort, project leaders brought together architects, engineers, planners, and environmental experts and helped them integrate their expertise in a carefully crafted learning process designed to break down barriers between disciplines. Today, in striking contrast to other “smart” city projects, New Songdo is 50% complete and has 30,000 residents, 33,000 jobs, and emissions that are 70% lower than those of other developments its size.
In a study of jazz bands and Broadway productions, Brian Uzzi of Northwestern University foundthat leaders of successful teams had an unusual ability to assume other people’s viewpoints. These leaders could speak the multiple “languages” of their teammates. Other research has shown that when members of a diverse team proactively take the perspectives of others, it enhances the positive effect of information sharing and increases the team’s creativity.
Creating a culture that fosters this kind of behavior is a senior leadership responsibility. Psychological research suggests that while most people are capable of taking others’ perspectives, they are rarely motivated to do so. Leaders can provide some motivation by emphasizing to their teams how much the integration of diverse expertise enhances new value creation. But a couple of other tactics will help:
Organize cross-silo dialogues.
Instead of holding one-way information sessions, leaders should set up cross-silo discussions that help employees see the world through the eyes of customers or colleagues in other parts of the company. The goal is to get everyone to share knowledge and work on synthesizing that diverse input into new solutions. This happens best in face-to-face meetings that are carefully structured to allow people time to listen to one another’s thinking. Sometimes the process includes customers; one consulting firm we know started to replace traditional meetings, at which the firm conveyed information to clients, with a workshop format designed to explore questions and develop solutions in collaboration with them. The new format gives both the clients and the consultants a chance to learn from each other.
One of the more thoughtful uses of cross-silo dialogue is the “focused event analysis” (FEA) at Children’s Minnesota. In an FEA people from the health system’s different clinical and operational groups come together after a failure, such as the administration of the wrong medication to a patient. One at a time participants offer their take on what happened; the goal is to carefully document multiple perspectives beforetrying to identify a cause. Often participants are surprised to learn how people from other groups saw the incident. The assumption underlying the FEA is that most failures have not one root cause but many. Once the folks involved have a multifunctional picture of the contributing factors, they can alter procedures and systems to prevent similar failures.
Hire for curiosity and empathy.
You can boost your company’s capacity to see the world from different perspectives by bringing on board people who relate to and sympathize with the feelings, thoughts, and attitudes of others. Southwest Airlines, which hires fewer than 2% of all applicants,selects people with empathy and enthusiasm for customer service, evaluating them through behavioral interviews (“Tell me about a time when…”) and team interviews in which candidates are observed interacting.
4. Broaden Your Employees’ Vision
You can’t lead at the interfaces if you don’t know where they are. Yet many organizations unwittingly encourage employees to never look beyond their own immediate environment, such as their function or business unit, and as a result miss out on potential insights employees could get if they scanned more-distant networks. Here are some ways that leaders can create opportunities for employees to widen their horizons, both within the company and beyond it:
Bring employees from diverse groups together on initiatives.
As a rule, cross-functional teams give people across silos a chance to identify various kinds of expertise within their organization, map how they’re connected or disconnected, and see how the internal knowledge network can be linked to enable valuable collaboration.
At one global consulting firm, the leader of the digital health-care practice used to have its consultants speak just to clients’ CIOs and CTOs. But she realized that that “unnecessarily limited the practice’s ability to identify opportunities to serve clients beyond IT,” she says. So she began to set up sessions with the entire C-suite at clients and brought in consultants from across all her firm’s health-care practices—including systems redesign, operations excellence, strategy, and financing—to provide a more integrated look at the firm’s health-care innovation expertise.
Those meetings allowed the consultants to discover the connections among the practices in the health-care division, identify the people best positioned to bridge the different practices, and see novel ways to combine the firm’s various kinds of expertise to meet clients’ needs. That helped the consultants spot value-generating opportunities for services at the interfaces between the practices. The new approach was so effective that, in short order, the leader was asked to head up a new practice that served as an interface across all the practices in the IT division so that she could replicate her success in other parts of the firm.
