Clara Holoscan MGX Medical-Grade Platform With NVIDIA Orin and NVIDIA AI Software Stack Powers Systems Built by Embedded-Computing Leaders
GTC—NVIDIA today introduced Clara Holoscan MGX™, a platform for the medical device industry to develop and deploy real-time AI applications at the edge, specifically designed to meet required regulatory standards.
Clara Holoscan MGX expands the Clara Holoscan platform to provide an all-in-one, medical-grade reference architecture, as well as long-term software support, to accelerate innovation in the medical device industry. It brings a new level of sensor innovation to edge computing by processing high-throughput data streams for real-time insights. From robotic surgery to studying new approaches to biology, surgeons and scientists need medical devices to evolve into continuous sensing systems to research and treat disease.
“Deploying real-time AI in healthcare and life sciences is critical to enable the next frontiers in surgery, diagnostics and drug discovery,” said Kimberly Powell, vice president of healthcare at NVIDIA. “Clara Holoscan MGX, with its unique combination of AI, accelerated computing and advanced visualization, accelerates the productization of AI and provides software-as-a-service business models for the medical device industry.”
As part of Clara Holoscan MGX, NVIDIA provides hardware reference design with long-life NVIDIA components and 10-year long-term software support, including IEC62304 documentation for software and IEC60601 attestation reports from embedded computing partners.
Some of the largest medical devices makers and dozens of robotic surgery and medical imaging startups are already developing on the Clara Holoscan platform.
Product Specifications Clara Holoscan MGX brings together the high-performance NVIDIA Jetson AGX Orin™ Industrial module, NVIDIA RTX™ A6000 GPU and NVIDIA ConnectX-7®SmartNIC network adapter into a scalable AI platform providing up to 254-619 trillion operations per second of AI performance.
For high-throughput instruments, ConnectX-7 provides up to 200 GbE bandwidth and a GPUDirect® RDMA path to GPU processing, which helps enable faster processing. It also integrates the latest in embedded security with a safety and security module, consisting of controllers to monitor critical operations, provide remote software updates and system recovery, and hardware root of trust to provide state-of-the-art embedded security.
Medical device makers can directly embed Clara Holoscan MGX or connect to the existing install base of medical devices, which allows developers to accelerate AI deployment and regulatory clearance.
The Clara Holoscan SDK is specifically designed for high-performance streaming applications to build the next generation of software-defined instruments. It brings together pretrained models, as well as a framework for scalable microservices, to allow applications to be managed and deployed both on device and on the edge data center, ushering in the software-as-a-service business model for the industry.
Clara Holoscan extends from medical devices to NVIDIA edge servers to NVIDIA DGX™ systems in the cloud or the data center.
WASHINGTON — A hefty workload and other procurement factors have delayed awards for the Pentagon’s latest enterprise cloud effort, known as the Joint Warfighting Cloud Capability.
Contracts for the follow-up to the Defense Department’s infamous JEDI venture are now expected at the end of the year, not April as originally advertised, according to Chief Information Officer John Sherman.
“As we’ve gotten into this and leaned into it with four vendors, we recognized that our schedule was maybe a little too ahead of what we thought, and that now we’re going to wrap up in the fall. And we’re aiming to award in December,” Sherman said during a March 29 briefing.
Sherman also revealed that JWCC could be worth up to $9 billion.
“This was not a guess. This was based on actual workflows and anticipated workloads to the cloud,” Sherman explained. “But that’s why we came up with this $9 billion ceiling. And that’s not a guaranteed amount by any stretch. It is just that, a ceiling.”
Proposals are under review. The Defense Department approached Amazon, Google, Microsoft and Oracle last year. Officials said talks between government and vendors have been substantial and positive. Sherman would not say if he expected fewer than four deals to be made, citing procurement sensitivities.
The decision to push things back was made in recent weeks, as the scope of what still had to be accomplished came into focus.
“It’s just going to take us a little bit longer than we thought,” said Sherman, who emphasized that things were going well. “And, from my CIO seat, I’ve told the team we’re going to make sure we do this right, take the time that they need, so we can stick the landing on this, given the imperative of what JWCC is for the Department of Defense.”
The Joint Warfighting Cloud Capability is meant to plug a hole in the Pentagon’s cloud powers, spanning unclassified, secret and top-secret classifications and stretching to the military’s farthest edge.
“Nothing in the department meets this requirement at the current time, what I just described to you,” Sherman said.
Initial JWCC contracts will comprise a three-year base with one-year options, according to the chief information officer. A “full and open” competition for a future multi-cloud environmentwill follow, he added.
The Defense Department axed JWCC’s predecessor, JEDI, or Joint Enterprise Defense Infrastructure, in 2021 after years of delays. The potential $10 billion program was plagued by legal challenges and allegations of political interference.
“JEDI, conceived with noble intent and a baseline now several years old, was developed at a time when the department’s needs were different and our cloud conversancy less mature,” Sherman said in a statementat the time. “The JWCC’s multi-cloud environment will serve our future in a way that JEDI’s single award, single cloud structure simply cannot do.”
Colin Demarest is a reporter at C4ISRNET, where he covers networks and IT. Colin previously covered the Department of Energy and its National Nuclear Security Administration — namely nuclear weapons development and Cold War cleanup — for a daily newspaper in South Carolina.
Most government digital service projects don’t need to scale to 100 million users per hour – but some do.
Kessel Run’s Bowcaster team recently provided Chaos Engineering services to GSA in order to help their Technology Transformation Services (TTS) cloud.gov ( Technology team scale its capacity from 50,000 to 100 million users an hour.
Press Release
BOSTON (30 March 2022) – Today, Kessel Run and the U.S. General Services Administration’s Technology Transformation Services (TTS) unveiled a collaboration that developed a capability able to host 100 million digital users an hour.
The successful partnership is a proof of concept for future website development. The government-wide approach demonstrates how federal agencies can come together to improve customer experience and enhance digital capabilities for the benefit of the public.
“This is a great example of an interagency collaboration yielding concrete, scalable results and governmentwide benefits,” said Dave Zvenyach, TTS Director. “The capability developed as a result of this partnership is another milestone in our efforts to improve digital service delivery and ensure an effective, equitable, and secure digital infrastructure for the public.”
TTS’ cloud.gov team built and maintains a shared platform that can support large spikes in usage, and offers an easy and efficient way for agencies to manage their digital solutions. Kessel Run’s Bowcaster team provided “Chaos Engineering” services to help cloud.gov scale its capacity to 100 million post requests an hour. Bowcaster provided load testing, penetration testing, and other services that helped ensure the cloud.gov platform could meet availability and resiliency requirements needed to highly trafficked applications as it was scaled up.
“Although typically government websites host thousands to tens of thousands of users an hour, cloud.gov is built to scale, allowing for increased seasonal demand or emergency needs,” said Lindsay Young, Acting Director of Cloud.gov. “This means any government agency can be ready for a surge or need that would amount to up to 100 million users/hour.”
“From a reliability and resilience perspective, we wanted to push the system to the limit, so we tossed everything including the kitchen sink at it,” said Omar Marrero, the Chaos and Performance Tech Lead, and Deputy Test Chief with Kessel Run. “Based on those steps they were able to re-architect their deployment to handle a surge, until we got to the point where we were able to blast it with the 100 million users without any issues.”
The collaboration took place over the course of 10 days, with all participants working remotely. This highlights both the speed and versatility agencies can achieve by working together.
“We can collaborate together and deliver these sorts of capabilities from anywhere,” said Marrero. “We proved that over the course of ten days helping cloud.gov develop this capability.”
TTS applies modern methodologies and technologies to improve the lives of the public and public servants. This includes use of cloud.gov—an easy to use cloud hosting platform—as a service for hosting mission critical agency applications. Air Force Life Cycle Management Center, Detachment 12, also known as Kessel Run, has a proven track record in enhancing efficiency, saving cost, and modernizing the way the Air Force operates with its agile software development. With its user-centered approach to development, Kessel Run’s mission is to rapidly deliver combat capabilities to warfighters and revolutionize the Air Force software acquisition process.
“We can build the high-quality government services the American People deserve,” said Col. Brian Beachkofski, the Commander of Kessel Run. “By working together, the government can deliver high-quality services at the speed of need.”Air Force Life Cycle Management Center Detachment 12, Kessel Run Media and Communications Engagement
Selling hardware without software is unthinkable in most industries. In recent years, systems that combine hardware and software—that is, embedded systems—have become more complex because they rely on other systems themselves. In this system-of-systems approach, the number of interfaces tends to explode—clear evidence for rising system complexity. A 360-degree perspective on managing complexity can help companies avoid falling into the complexity trap and eventually master complexity.
1. Falling into the complexity trap
As the complexity of systems increases, complexity—that is, dealing with complexity and potentially resolving it—becomes a growing concern. Even with the best intentions, embedded systems can become so complex that their development becomes increasingly risky and prone to delays. To show how organizations can navigate this process, we start with a short perspective on embedded systems and their importance before diving into the root causes of complexity and how to manage it.
The growing importance of embedded systems
An embedded system combines both hardware and software. The use of embedded systems has long been established across industries such as aerospace, automotive, industrial machinery, and consumer electronics. However, recent developments—for example, automation, connectivity, analytics, and the Internet of Things—have moved embedded systems to the center of attention within these industries. To achieve the functionality these new developments require, multiple systems must interact precisely with one another. The key to this interaction usually lies within the software part of an embedded system.
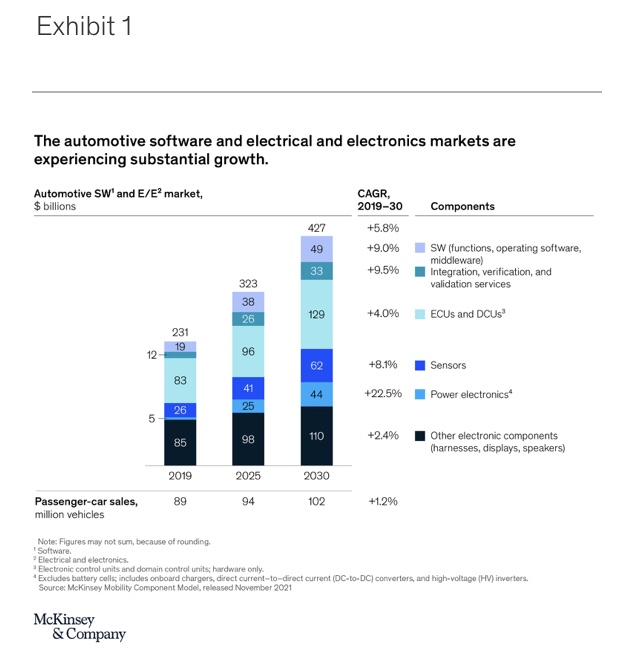
For example, in the automotive industry, embedded software has been used since at least the introduction of the antilock braking system (ABS). Today, automotive embedded software is already a multibillion-dollar market,1 with expected growth rates of roughly 9 percent until 2030 (Exhibit 1). Embedded software is being used in advanced driver-assistance systems (ADAS) and automated driving (AD). In-vehicle infotainment systems are also inconceivable without the use of embedded software.
In the aerospace and defense industry, fly-by-wire systems that automatically control flight operations have been available for decades. Recently, however, system-of-systems approaches have required the coordinated interaction of manned and unmanned aircraft in potentially hazardous situations, dramatically increasing the importance of embedded systems.
The machinery and tools industry is also moving from deterministically controlled systems to creating automated smart tools that are self-optimizing in a closed-loop approach. Embedded software is at the heart of enabling these critical features, too.
From a technical perspective, “embedded systems” refers to the integration of software components, computer hardware, sensors, and actuators into a larger mechanical and electronic system. These systems constitute an active chain in which sensors collect external signals that are processed by control units, which then cause actuators to behave in line with the system’s operating purpose.
Rising complexity within embedded systems
To understand the relevance of complexity in embedded systems, one must first consider complexity drivers. Quite generically, tight integration between individual features of a system drives complexity. Tight integration often entails a large number of interdependencies, which can tremendously complicate embedded system development and maintenance. The following is a nonexhaustive list of drivers of complexity in embedded systems:
Operational domain and standards or regulation.Embedded systems usually interact directly with the real world by processing sensor data and turning the results into action via actuators. This leads to strict requirements within an embedded system’s operational domain, such as combined real-time and event-driven functionality, safety, reliability, and longevity. Safety and realiability requirements specifically are enforced by regulation and other industry standards (for example, IEC 61508 for functional safety in general or DO 178 and ISO 26262 for safety in aerospace and automotive industries, respectively). To meet these standards, systems may become more complex than they were originally designed to be.
Increased automation. The trend toward increased automation leads to a growing need for modern technologies such as machine learning and closed-loop control. These technologies require data from multiple parts of a system to be processed and then combined in one overarching target function, such as predicting maintenance needs in manufacturing systems or optimizing process performance. More automation can necessitate more complexity.
Rising connectivity. The connectivity trend means that embedded systems are increasingly able to exchange data with their environment. This has multiple implications. First, cybersecurity becomes mandatory, whether for control systems in industrial automation or for the automotive industry, where it is enforced via the UNECE regulation. Second, the availability of remote access and updating means that the underlying software that enables these services needs to able to deal with any system configuration available in the field. These requirements may lead to an increased level of embedded system complexity if not managed properly.
Hardware and software compatibility. In embedded systems, hardware and software development needs to be synchronized. This entails several complications. One is that a certain maturity of electronics hardware is required for software development to be meaningful. This can be circumvented via virtualization—in other words, the use of model-in-the-loop (MiL), software-in-the-loop (SiL), or virtual hardware-in-the-loop (vHiL) techniques. However, virtualization itself poses additional complications for the toolchain, such as the need for hypervisors and a fine-grained configuration of security and permission aspects—that is, the need to implement, configure, and maintain the required HiL, SiL, and MiL environment—to reap its full benefits. Another complication is that the two major development paradigms (waterfall development for hardware and agile for software) need to be combined in modern systems engineering. This combination encompasses processes, methods, tools, and organizational structures, which can prove complex and challenging, because many organizations are still new to these kind of paradigms on a broader scope.
Constraints on implementation.The development of embedded systems is subject to multiple constraints. These include technical constraints—such as energy supply, physical space, signal round-trip times, and computing and memory capacity—as well as business constraints, such as cost. These drive complexity because embedded systems need to deliver functionality to customers while staying within the bounds of these requirements.
The biggest problem in the development and maintenance of large-scale software systems is complexity—large systems are hard to understand.
Peter Marks and Ben Moseley (Out of the tar pit, 2006)
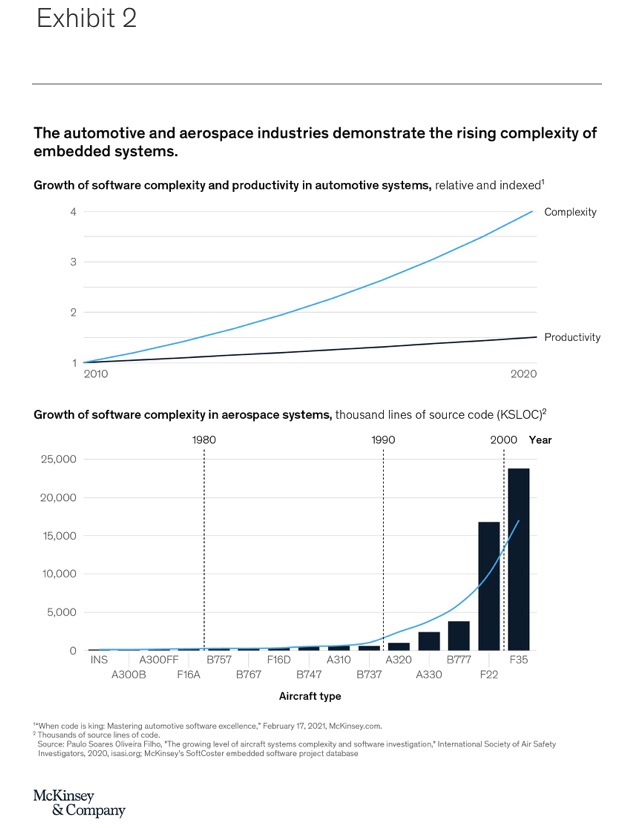
The software and electronic architecture of modern cars provides a good example of the rising complexity of embedded systems. A typical car has about 100 control units, thousands of software components, and tens of thousands of signals exchanged between subsystems. All of these need to be designed, developed, integrated, tested, and validated to work individually as well as in conjunction with each other. The average complexity of individual software projects in the automotive industry has grown by 300 percent over the past decade (Exhibit 2).
A similar trajectory can be seen in other industries, such as aerospace. The number of lines of code embedded in aircraft over the past decades has risen dramatically, another indicator of growing complexity. This growth is likely to accelerate amid rising demands for more complex functionality and for increased flexibility to update software as needed.
Failing to deal appropriately with complexity—with potentially disastrous effects
Sidebar
Defining complexity
In the following, the three dimensions of complexity are defined. We use the analogy of mountaineering or mountain climbing as a means to illustrate those dimensions. This analogy helps with making the dimensions more memorable and facilitating further discussions. The exhibit below illustrates this analogy graphically.
Environmental complexityrefers to the complexity that a specific environment imposes on the embedded system’s task. It is similar to what is called “essential complexity” in software engineering—that is, the complexity that is essential to the task being solved—which is why it is treated here as externally “given” for a specific embedded-system-development project. Environmental complexity can be very high, as is the case for vehicles capable of highly automated driving. They must be able to handle such a large number of varied real-world scenarios that it is impossible to provide concrete instructions to solve every single one separately.
In comparison, environment complexity for the control system of a tram on a track is relatively low. This is because the tram’s environment is largely determined by the track itself—the length of straight and curved segments, railroad signals, and so on. Within this environment, trams have only limited freedom of movement, greatly limiting potential movement scenarios.
In the mountaineering analogy, environmental complexity is represented by the total height of the mountain. It is a fixed variable that determines the overall difficulty of the project.
System complexity refers to how many elements of a given environment a system must respond to and how complex the system itself must be.
System complexity is largely driven by two elements. The first element is the operational design domain (ODD), which is the scope of environmental complexity to be addressed by the system. For example, in the case of automated driving, the ODD, and therefore the scope of the functionality, can be restricted to sunny weather. This reduces system complexity because the system will not have to deal with limited visibility from heavy rain or fog.
The second element is the system design: the design choices within the system architecture, the technical solutions used to build certain functionalities, and the use of standards. For example, an advanced driver-assistance system could use only cameras, or it could use a combination of multiple sensor types, such as cameras, light detection and ranging (LiDAR) devices, and radar. In software engineering, system complexity beyond what is absolutely necessary is usually referred to as accidental complexity—the complexity that is unintentionally added to the project. This is often due to conscious and unconscious choices made by the system development team. Therefore, unlike environmental complexity, system complexity is never a given, so it can be minimized via smart design choices.
To continue the mountaineering analogy, system complexity could be likened to the path chosen to reach a certain destination on the mountain. Choosing a specific destination on the mountain, whether the peak or elsewhere, is similar to limiting the operational design domain. Then, to reach the chosen destination, it is possible to follow different routes, some of them more challenging than others. This is analogous to system design choices leading to lower or higher levels of complexity.
The ability to cope with complexity relates to a company’s internal capability of effectively and efficiently handling a given level of system complexity. This capability depends on the functionality of a company’s processes, methods, and tools, as well as on its organization. Well-performing companies are those that, for example, use tools that create in-depth transparency regarding embedded systems, ensure end-to-end traceability of requirements, and enable prototype-free testing.
A company’s ability to cope with a given level of system complexity can be compared with the quality of a team of mountaineers attempting to climb a mountain: their level of training (methods), their ability to function as a team (organization and way of working), and the effectiveness of their gear (tools) all play a part in determining whether or not they will be effective and efficient in reaching their goal.
Examples from the media provide plenty of accounts of the detrimental results of improperly managed complexity. These include launch delays of several months, costly recalls, enormous budget overruns, dissatisfied customers, and even safety issues. It has been estimated that a one-month delay in start of production (SOP) in the automotive industry can result in a loss of more than €100 million in earnings before interest and taxes (EBIT) for the largest OEMs. At the same time, research-and-development-budget overruns of 30 to 50 percent are not uncommon.
To understand why companies fail to properly manage complexity, leaders need to consider the following three dimensions of holistic complexity management: environmental complexity, system complexity, and the ability to cope with complexity (see sidebar “Defining complexity”).
Dimensions of complexity
Environmental complexity is determined by the environment in which the embedded system is to fulfill its tasks. If, for example, the task is to create a system for fly-by-wire operations for an airplane, the physical conditions of the airspace, air traffic participants and their behaviors, and the unchangeable parts of airport infrastructure are all drivers of environmental complexity. Environmental complexity is a boundary condition. Hence, system complexity and the ability to cope with complexity are the two key parameters that companies need to focus on in complexity management, as both can be changed.
System complexity is caused first by the operational design domain (ODD) and second by a system’s design. The ODD refers to the scope of the environmental issues that the system is to address. Companies often fail to put sufficient effort and thought into truly understanding the operational design domain of the problem that an embedded system is supposed to solve. The choice of an ODD is often made without a full consideration of its system-complexity implications. Taking the example of automated driving, complexity may be low if the ODD only includes sunny weather conditions. If the ODD were to include all kinds of weather conditions, the direct implications for required sensor sets and data-processing needs would likely increase system complexity.