Urge employees to explore distant networks.
Employees also need to be pushed to tap into expertise outside the company and even outside the industry. The domains of human knowledge span science, technology, business, geography, politics, history, the arts, the humanities, and beyond, and any interface between them could hold new business opportunities. Consider the work of the innovation consultancy IDEO. By bringing design techniques from technology, science, and the arts to business, it has been able to create revolutionary products, like the first Apple mouse (which it developed from a Xerox PARC prototype into a commercial offering), and help companies in many industries embrace design thinking as an innovation strategy.
The tricky part is finding the domains most relevant to key business goals. Although many innovations have stemmed from what Abraham Flexner, the founding director of the Institute for Advanced Study, called “the usefulness of useless knowledge,”businesses can ill afford to rely on open-ended exploratory search alone. To avoid this fate, leaders can take one of two approaches:
A top-down approach works when the knowledge domains with high potential for value creation have already been identified. For example, a partner in an accounting firm who sees machine learning as key to the profession’s future might have an interested consultant or analyst in her practice take online courses or attend industry conferences about the technology and ask that person to come back with ideas about its implications. The partner might organize workshops in which the junior employee shares takeaways from the learning experiences and brainstorms, with experienced colleagues, potential applications in the firm.
You can’t lead at the interfaces if you don’t know where they are.
A bottom-up approach is better when leaders have trouble determining which outside domains the organization should connect with—a growing challenge given the speed at which new knowledge is being created. Increasingly, leaders must rely on employees to identify and forge connections with far-flung domains. One approach is to crowdsource ideas for promising interfaces—for example, by inviting employees to propose conferences in other industries they’d like to attend, courses on new skill sets they’d like to take, or domain experts they’d like to bring in for workshops. It’s also critical to give employees the time and resources to scan external domains and build connections to them.
Breaking Down Silos
In today’s economy everyone knows that finding new ways to combine an organization’s diverse knowledge is a winning strategy for creating lasting value. But it doesn’t happen unless employees have the opportunities and tools to work together productively across silos. To unleash the potential of horizontal collaboration, leaders must equip people to learn and to relate to one another across cultural and logistical divides. The four practices we’ve just described can help.
Not only is each one useful on its own in tackling the distinct challenges of interface work, but together these practices are mutually enhancing: Engaging in one promotes competency in another. Deploying cultural brokers who build connections across groups gets people to ask questions and learn what employees in other groups are thinking. When people start asking better questions, they’re immediately better positioned to understand others’ perspectives and challenges. Seeing things from someone else’s perspective—walking in his or her moccasins—in turn makes it easier to detect more pockets of knowledge. And network scanning illuminates interfaces where cultural brokers might be able to help groups collaborate effectively.
Over time these practices—none of which require advanced degrees or deep technical smarts—dissolve the barriers that make boundary-crossing work so difficult. When leaders create conditions that encourage and support these practices, collaboration across the interface will ultimately become second nature.
How to Ask Good Questions
COMMON PITFALLSEFFECTIVE INQUIRYStart with yes-or-no questions.Start with open-ended questions that minimize preconceptions. (“How are things going on your end?” “What does your group see as the key opportunity in this space?”)Continue asking overly general questions (“What’s on your mind?”) that may invite long off-point responses.As collaborations develop, ask questions that focus on specific issues but allow people plenty of room to elaborate. (“What do you know about x?” “Can you explain how that works?”)Assume that you’ve grasped what speakers intended.Check your understanding by summarizing what you’re hearing and asking explicitly for corrections or missing elements. (“Does that sound right—am I missing anything?” “Can you help me fill in the gaps?”)Assume the collaboration process will take care of itself.Periodically take time to inquire into others’ experiences of the process or relationship. (“How do you think the project is going?” “What could we do to work together more effectively?”)
Sujin Jang is an assistant professor of organisational behaviour at INSEAD. Her research focuses on global teams and the challenges of working across cultures.