The second cause of system complexity is system design. System design is about defining and building a system structure that is best suited to the tasks to be solved. Misguided system-design choices may lead to a highly complex architecture. In turn, this high complexity can make it impossible to implement important features such as over-the-air upgradability. For example, in automotive, historically the software and electronics architecture of vehicles used one function per control unit. With increasing interconnectedness of features, such a highly distributed architecture would render over-the-air updates nearly impossible. The root cause for misguided architecture design choices is often a lack of clear guidelines and priorities regarding what the architecture is expected to achieve.
An organization’s inability to cope with complexity is likely to have detrimental effects on embedded system development. This inability can stem from inappropriate or inefficient processes, methods, and tools—or even structural flaws within the organization itself. Symptoms of such an inability are evident when, for example, the interconnectedness of components is not properly reflected in the system’s setup or in the ways of working along the development process. Other symptoms are when simple spreadsheets are used to map the dependencies of highly complex systems or when static slides are used to represent system architectures. This can result in issues along the entire development process. For example, system integration can fail if component interdependencies become extremely complex or if proper tooling is not available. At the core of this inability to cope with complexity is usually a company’s unwillingness to pay—or even to acknowledge—the technical debt that often emerges when developing increasingly complex embedded systems.
Assessing a company’s ability to manage complexity
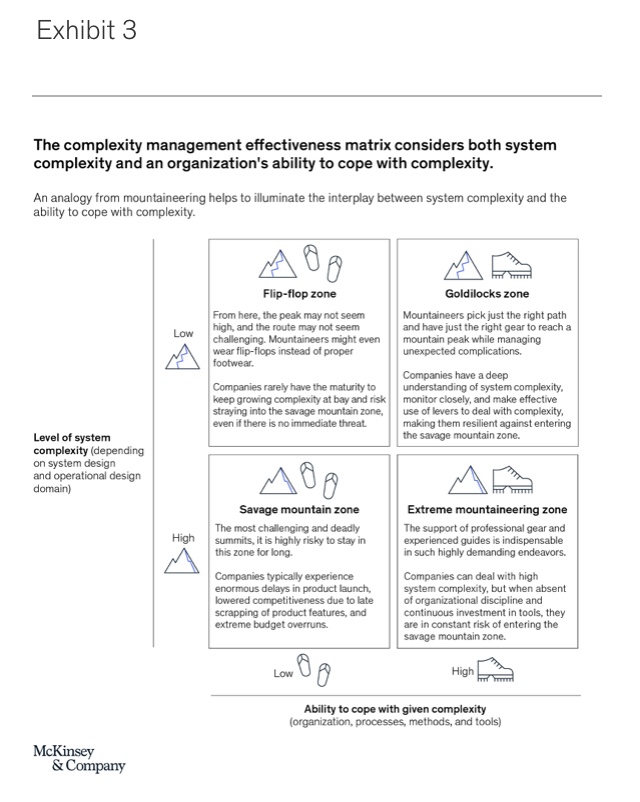
System complexity and the ability to cope with complexity are the two dimensions of complexity that a company can influence and, hence, are of key importance. In contrast, environmental complexity is considered a given. When taking these factors into account, one can derive what we have termed “the complexity management effectiveness matrix,” which provides a quick way to determine a company’s ability to manage complexity and, from there, to plan next steps (Exhibit 3).
System complexity is shown on the vertical axis, and the ability to cope with complexity is shown on the horizontal axis. For the sake of simplicity, the complexity management effectiveness matrix is separated into four zones whose names are based on a mountaineering analogy (see sidebar “Defining complexity”).
Savage mountain zone (high level of system complexity, low ability to cope with given complexity): The savage mountain is a nickname for K2, the second-highest mountain on Earth and one of the most challenging and deadly summits in the world. It is highly risky to stay in this zone for long. If we map this metaphor onto embedded system development, system complexity—the developer’s chosen path and destination—is high due to very demanding functional requirements with a poor implementation concept, a high number of variants, bad architecture choices, and so on. At the same time, a company’s ability to cope with complexity via its organizational structure, processes, methods, and tools is too low for successful project execution. This can be due to tools without automated interfaces, a lack of discipline regarding continuous critical-path analysis and debottlenecking, or bad choices on suppliers of software and traditionally hardware-focused players solely based on the individual component cost without taking a larger, long-term perspective into consideration. In the savage mountain zone, companies typically experience enormous delays in product launch, lowered competitiveness due to late scrapping of product features, and extreme budget overruns.
Extreme mountaineering zone(high level of system complexity, high ability to cope with given complexity): The support of professional mountain guides is indispensable for people attempting mountaineering in the extreme conditions of the highest mountains. These guides are the backbone of success in such highly demanding endeavors. A similar trend becomes apparent when we consider embedded system development. In the extreme mountaineering zone of development, system complexity is high, often because the problem to be solved is very complex, such as in autonomous-vehicle development, yet architecture choices may be suboptimal. To compensate, companies in this zone have built proper processes, methods, tools, and organizational structures that support their ability to deal with the intricacies of their embedded systems in an appropriate way. They have paid their technical debt sufficiently early by installing the proper processes and methods in their organization—for example, by investing in a state-of-the-art toolchain or by modeling software-function interdependencies across the entire stack. Companies in the extreme mountaineering zone have found the means necessary to survive in a high-system-complexity situation—but at high cost. They also run the constant risk of transgressing into the savage mountain zone when high organizational discipline and continuous investment in tools and talent are not secured.
Flip-flop zone (low level of system complexity, low ability to cope with given complexity): At the foot of the mountain, the peak may not seem high, and the path toward it may not seem challenging. In this situation, mountaineers might dare to ascend with limited gear, possibly even wearing flip-flops instead of proper footwear. In this combination, accidents occur, and reports of hikers found in dire situations are not uncommon. Likewise, in embedded system development, it is easy to fall for the misconception that when system complexity is low—for example, when following standard, well-working architecture approaches—investment in proper processes, methods, and tools, along with organizational measures, is not crucial. However, given the trends of increasingly demanding system requirements and growing system interconnectedness, this approach will only work in the short term—if at all. Companies in this zone rarely have the maturity to keep growing complexity at bay and therefore risk straying into the savage mountain zone, even if there is no immediately apparent threat.
Goldilocks zone (low level of system complexity, high ability to cope with given complexity): Ideally, mountaineers pick just the right path to a mountain peak and tackle it with just the right gear that will allow them to safely and efficiently reach their desired destination while managing unexpected complications. In the Goldilocks zone of complexity management effectiveness, companies benefit from both a consciously limited system complexity and a high ability to cope with almost any level of complexity. This makes companies in the Goldilocks zone unlikely to enter the savage mountain zone. They have a deep understanding of system complexity drivers, monitor them closely, and make effective use of levers to keep system complexity low. What’s more, their organization, processes, methods, and tools give them the flexibility to deal with current and future system complexity.
The complexity management effectiveness matrix can be used for an initial assessment of a company’s ability to manage complexity for a given embedded system project. For a more thorough assessment, companies need to apply a complexity management effectiveness diagnostic.
Additional risks for companies with a traditional hardware-product perspective
The risk of falling into the complexity trap of embedded system development is high when overconfidence in one’s own abilities is paired with immaturity. Companies with a strong history of successfully developing and delivering hardware-focused products are prone to this pitfall. They tend to have tailored processes and world-class engineering teams able to develop very complex hardware products at the highest quality. From a pure hardware-development perspective, these companies are either in the Goldilocks zone or in the extreme mountaineering zone. This may convince them that they are able to develop virtually anything—even beyond hardware. Especially if these companies have had early successes in the development of simple embedded systems, their immaturity may be concealed.
Such companies tend to apply similar processes and management methods to embedded system development as they do to hardware development. Companies fall into the complexity trap not only because of challenges within the embedded system development process but also because of adjacent functions and the mindset, culture, and capabilities of the involved organizational units.
Complexity traps in embedded system development come in many shapes and sizes. Common examples include the following:
The company’s organization is optimized for a different product. The established product-development organization is structured around hardware components rather than around systems and their interdependencies. This setup limits development efficiency—for example, in integration and bug-fixing—if organizational units with responsibility for subsystems that technologically have tight linkages do not collaborate closely. Worse, it may also lead to inferior system design.
Misguided mindset. The mindset that task forces can solve any problem, even in the late-development stage, may have proved successful in classical, mechanical systems-focused development. However, in embedded-system-development efforts, the same “more people, more pressure” mindset may prove disastrous. Especially architecture-related design choices made early in the development process cannot be revoked due to the great number of interdependencies among software and hardware systems and subsystems. After a certain point, starting from scratch or living with the consequences of subpar architecture design may prove to be the only option.
Improper development technology and processes.Engineering IT systems and toolchains are designed for hardware-centric development processes. Simply adding a software-development toolchain without proper integration is usually insufficient because hardware and software are closely interlinked in embedded systems. Hardware-centric toolchains are mostly not suited to deal with embedded-system-specific demands, such as handling tens of thousands of interdependencies, software versioning, and end-to-end requirements traceability.
Myopia in supplier selection.Suppliers are selected purely on cost, rather than on their own maturity in complexity management as measured, for example, by their history of providing high-quality complex subsystems on time. There also may be overreliance on suppliers, which may cause or be caused by company capabilities in embedded system development, integration, and testing that are too limited to handle these activities appropriately.
Poorly adjusted finance methodologies. Financial steering of product development may be optimized for hardware development. When the same methods are transferred to embedded systems, the impact is often negative. For example, hardware-focused financial steering often lacks a total-cost-of-ownership (TCO) perspective. Instead, short-term cost savings are typically encouraged, even when the solution requires a long-term cost perspective that incorporates the cost impact of continuously maintaining and updating a potentially complex system architecture. Another example is optimization of direct cost, which is more easily measured but is not able to capture the full extent of development costs and system complexity. This typically results in additional system variants based on components that are cheaper but that perform worse, thus raising system complexity. In addition, the potential benefits of providing functions on demand, which would require components with better performance, are not sufficiently considered.
Marketability over engineerability. Sales departments often ask for a large set of system variants to cater to the needs of various customer segments and to remain competitive. However, this is done without paying attention to the additional effort required for development, integration, or testing of one more variant. In the worst case, adding more system variants causes product launches to be delayed by months or even years, decreasing customer satisfaction and competitiveness.
In this chapter, we have seen different forms of complexity and described their related analogy in mountaineering to better grasp the way they manifest in practice and their impact. Let us now turn to the question of how one may deal with them in the best manner, having identified their origin.
2. How to escape the complexity trap
Sidebar
Four strategies for managing complexity
Avoid. Avoiding complexity refers to preventing complexity from the start of embedded system development, as well as to limiting the introduction of additional complexity during development. This can include taking a design-simplicity approach or restricting the operational design domain in a minimum-viable-product (MVP) approach.
Reduce and drop. In a reduce-and-drop strategy, companies deliberately remove complexity—either from an embedded system already in development or from the processes, methods, tools, and organization itself. For example, companies can reduce the scope of a project, remove architecture variants, standardize hardware and software (HW/SW) and development toolchains, and remove organizational interfaces.
Contain and delegate. The contain-and-delegate strategy begins with separating a particularly complex subsystem from the rest of the system to limit interference. Development of that subsystem can then be delegated to a different entity that is better suited to develop it. For instance, a company could build a wrapper around a subsystem and then task a specialized supplier that has a strong track record with its development.
Monitor and manage. In the monitor-and-manage approach, a company does not change the current level of complexity but rather deals with it in the most efficient way. This means monitoring any expected changes in complexity so as to trigger appropriate application of the other three strategies. It also means managing unavoidable or irreducible complexity—for example, by using appropriate tools.
As discussed previously, complexity in embedded system development is undoubtedly increasing. Hence, the question arises of which strategies are most effective to escape the complexity trap and move to the Goldilocks zone. Generally, there are four strategies for managing complexity effectively: avoid, reduce and drop, contain and delegate, and monitor and manage (see sidebar “Four strategies for managing complexity”).
Strategies for complexity management
For each of the four complexity management strategies, different levers can be identified. In the following, we review key levers and provide examples.
Avoid
System complexity can be avoided by preventing it from the start of an embedded system development project and by ensuring it does not grow further during development. System complexity can be prevented from the start by picking a proper operational design domain that balances complexity with the fulfillment of customer requirements. It is also critical to assess the long-term impact of each design choice on system complexity. Often, this involves architectural considerations such as the use of specific hardware platforms, processor architectures, hardware and software (HW/SW) standardization, modularization and microservices, and the level of distribution of functionality across the logical architecture.
Complexity can also be avoided by using the proper methods, tools, and organizational setup from the start of embedded system development. From a methods and tool perspective, one can avoid complexity by using domain-driven design, enforcing a ubiquitous language, setting proper design guidelines for systems and components, avoiding the use of different tools for the same purpose, and applying agile principles.
This last point—applying agile principles—can help not only in development but also in customer experience. For example, early on, one can jointly iterate customer requirements with customers. This may allow customers to let go of some of their requirements—ideally, those that do not add much value from a customer perspective but that greatly drive complexity.
Standardization of tools, tool interfaces, and data models may also be employed to avoid complexity. From an organizational perspective, complexity can be avoided by designing the organization around systems that are strongly coupled with each other to drive efficient interactions and aligned development objectives. Organizational complexity can also be avoided by designing processes around supplier interaction such that they foster efficient collaboration.
Intuitively, it is clear that the described levers work well in a greenfield setting with many degrees of freedom. Even in brownfield settings—when embedded system development has progressed significantly, the current project needs to build upon a previous project, or organizational setup and tools are predefined—the avoidance strategy can be applied to limit complexity from growing further. In this case, the avoidance strategy needs to go hand in hand with the reduce-and-drop strategy (see below). For example, when standardization is applied to avoid further complexity growth, existing software code often needs to be refactored so that the standard is applied consistently.
Reduce and drop
In the reduce-and-drop strategy, typical levers that address system complexity are the following: reduction of variants, use of standards, reuse of code, and dropping of requirements that strongly drive complexity. Reduction of hardware variants is a powerful lever since each additional variant drives complexity and effort for development, integration, and testing. Hardware variants are often introduced to capture specific regional requirements or to technically separate high-end and low-end functionality to reduce material cost. Software variants, on the other hand, may represent a suitable means for achieving functional differentiation without raising complexity if functional decoupling is achieved or if variance can be achieved by flag-based deactivation of certain parts of a fully fleshed-out code base.
Standardization reduces complexity because it enables a common architecture and interfaces that foster code reuse and faster localization and fixing of errors. Standardization can either refer to internal standardization—for example, by choosing a standard for communication—or to externally defined standards that are shared across many players in the same industry. But when external standards are used, they need to be suitable for the task at hand to prevent the introduction of further complexity (for example, by avoiding the application of a rather heavyweight standardized middleware, such as AUTOSAR in automotive, to a simple task).
Having the proper processes, methods, and tools within an organization can also reduce or even eliminate complexity within embedded system development. Example levers are standardization of development tools, reduction of manual tool interfaces, removal of organizational interfaces, introduction of a TCO-based controlling logic, and benchmarking requirements against competitors.
Just like standardization within embedded systems, standardization of the development toolchain is an effective means of reducing complexity. Standardized tools allow for more efficient collaboration and faster data exchange. TCO-based business-case logic can be applied to support decision making on variant reduction by considering the financial effects of additional hardware variants on development effort or on product launches. Product launch delays due to the development of another variant are not uncommon, especially if bottleneck resources are required.
Having the proper processes, methods, and tools within an organization can also reduce or even eliminate complexity within embedded system development.
A typical obstacle to dropping a hardware variant is that savings in development effort do not justify the potential of additional material cost. In these situations, cost-of-launch delay may become a decisive factor, especially if important launch deadlines, such as Christmas, need to be met.
Contain and delegate
In the contain-and-delegate strategy, a company first contains complexity and then delegates it, handing it off to a specialized party. A component of an embedded system can be contained by decoupling it from the rest of the embedded system, effectively encapsulating it. A variety of options then exist to handle it, such as putting it into a separate project or release train that may follow its own release cycle without interfering with the timeline of the main project.
The decoupled or encapsulated part of the embedded system can ideally be treated like a black box with respect to other system components. While this part is still in development, stable application programming interfaces (APIs) between the encapsulated part and the remainder of the embedded system need to be provided to allow the full system to be integrated for testing purposes even in an unfinished state.
Once a complex part of an embedded system is contained, another entity, such as a specialized unit or supplier, can be delegated to handle it. This specialized entity may have greater experience, more specialized resources, or better tools. However, even though the contained part may be better handled by a different entity, this also creates additional organizational complexity.
Another option is to deal with the complex part at a later point in time. In this way, development of certain complex features can be deferred without having to postpone the start of production. This approach works best if the features in question are not crucial from a customer perspective and don’t need to be available from the start. Moreover, if remote updating of the embedded system is an option, this may not even be an issue.
Monitor and manage
Monitoring and managing complexity is required to enable all other strategies. This strategy aims to create transparency around the current level of complexity, to monitor any unwanted rise in complexity, and to establish an integrated set of processes, methods, and tools along the full development process to master complexity. A clear perspective on complexity drivers is a prerequisite for this strategy. To provide a holistic view, this perspective must cover not only the embedded system and its various layers (for example, software, electronics, and the network) but also the complexity drivers related to the organization, processes, methods, and tools.
Concrete levers within the monitor-and-manage strategy include integration planning based on holistic modeling of interdependencies, use of standardized tools to monitor complexity drivers (for example, code quality metrics), use of agile principles, and rigorous application of software-development-excellence practices, such as continuous integration and deployment (CI/CD), test automation, and performance management.
To ensure timely delivery of embedded systems, many organizations have built a single source of truth to integrate planning of large-scale embedded-system projects. The foundation of integration planning is a holistic model of system component dependencies, including how the system depends on the tools and processes needed to complete each step of system and component integration.
Clarifying and tracking dependencies enables integration planners to define when a specific piece of software, tool, or process has to be provided so that subsequent integration steps are not delayed. Graph databases are well suited for this kind of interdependency modeling, as the connections (lines) between individual elements (nodes) correspond to a certain type of dependency; for example, different types of lines may signify “is built upon,” “requires for testing,” or some other type of dependency. This property is typically not present in relational databases, especially not in such a visually obvious manner. Making these interdependencies apparent provides the foundation for previously mentioned levers in embedded system complexity management, such as decoupling in the contain-and-delegate strategy.
Organizational agility and agile ways of working also greatly help with managing complexity. Organizational agility can allow a company to quickly set up development teams whose scope and capabilities are tailored to a specific part of an embedded system. Agile ways of working, such as iterative builds and feature prioritization, enable fast reactions to rising complexity, particularly when combined with complexity monitoring. When applied correctly, these techniques uncover complexity and allow teams to adjust the scope and objectives of sprints to limit complexity with relative flexibility. Ideally, monitor-and-manage approaches are used in combination with one or more of the other complexity management strategies.
Applying complexity management strategies
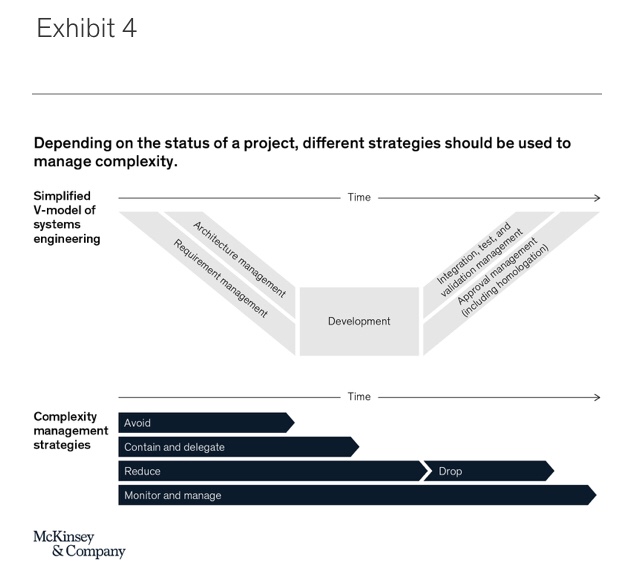
It is best to use each of the four complexity management strategies and their associated levers at specific stages of the product or project development cycle (Exhibit 4). The avoidance and contain-and-delegate strategies are most useful during early project stages, when requirement engineering and architecture design are taking place. Avoiding and containing complexity early on is vital, since some system design choices are nearly impossible to revert later on in the development process. The reduce-and-drop strategy may be used throughout embedded system development projects, but some specific levers lose their effectiveness in later stages of development—for example, because a lot of development resources have already been invested on a particular functional component and other elements rely on it due to a given architectural blueprint. Finally, due to its fundamental role, monitoring and managing complexity remains relevant throughout the whole development cycle.
Outside of individual products or projects, it is important to identify a suitable way to integrate complexity management into the organization itself. Given the far-reaching consequences of improperly managed complexity, such as budget overruns, launch delays, and feature cancelations, the topic should be top of mind for any manager and team member within the product development organization, as well as for adjacent organizations, such as product management and controlling. Especially in the early phases of embedded system development, close attention to minimizing system complexity and maximizing the ability to cope with complexity is of utmost importance. This is a combined responsibility of a cross-functional team, typically consisting of members from product management, R&D, controlling, sales, procurement, and IT.
Larger organizations often establish dedicated teams that are specifically tasked with complexity management based on the four described strategies. Despite their dedicated roles, these teams require close collaboration with and support from all involved parties in the R&D process to ensure the effectiveness of all complexity management levers. Complexity management and its benefits need to be deeply engraved in a company’s mindset.
Especially in the early phases of embedded system development, close attention to minimizing system complexity and maximizing the ability to cope with complexity is of utmost importance.
Properly managing complexity in embedded systems is critical. By applying proper strategies, this difficult task becomes doable. To return to the analogy of mountaineering, the guidelines for managing complexity are straightforward to learn but tricky to master: plan carefully and follow the right path, make sure to have the right gear with you, and—most of all—know where and when to stop the ascent to greater heights.
3. Embarking on the complexity management journey
When embarking on the complexity management journey, the first step is an honest evaluation of one’s current position in the complexity management effectiveness matrix (see Exhibit 3). This needs to be accompanied by a thorough understanding of which drivers of complexity most affect the journey. Based on these initial diagnostics, one can derive concrete improvement levers that fall into one of the four strategies described in the previous chapter. Then, rigorously applying these levers is crucial to keeping complexity manageable.
Determining the starting point in complexity management
The first step in determining one’s position in the complexity management matrix is defining the relevant scope in consideration. Is it a single embedded-system-development project, or is it a portfolio of projects? The following is mostly focused on a single yet extensive project, but it can easily be extended to a full portfolio of projects. For an initial positioning in one of the zones in the complexity management effectiveness matrix, the perspective from leaders in the development organization provides a good first indication. However, for a thorough diagnosis, a systematic analysis covering the dimensions of complexity—that is, environmental complexity, system complexity (incorporating both system design and ODD), and ability to cope with complexity—is needed (see sidebar “Defining complexity”). For each dimension, it is important to go deeper and consider the key drivers of complexity.
The following are some examples of drivers (see also chapter 1 for a broader overview of complexity drivers):
Environmental complexity: the degrees of freedom (for example, movement) and breadth of corner cases to be considered
System complexity: the number and quality of requirements, number of variants, and degree of reuse and standardization
Ability to cope with complexity: the level of toolchain integration and standardization, level of collaboration, team structure, or use of agile development practices
Once it is clear whether current issues come mostly from system complexity (extreme mountaineering zone), ability to cope with complexity (flip flop zone), or both (savage mountain zone)—assuming that environmental complexity is largely given—the proper strategies and levers need to be picked. Exhibit 5 provides an overview of the complexity management strategies and associated levers structured along system complexity and ability to cope with complexity. Note that the list of levers is not exhaustive but rather provides a starting point that needs to be adapted to the situation of a specific organization.
Applying complexity management strategies and levers: System complexity
In the extreme mountaineering and savage mountain zones, managing system complexity is key. There are specific levers defined along the four key strategies.
Avoid
A1. Zero-based customer-back offering and requirements definition. Requirement overflow, especially when multiple product management organizations with different customer groups are involved, is a common driver for complexity. Minimizing requirements to what is necessary (for example, from a legal perspective) and what is key for customers can help avoid complexity altogether. The impact can clearly be huge, as some potentially costly features—that due to their complexity might never have hit the market—are not even developed.
A2. Simplification of architecture by standardization and decoupling. When different organizational units work on an embedded system architecture, they tend to employ their preferred software components—for example, for communication protocols or for middleware. This increases complexity, for instance in testing or for bridging between different protocols. Enforcing architecture standards that require using exactly the same middleware or communication protocol across different control units helps avoid this complexity. Similarly, strong coupling of individual modules in an architecture drives complexity because changes in one module usually have a strong impact on the other, as well. Building an architecture with decoupled modules and standardized interfaces, on the other hand, enhances reuse and allows individual module teams to work largely independently. This limits complexity in their work, as the need for alignment teams working on other modules is lowered. The effect of proper modularization alone can be huge: one organization that embarked on a rigorous architecture modularization program was able to cut software development and support costs by 25 percent.
A3. Simplification of architecture by limiting spread of functions across architecture elements. For reasons such as limiting the necessary processing power of individual control units, functions are sometimes spread across multiple modules. This is especially the case in architectures where low-performance and high-performance variants have been introduced. Functions that were allocated to a single high-performance control unit in one variant need to distributed across several control units in the other architecture variant in which the high-performance control unit does not exist. This greatly drives complexity of interfaces and raises development and testing effort. Thus, avoiding this practice of spreading functionalities or removing variants altogether (see lever B1) is a key enabler of development efficiency and reduced cost.
Reduce and drop
B1. Reduction of architecture variants. New architecture variants quickly emerge—for example, when separating high-end and low-end functionality or due to regional specifics. Variants drive additional effort especially in testing and validation, as often individual variants need to be tested and validated separately. Gaining transparency on these variants and systematically removing those not absolutely necessary is a key lever for reducing complexity. For one organization, the reduction of a variant meant freeing up bottleneck resources that otherwise would have been occupied with validation and testing of that variant. Due to the variant’s removal, the overall validation and testing timeline could be accelerated by 1 to 5 percent.
B2. Redesign and refactoring to standardize and reuse software components across the stack. It is common that during development new requirements emerge or cost pressure and a lack of strict governance result in nonadherence to architecture design guidelines. The result is an increase in largely unnecessary system complexity. Redesigning some architecture elements and refactoring code may become necessary. This allows for standardizing, modularizing, or enforcing code reuse in systems whose development has already progressed. As redesign and refactoring can be time consuming, the benefits of standardization, modularization, and reuse should be weighed against required effort and prioritized accordingly. Before the application of redesign and refactoring, 85 percent of one organization’s modules contained custom code. After the change, 60 percent of modules were identical, and only 5 percent had custom code. As a result, product configuration cost could be reduced by 10 to 15 percent, and cost in support and maintenance was lowered by 15 to 20 percent.
B3. Dropping of requirements and removal of functionality based on customer and competitor insights. Delayed development timelines are often caused by new project requirements or an underestimation of the complexity of realizing some of the initial requirements. In this case, dropping some of these requirements or even removing full functionalities may be inevitable to reduce complexity and allow delivery of the embedded system in time and in quality. To identify those requirements or functionalities best suited for removal, prioritization is needed. Key criteria include requirement complexity, the potential effort that nondevelopment of a functionality may entail, and customer impact. To determine the latter, it is necessary to develop both a clear perspective on expected customer needs, as well as continuous benchmarking of planned and currently developed functionalities against today’s competitor offerings and those expected in the future. Dropping requirements and functionalities can be a great yet somewhat risky lever for reducing complexity. If critical deadlines for product launch, such as Christmas, need to be met, this may even be the only way.
Monitor and manage
C1. Holistic interdependency modeling for ultimate transparency and critical-path-based development. A key driver of complexity is the number of interfaces and dependencies among components in an embedded system and also their relation to tools such as test instances. If interdependencies are not properly documented, adverse effects—for example, on testing and validation—can be enormous. The first step toward managing interdependencies is creating transparency—regarding both the components that depend on each other and the specific tools the development timeline depends on, such as those used for simulation and testing. Once interdependencies are fully transparent, for example, bottlenecks in the development process, root causes for failed test cases, and subsystems contributing most to overall complexity can be identified. Based on these insights, a number of levers, such as B1 or B2, can be applied in a much more targeted way.In addition, transparency on interdependencies enables critical-path analysis. The critical path reflects the longest sequence of tasks the completion of which is required to finish development. Development following the critical path makes sure that more fundamental subsystems upon which the customer-facing functionalities depend are developed first. Also, in case of errors, these can be more easily located based on the interdependency map. The effect of a holistic interdependency analysis combined with rigorous system development following the critical path can be huge. For an organization whose market launch of its key new product was at stake, the development timeline could be shortened by 10 percent by strictly following a critical-path-based development order for software components.
C2. Code analysis metrics, code complexity metrics, and clean code. There are a number of quality standards and coding best practices when it comes to software development. These aim to ensure that code is developed in a readable, clean way, fostering intuitive understanding. Multiple of such practices are summarized by the term “clean code”3 and encompass, for example, principles for formatting source code or for naming code elements. Several metrics, such as cyclomatic complexity, can be used to assess the complexity of code and therefore allow for the creation of a targeted view of potential complexity reductions. Rigorous application of these standards and best practices lowers complexity, facilitates code reuse, and improves collaboration across teams. Functionalities for measuring code quality are typically built into modern integrated development environments and, hence, are readily available.
Contain and delegate
D1. Enabling over-the-air (OTA) updates to delegate and distribute development postsale. When development timelines are tight due the burden of complexity, the ability to conduct OTA updates across all architectural layers postsale can prove to be a safety anchor. In case a certain requirement or functionality needs to be scrapped during initial development to meet deadlines, OTA updates allow them to be readded even after the product has already been sold. From this perspective, OTA updates buy additional development time that may be direly needed in case no other way of dealing with complexity was successful.
D2. Delegation of development to third parties. For developing highly specialized subsystems of an embedded system, specific capabilities may be required. Autonomous driving subsystems with capability needs around image recognition and path planning are a good example of this. In such cases, delegating development to a specialized unit or a third party that has better capabilities and experience than one’s own organization can aid success and be a viable strategy for managing complexity. Especially in the automotive industry, this is common practice and can be successful if certain best practices in supplier selection and collaboration model (see levers D3 and D4) are adhered to.
Applying complexity management strategies and levers: Ability to cope with complexity
In the flip flop and savage mountain zones, improving the ability to cope with complexity is key. There are specific levers defined along the four key strategies.
Avoid
A4. Involvement of top-notch talent and domain expertise. A common driver of complexity is overspecification based on the false belief that all current and potential requirements need to be met or that an embedded system needs to reflect all environmental complexity. One root cause for this is the lack of sufficiently experienced talent and domain expertise within the team. Having experts on the teams specifically for architecture and toolchain development is critical because they can draw on their experience to determine how to resolve trade-off decisions—for example, between system complexity and cost—where to draw system boundaries in a modular architecture, or how to set up an efficient toolchain combined with a proper operating model. Deep domain expertise helps with prioritizing requirements and abstracting from environmental complexity so that overall system complexity can be kept at bay.
A5. Rigorous application of domain-driven design. When systems are large and their development needs to be distributed across many teams this by itself adds a lot of complexity that needs to be managed. Domain-driven design4 provides a number of concepts that support dealing with these issues. Key concepts include the use of a ubiquitous language, model-driven design, or bounded context. For example, a ubiquitous language—that is, a commonly shared and strictly applied language—fosters cross-functional alignment and removes ambiguity at the interface between developers, domain experts, and users.
A6. Standardization of tools, methods, and processes. Some software-development organizations fall into the trap of using different tools to serve the same purpose across the organization, such as for backlog management or testing. Other organizations are relying on static drawings for architecture diagrams where dynamic tools would be needed to ensure that diagrams are always up to date and to enable drill downs. All of this adds unnecessary complexity and makes managing the required complexity of the task needlessly burdensome. Hence, the simultaneous standardization of tools, methods, and processes is a key lever to improve an organization’s ability to cope with complexity. For example, one organization developing a complex embedded system lacked clarity on the progress and development speed of each module. They greatly benefitted from integrating their entire development backlog into a single tool, allowing them to quickly identify and remove bottlenecks.
A7. Architectural and organizational alignment. If done properly, embedded system architectures are designed to facilitate systems functionality while reducing complexity to the minimum necessary level. What is often neglected, however, is that to actually develop the elements of that architecture, the structure of the embedded system development organization and the architectural structure need to be aligned. This is necessary because of Conway’s law5 : “Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.” Hence, if there is lack of congruence between architecture and organization, the architecture that is actually implemented will follow the organization’s structure if intended or not. If architecture and organization are aligned, complexity is avoided because relevant communication partners for individual developers are clearly evident, and unnecessary communication between unrelated organizational units can be avoided. This leads to an overall increase in development efficiency.
Deep domain expertise helps with prioritizing requirements and abstracting from environmental complexity so that overall system complexity can be kept at bay.
Reduce and drop
B4. TCO-based business cases, including effort, cost of complexity, and cost of delay.As already outlined in the first chapter, many embedded-system-development projects suffer from poorly adjusted finance methodologies. For example, current business case logic often incentivizes introduction of additional architecture variants to reduce material cost. However, the negative impact of an additional variant on system complexity, leading to increased development effort and a potential delay in product launch, is often neglected or insufficiently reflected in the business case. To counteract this, a true total cost of ownership (TCO) perspective is required. TCO not only needs to reflect all types of cost, with the full life cycle of a system extending beyond the development phase, but also risks—for example, the potential EBIT loss due to a late product launch. To make the TCO perspective work in practice, benchmark-based methods need to be in place where the effects of similar trade-offs are made transparent. The benefit of having a TCO perspective is to drive trade-off decisions that actually lower complexity.
B5. Top-down decision making on reduce and drop. In some organizations, efforts to reduce complexity—for example, via removal requirements or reduction of the number of variants—fail repeatedly. The root cause is often that different parts of the organization cannot agree on the metrics to value the effect of measures aimed at lowering complexity. One of the last resorts in this case can be rigorous top-down decision making on complexity reduction measures, with top management taking the lead. The benefit of top-down decision making is clear: decisions taken by top management can result in fast removal of complexity. However, this approach should only be temporary until other levers for complexity management, such as a TCO perspective in business cases (see lever B4), have been fully embraced by the organization.
The simultaneous standardization of tools, methods, and processes is a key lever to improve an organization’s ability to cope with complexity.
Monitor and manage
C4. Rigorous automation (for example, CI/CD, testing). When companies are only able to commit new code to a system every few months or so, this usually indicates that they lack toolchain automation. The result of such long iteration cycles is often that necessary but high-effort architecture changes are avoided and errors are only discovered late in development. Especially in situations with high system complexity and for large organizations, rigorous automation is a key lever for managing complexity. By installing rigorous CI/CD practices, one company was able to reduce the duration of code freeze to successful compilation of the target build from four or five days to less than half a day. Similarly, high test automation allows organizations to move into a test-and-learn model, allowing for much quicker refinement of architectures and code.
C5. Agile development practices and performance management. Key benefits from employing agile development practices are close collaboration between development teams and users and the ability to flexibly react to changes, such as new requirements. For example, the close connection to users enables developers to focus on what the customer actually needs, rather than developing features that add complexity albeit little value. Increased flexibility through agile development allows complexity reduction to be more easily driven, even while development is ongoing. Hence, refactoring (see lever B2), for example, can be flexibly included in program increment planning—one standard agile practice—when required. In a comparison between approximately 500 development projects applying either agile or more traditional “waterfall” methodologies, agile projects showed a 27 percent higher productivity, a 30 percent better adherence to schedules, and three times fewer residual defects at launch.
Contain and delegate
D3. Supplier selection based on capabilities. As noted in lever D2, delegating the development of a certain functionality to a third party can be powerful if that organization has better capabilities to develop it. However, in many cases, cost is the primary decision criterion when it comes to supplier selection, while the supplier’s actual execution capabilities—for example, measured by its experience in developing similar functionality as the one requested, its general development competencies, or the sophistication of its toolchain—only play a secondary role. The result of such supplier selection practices can be as disastrous as schedule delays, equivalent to several years. Alternatively, a due diligence assessment of the supplier’s competencies can be made part of the selection process to gain confidence on a supplier’s ability to deliver. This is especially relevant if the supplier is requested for the development of a critical subsystem within the embedded system upon which, for example, many other systems or critical customer-facing functions depend.
D4. Limiting of supplier interface complexity, including white boxing, agile, and colocation. Adding an external party to the development project adds another layer of steering, thereby increasing interface complexity and lowering the ability to cope with complexity. This is, for example, because supplier steering includes the need to formulate requirements that fit the supplier’s language, to align on those requirements, and to have the supplier accept them. Additionally, the organizational boundaries to the supplier make the application of previously mentioned levers harder. Thus, a proper setup and collaboration mode with suppliers is necessary. This includes the exchange of white box code versus the use of black boxes; joint use of agile principles, such as having a common development backlog and program increments; integration of each other’s toolchains to enable seamless data exchange; using a common language; or colocation to reap the benefits of having fewer development sites. Already, the last of these can greatly drive productivity. The analysis of our software project database has shown that if the number of development sites can be reduced by one, the effect is an increase in productivity of up to 10 percent.
4. From managing complexity to mastering complexity
There is no silver bullet to complexity management, but there are strategies and levers that can be applied in appropriate situations. In getting started on the complexity management journey, the following five steps have proven to be impactful:
Portfolio view: As a starting point, cut your R&D portfolio into projects with high and low complexity, considering both environmental complexity and system complexity. Within the set of high-complexity projects, select those that are critical from a business impact or timeline perspective. Be extra careful not to ignore high-value yet very early-stage projects because the time window for avoiding unnecessary complexity often closes quicky.
Complexity assessment: For critical projects, conduct an honest analysis to determine in which zone in the complexity management effectiveness matrix it is to be located (see Exhibit 3). Run a deep-dive assessment along the drivers of system complexity and the drivers that limit the ability to cope with complexity. Evaluate the impact of each driver against KPIs that are critical for project success, such as life-cycle cost, time to market, competitiveness, and customer experience.
Complexity management strategy selection: Considering the current development status of critical projects, pick the proper complexity management strategy and corresponding levers. Prioritize levers that address the drivers with the highest impact and that have the highest feasibility given the current situation of the project.
Complexity management strategy execution: Once levers are prioritized, begin execution. Make sure to involve all relevant functions (for example, R&D, product management, sales, procurement, and finance) to foster quick alignment and drive change. Ensure top-management sponsorship and decision making to ensure efficiency in lowering system complexity and improving the ability to cope with complexity.
Long-term change: Leverage cases of successful complexity management to derive and codify lessons learned so that next-generation projects avoid the pitfalls of the previous ones. In addition, build momentum to drive long-term change in the organization as it relates to complexity management. This should include organizational setup, operating model, tooling, and increased awareness of complexity and a cultural change. The objective is to make complexity management an integral part of the organization’s mindset, with complexity management strategies being applied rigorously.
One indicator that a company has achieved complexity management mastery is the building of effective, integrated, and end-to-end toolchains. This is because these types of toolchains allow for fast, virtual integration of the complete embedded system in short cycles; they enable quick identification and localization of errors via automated testing; and they avoid inefficient manual interfaces. One such master of complexity management is an industrial company that has built a comprehensive system-interdependency map for its software and electronics architecture, as well as a corresponding toolchain using graph databases. The transparency provided by the system-interdependency map gives company leaders the ability to identify and eventually change unwanted couplings between system components. It also allows them to reshape the organization so that systems components that require tight coupling are handled by closely collaborating units.
Mastering complexity management has multiple benefits, including reaching the Goldilocks zone. By taking complexity seriously from the start of any embedded system development effort, those embedded systems are able to fulfill challenging tasks, are developed in time, and result in high quality. This leads to satisfied customers and a stronger competitive position. Moreover, complexity management leads to happier employees who are more likely to stay with the company, as well as to increased attractiveness to new talent. Resources saved through complexity management mastery can be invested in developing the next product or in continuous updates of the embedded system with new functionality.
Complexity doesn’t have to be a purely negative factor in development. As Suzanne Heywood, Jessica Spungin, and David Turnbull wrote in “Cracking the complexity code,” complexity can be “seen as a challenge to be managed and potentially exploited, not as a problem to be eliminated.”6 They argue, rightly,
Johannes Deichmann is a partner in McKinsey’s Stuttgart office; Georg Doll is a senior expert in the Munich office, where Jan Paul Stein is an associate partner; Benjamin Klein is an associate partner in the Berlin office; and Bernhard Mühlreiter is a partner in the Vienna office.
The authors wish to thank Nico Berhausen, Jan Brockhaus, Ondrej Burkacky, Hannes Erntell, Ruth Heuss, Christos Kapellos, Gérard Richter, Fabian Steiner, and Rupert Stuetzle for their contributions to this report.
Nearly a year after President Joe Biden signed off on an expansive cybersecurity executive order, officials are grappling with the difficult task of taking secure software standards and applying them to the vast array of software agencies buy.
The Office of Management and Budget plans on releasing new secure software guidance for agencies within the next eight to 12 weeks, according to Chris DeRusha, federal chief information security officer. The guidance is based on a “Secure Software Development Framework” (SSDF), as well as “Software Supply Chain Security Guidance” released by the National Institute of Standards and Technology in February.
“This is about incenting the vendor communities that are serving and selling to the U.S. government to start adopting this framework, and specifically secure development practices,” DeRusha said during a March 23 workshop hosted by NIST. “That means a culture change in agencies and means a culture change in some of the vendor organizations themselves.”
DeRusha said OMB’s goal isn’t to set up a new compliance regime, although part of the effort will involve attestation and verification measures. He said one of OMB’s objectives is ensuring there’s a uniform approach across agencies.
“What we want out of this is a clear, concise and efficient approach to do vendor attestation and federal verification measures,” DeRusha said. “We really want to ensure agencies are doing this in the same way, and that we’re really looking at how we can do things like reciprocity.”
OMB is working in parallel with the Department of Homeland Security, which was tasked under the cybersecurity executive order to deliver recommendations to the Federal Acquisition Regulation Council on contract language that would require companies to comply with and attest to secure development practices. Those recommendations are due on the executive order’s first anniversary on May 12.
“We’re driving fast, and we’re working also to align with the DHS recommendations,” DeRusha said.
The software security requirements were mandated by last year’s executive order, which was partially motivated by the SolarWinds software supply chain hack that affected at least nine federal agencies. The work has been further spurred on by the recently discovered vulnerabilities in Log4j, a widely used open-source software logging utility.
DHS Chief Information Security Officer Kenneth Bible said federal CISOs want to get a better handle on the integrity, composition and provenance of the software their agencies are relying on.
“From my own experience with Log4j, that composition piece kind of weighs heavy, because of the lack of visibility particularly in compiled code of where actually that vulnerability existed,” Bible said during the NIST workshop. “It’s something that we’re going to be looking at and seeing pop up for years … Do we have to continue to have more and more endemic vulnerabilities? Or can we start to understand the composition better?”
NIST’s framework describes “a set of fundamental, sound practices for secure software development.” A key question for companies is to what extent agencies will require them to prove out the security of their software through a process called “attestation.”
“A clear plan is really important,” Henry Young, director of policy for The Software Alliance, said during the workshop. “There’s really no way a party can attest to something, if it’s not clear to what they are attesting.”
Industry representatives at the workshop advocated for the guidance to take into account existing certifications and compliance standards, including the Federal Risk and Authorization Management Program (FedRAMP) that has been used for a decade to certify the security of cloud services.
Industry representatives also advocated for reciprocity and standardization to feature in the OMB guidance so companies won’t have to go through the same process for multiple buying components. Young mentioned the Defense Department’s Supplier Performance Risk System as a potential model.
“I also think that it’s important to think about in this context, kind of the centrality or the consistency of an attestation, so we don’t have a situation where the company is attesting to any of the dozens of departments and agencies, duplicating its work,” Young said.
Another key question is to what extent OMB and agencies will allow software vendors to self-attest to their compliance with the software security standards, or if they will require agency or third-party verification.
Sharon Chand, principal of Deloitte Cyber Risk Services, said it’s likely a self-assessment will be what’s required in most instances.
“I think the scale at which this has to happen necessitates that self-assessment, first party assessment for a wide number of applications and systems,” Chand said. “There will certainly be some that might require a second- or third-party attestation. But just thinking about the scale at which this needs to operate to achieve some of the overarching objectives, I feel like that self-assessment is required.”
Our latest IT survey confirms the accelerating pace of at-scale core technology transformations. The road map for success reflects the practices and capabilities of leading companies.
In a time of significant, ever-quicker shifts in the IT portfolio, a new survey suggests that a company’s foundational technology has never been more important. In our latest McKinsey Global Survey of technology and business leaders,1 the results point to a much greater focus on cybersecurity and on investments in cloud technologies—even as most companies have continued transforming their core architecture and infrastructure in tandem.
The survey also confirms that the competitive divide between winners and the rest has only grown during the pandemic. Compared with the IT organizations at other companies, those at the top—rated by respondents in the top quartile of effectiveness for 15 key technology activities and capabilities—have made much more progress in their cyber, digital, and cloud moves. For companies trying to catch up, or at least keep themselves from falling further behind, these top performers’ responses point to a few key practices: a more aggressive and holistic agenda for tech transformations, greater involvement by tech leaders in business strategy, and a more proactive approach to people development. As we’ve seen in previous surveys, the latter is a bigger challenge than technology during these transformations.
In response to new realities, cybersecurity has moved to the forefront
Our latest survey results confirm the acceleration of corporate investments in technology transformations and the overall high value of these transformations,2 especially at companies where creating IT strategies is a joint effort by technology and business leaders. At such companies, respondents are more likely to report that their transformations have had a positive impact in every one of the four value-creation measures we asked about: increased revenue through existing streams, increased revenue from new streams, decreased costs, and improved employee satisfaction.
Yet the transformation landscape shifted dramatically in the past year. A larger proportion of respondents than in the previous survey (41 percent, up from 30 percent) cite an increasing likelihood of cyberthreats as a major transformation challenge. Respondents also report a significant increase in cybersecurity transformations at their companies (62 percent, up from 45 percent previously), followed by infrastructure and architecture transformations. A sizable share of respondents say their companies are pursuing several of these key transformations at once, which helps ensure that their interdependencies are understood and addressed: 42 percent report both cyber and infrastructure transformations, 40 percent both infrastructure and architecture transformations.
What’s more, respondents are betting that the increasing number of cyber incidents—coinciding with growing reliance on digitization, a proliferation of endpoint devices, and increased vulnerabilities in hybrid and remote-work setups—is not a pandemic-era phenomenon but rather part of a new business reality. Cybersecurity is the transformation respondents are most likely to cite as the one their companies will pursue in the nexttwo years; the share more than doubled since the previous survey (Exhibit 1). Respondents say that cybersecurity talent is in high demand to meet this need—second only to advanced-analytics specialists as the role their technology organizations are most focused on hiring.
A widening performance gap between top IT organizations and the rest
Our previous survey ran during the pandemic’s earliest days, when respondents at companies with top-performing IT organizations reported several ways they were making tech a key priority for their organizations. Such companies had tech leaders who were more involved in the business. They had adopted more advanced technologies. They were executing more technology transformations. Finally, they had created more value through those efforts. This year’s results suggest that on all these fronts, the top performers are further ahead of the others than before—and that their competitive edge is poised to grow even more unless other companies adopt many of the same practices.
For example, 73 percent of respondents at top-performing companies now say that their most senior tech leaders (the chief information officer or chief technology officer) are highly involved in shaping the company-wide strategy and agenda. Only 31 percent of other respondents say the same—a gap that’s more than twice as big as it was in 2020 (Exhibit 2).
The results suggest that companies in the top-performing group are also pulling away from the pack in their use of more advanced technologies, such as advanced analytics and edge computing, and in their overall level of transformation activities. In the newest survey, top performers are much more likely than other companies to have pursued five of the ten transformation moves we asked about (our “tech forward” approach) than they had been in the previous one—especially scaling up data and analytics and changing IT’s delivery model.
Furthermore, their transformation approach is more holistic: according to respondents, the gap between the average number of moves top performers and other companies made has grown since the previous survey. These top companies have also stepped up their game in enhancing their architectures, which they were less likely than others to report in the previous survey (Exhibit 3). Top performers remain ahead of their peers on cyber transformations, although those other companies are also much more likely to be pursuing such efforts than they were previously.
As we’ve seen in previous years, people—rather than technological—issues tend to be the biggest obstacles that keep companies from achieving their transformation goals. The COVID-19 crisis raised the stakes because the way people and teams work changed so fundamentally, and the results suggest that during this time, the top performers have taken a more proactive and effective approach to talent, culture, and people development. These respondents are much more likely to say that their companies redesigned their technology organizations to better support business strategy during the crisis and have effective core capabilities for managing IT talent (Exhibit 4).3
The leaders of top-performing organizations also appear to be much more effective on these issues: 47 percent of respondents at these companies say that their senior technology leaders very effectively foster a culture that supports new and digital ways of working, such as “fail fast,” across the organization. Only 3 percent at all other companies say the same (Exhibit 5).
Companies are ramping up their cybersecurity defenses and their adoption of cloud technologies, which can create a more flexible infrastructure, speed up technology deployment, and get digital products to market more quickly.
The move to the cloud gains momentum
According to the survey, companies are also ramping up their adoption of cloud technologies, which can create a more flexible infrastructure, speed up technology deployment, and get digital products to market more quickly. Thirty-six percent of respondents say their companies have accelerated the migration to cloud technologies during the pandemic, and 86 percent of them expect this acceleration to persist postpandemic. At companies with higher levels of digital maturity, respondents are more likely than others to report cloud migrations. But fully half of the respondents say their companies are planning either large- or full-scale cloud transformations within the next two years. The top benefits from the use of cloud computing (Exhibit 6) include the optimization of technology costs (56 percent); risk reduction, such as improvements in business resilience and cybersecurity defenses (41 percent); and the digitization of core operations (39 percent).
These efforts aren’t without their challenges. Companies already pursuing a cloud migration most often face technical issues, conflicts with the business over timing, and an inability to realize the migration’s expected value (Exhibit 7). Again, these challenges are less acute if there is a close partnership with the business up front. At companies where technology strategy is created with the business, respondents are 34 percent less likely to report conflicts with it over timing and 60 percent less likely to report challenges in realizing the expected value. These results confirm the idea that being in lockstep with the business is essential to capture the cloud’s huge potential—which, our other research suggests, could involve up to $1 trillion in value globally.
Looking ahead, the need for corporate technology to be dynamic and responsive to the changing needs of business will only continue to grow. Companies that don’t already have a strong technology foundation are poised to fall even further behind. To reap the full benefits of technology, companies will have no choice but to pursue multiple transformation plays—for example, cloud, cyber, and talent—at the same time and to stay the course for each. The survey results suggest that even the more emergent aspects of the technology agenda (cybersecurity and the cloud) have real staying power and relevance, which only adds to the demands on technology leaders and their business partners.
The survey content and analysis were developed by the following members of the Chicago office: Anusha Dhasarathy, a partner; Ross Frazier,an associate partner; Naufal Khan, a senior partner; and Kristen Steagall,a consultant.
They wish to thank Eric Lamarre, Kate Smaje, and Audrey Wu for their contributions to this work.
This article was edited by Daniella Seiler, an executive editor in the New York office.
How a handful of Airmen brought DevOps to USAF, then used it to save more than 123,000 lives.
Kessel Run was founded on a hypothesis that by bringing commercial DevOps practices to the Air Force, warfighters could get better software, faster, for less money. Our experience over the last four years has borne that out. Our critical change was putting the developers, the security operations, and IT operations together in a single team to make a DevSecOps [development, security, and operations]unit. Traditionally, dev responsibilities fall within Air Force Materiel Command and IT operations within the operational MAJCOMs; this split slows down real time delivery. In August 2021, Kessel Run showed that developing software solutions in real time has real world impact and helped save the lives of more than 123,000 people. We have the results from the experiment, and the data show clearly that the Kessel Run model, the DevSecOps unit, should be the standard for Air Force software factories.
It’s Aug. 24, 2021, and tension is in the air inside the Combined Air and Space Operations Center (CAOC) in Al Udeid Air Base, Qatar. There’s only a week left before the Taliban deadline to evacuate the remaining Americans, interpreters, and others who had helped the United States in Afghanistan over the two decades since 9/11. Many are young enough to only have vague memories of what life was like prior to the Americans’ arrival in 2001. It’s here, at the CAOC, where the airlift is being planned and managed.
The situation in Afghanistan is similarly tense. Around 6,500 people are at the airport waiting for a flight out of the country. A week earlier, desperation led people to chase after or hide in the wheel wells of departing C-17s. Horrifically, some fell to their deaths when the aircraft took off. Now, the crowds are drawing the attention of ISIS-K, which is planning an attack that will come only two days from now. The need for an orderly plan to evacuate as many people as possible was clear.
Back at the CAOC, the team of air planners is trying to use Kessel Run’s software to plan the missions that will ferry people out of Kabul on planes from the United States and many other countries. A proper plan is critical because the air traffic control at Hamid Karzai International Airport (HKIA) is not used to this level of traffic, so the planners must space out the arrivals and departures into very precise time slots.
However, the software isn’t working.
The team is going to the Slapshot website, but it’s not loading. This was a known risk. As a development Minimal Viable Product (MVP), Kessel Run’s applications were designed to accommodate the number of missions in steady state operations. The changes needed to scale to over five times as many missions were in the backlog, but deferred for higher priority work until next summer. Now, the evacuation has driven the mission count up 10 times in a matter of days. If this evacuation fails, thousands of people would be stranded as the Taliban take control of Kabul and the rest of Afghanistan. It’s a literal life and death situation.
In the midst of the flurry of action on the CAOC ops floor, a young government civilian calmly goes to his computer at the back of the room and submits a message to a team in the United States. It’s a similar message to others the team has sent before, but this time the stakes are much higher.
“We are experiencing intermittent loading issues with Slapshot. The exercise theater does not load. We need to call an outage so that we can fix the issue,” he said.
Back to October 2016—the beginning
Eric Schmidt, then executive chairman of Alphabet, Inc., Google’s parent company, served as a member of the Defense Innovation Board (DIB). The board worked to find ways innovation could address future challenges to DOD. As part of that work, the board went to the same Operations Center in Al Udeid where this story began.
The whiteboard on which tanker refueling operations were planned was like a game of Tetris. While one teammate enters data into an Excel spreadsheet, another moved magnetic pucks and laminated cards around the whiteboard. Kessel Run converted the manual system into an automated software program. USAF/courtesy
Famously, he saw Airmen planning refueling missions on a whiteboard with tape grids, magnetic pucks, and dry-erase marker lines connecting the puck together to define the plan.
When he later asked the Air Operations Center (AOC) commander what his biggest concern was, the commander said: “Well, frankly, … I don’t want them to erase my whiteboard.”
Shocked that an eraser created one of the biggest threats to the air war supporting operations across Iraq and Afghanistan, the board members pressed the team about why better tools don’t exist. He asked if they even had modern software. He was told, “Yes, but it doesn’t work.” This failed modernization effort left the AOC with the nearly the same system that was originally developed in the 1990’s—20 years and several software lifetimes ago.
This effort to modernize the AOC 10.1 software was called the AOC 10.2 program. The Capability Development Document of 2006 formalized key functional requirements for the AOC and in that same year Lockheed Martin was awarded a $589 million contract in order to “standardize, modernize, sustain, and transform” the AOCs. Under traditional acquisitions, this was pre-Milestone B “risk-reduction” activity. In 2013, Northrop Grumman won the development award and began work on the 10.2 program. By the fall of 2016, Northrop was already three years behind schedule and estimated development costs had ballooned from $374 million to $745 million. It was a decade after the requirements were identified and no code was delivered to the field for use. This is the scene that the Defense Innovation Board walked into when they visited the CAOC.
Raj Shah, a Managing Partner at Defense Innovation Unit (DIU) at the time, was with the Defense Innovation Board, and literally called Col. Enrique Oti, an officer at DIU, that night, and said that he would commit $1M of DIUx’s money. The goal was to get a new tanker planning tool and demonstrate DevOps can deliver solutions faster than traditional waterfall and Joint Capabilities Integration and Development System (JCIDS) development.
Capt. Gary Olkowski demonstrates “Jigsaw,” the digital tanker planning tool built for the Combined Air Operations Center at Al Udeid Air Base, Qatar. Developed in just four months, Jigsaw paid for itself within six months of being deployed. USAF
The Air Force team, led by Oti, sat side by side with Airmen in the CAOC to design a warfighter-friendly tool. The resulting Jigsaw Tanker Planning Software turned an eight-hour task for six people into a three-hour activity. By April 2017, four months after work had started, the tanker planning tool was in use in Qatar.
Within six months, the Jigsaw application had essentially paid for itself. The efficiency it had created saved 400,000 to 500,000 pounds of fuel each week and required one less refueling aircraft. This saved the Air Force $750,000 to $1 million every week.
Remember, Raj only spent $1 million on the entire effort.
It’s no wonder that the 10.2 program received a stop-work order on April 19, 2017, and was terminated in July. The Air Force needed to do things differently to avoid the same outcomes. There was a team—also an experiment—that could lead that new approach. This new team of coders was going to build on Jigsaw’s success and modernize all of the AOC’s software.
Jigsaw was combined with the Targeting and GEOINT program office (also using DevOps to modernize their tools, led by Capt. Bryon Kroger), and the government team who was sustaining the AOC 10.1 system within PEO digital.
That team was named “Kessel Run,” both as an homage to “Star Wars” smuggler who could bring outside things (like DevOps) to a bunch of rebels, but also because Han made the Kessel Run in 12 parsecs, a hyperspace distance shorter than anyone else had done before. That was our mission: Shorten the time and distance it took to get to our destination.
Here are some of the ways that we close the gap.
User-focused design
Jigsaw began with our dev-teams sitting down with the users in the AOC to understand their value chain, and how they could be more effective and productive. We have continuous user interviews and track customer satisfaction scores. Getting software into users’ hands as soon as possible has led to our users coming up with new use cases. Today, we have our team members embedded at the 609th CAOC every day.
As we add new applications or features to our scope, we start with a discovery and framing session with our users. We don’t turn to requirements documents first or trust that documents written in 2006 represent the world as it is today. Instead, we work with the users to scope a MVP and then begin iterations of the build-test-learn cycle.
We map out their processes so we understand what the users need.
After that, we start designing the solution. We co-design with the users and start to map the data flows so we can see the interdependencies between applications and workflows.
Finally, the goal isn’t to provide a mock-up or a prototype, but to build an MVP that users can test and use to support operations. Having users test thin slices of the ultimate system starts the build-test-learn cycle and gives us constant feedback on our software to continuously learn what is working and where the gaps are.
This is very different from traditional acquisitions where only finalized systems are made available to users. It can create challenges since we release versions that we know don’t meet the entire set of needs, but can provide value that can grow over time. For example, our Kessel Run All Domain Operations Suite (KRADOS) in August had known issues around scaling for major operations.
More on that later.
Continuous delivery, in practice, means changes to the software are happening on a regular basis, multiple times a day, eventually adding up to major changes over time.
For example, Jigsaw has been used for every air refueling mission in the CAOC since December 2019 as a stand-alone application. Slapshot, the tool for planning the rest of the air missions, has also been used for every mission at the CAOC since December 2019. Again, it was used as a stand-alone application for over a year because we didn’t have the connection to a common data layer built yet. However, the integrated suite of 10 applications with a common data layer was released as an MVP in January 2021. It was accepted, and used for planning the Master Air Attack Plan at the CAOC, since May 2021.
Let’s dive a little deeper on how we make those changes to production software.
Continuous Innovation and Delivery
At Kessel Run, we have a different challenge from commercial software-as-a-service providers. We don’t have a single internet that we’re deploying to. We have 10 different environments because of users on unclassified, secret, and top secret networks—and the different variants of those networks for different coalition partners.
In order to manage deploying software to these regions, maintain version control, and reduce human touch points in the deployment process, we rely on automated continuous integration and continuous deployment pipelines.
That starts with our developer pipeline, which takes the application code from their workstations and puts it into the Gitlab repository where we maintain our code. When the dev-team thinks the changes are ready to deploy to our staging environment, they push the code through the CI pipeline along with a deployment manifest. The security release pipeline is part of this release, which includes code scanning, vetting dependencies, and putting the artifacts into our Nexus repository. Once there, they are available in the staging environment for testing and verifying integration with other applications and services.
When those changes are ready to be promoted to production, the immutable images are moved from Nexus into our purpose-built deployment manager (RADD) into the production environments. Our Continuous Deployment pipelines depend on whether the deployment is going to our AWS unclassified cloud, on-prem Secret, or Top Secret cloud.
We use these pipelines multiple times each day. On average, we deploy code through a deployment pipeline once every 3.3 hours. From the time the dev-team is ready to deploy, on average, it is only eight hours before the changes are available in production environments. Much of that time is spent moving artifacts from unclassified networks up to classified, which still requires burning CDs and rescanning on both sides of the air gap. We hope to have a cross-domain diode that will take the human touch point out of the process. That should speed the deployment times further and help us get to the self-service deployment using full automation.
Focus on applications in-production
While many teams see the job as finished when code gets into production, we see that the job is only partially done. While we haven’t yet established service level objectives, or agreements with our users, a point of pride for Kessel Run is our ability to service apps in production, respond to issues, and never have the same outage twice.
Our teams provide security support and monitor applications to ensure they are available. When we have an issue, on average we have it resolved in under 120 minutes. After every outage, we conduct a no-fault retro to identify root causes and assign fixes to the backlog.
That process begins with a report in our MatterMost channel for outages. That brings us back to Aug. 24, 2021, when our liaison officer at the 609th submitted the outage report.
DevOps in Practice
It was 2:49 a.m. in Boston. Remember, that we knew that the production version of our applications couldn’t handle the growth in mission counts that we saw in the evacuation effort. Now the software was being asked to do exactly that.
Meanwhile, the crowds outside HKIA grew and the deadline to get everyone out wasn’t going to change just because we had an outage in production.
Our platform team noticed spikes in latency seven minutes after the call was initiated. Along with the LNOs, the on-site platform team started collecting data on the classified network to help pinpoint the problem when the dev-teams in Boston get into the office.
The evacuation from Hamid Karzai International Airport, Kabul, Afghanistan, resucued more than 123,000 people. On-the-fly software updates made that possible. Sgt. Isaiah Campbell/USMC
At 4:03 a.m. in Boston, the outage team began the response and began to work with the product manager to determine potential fixes. At 7:09 a.m., the dev-teams joined the outage call and confirmed the root cause. There was a setback at 8:28 a.m. when the apps completely crashed and the LNOs notified the center’s operations floor.
Still, only 12 minutes later, the platform team has cleared the bin files that had taken up all available disk space after the app lost connection to the SQL database. By 9:07 a.m., the team had doubled the number of compute instances available to Slapshot. At 10:25 a.m., the development team added a “theaters” feature to the production version of Slapshot that cut the number of missions displayed into smaller chunks.
That afternoon, at 1:44 p.m., additional compute instances were shifted to the 609th Slapshot, and it looked like the issues had been mitigated. At 4:06 p.m., our liaison officers confirmed with users in the 609th that the issue was resolved and got feedback on the new theater feature. They had positive feedback and the outage call ended.
The call ended only 12 hours and 3 minutes after the product manager was woken up at 4 a.m. to start the call. In those 12 hours, the team was able to shift compute and store resources to United States Central Command’s apps to improve performance, fix the SQL database connection errors, clean out the bin files, and add new features to help slice the data and improve load times. Our dev-teams and IT ops teams worked together—from Boston and in Qatar—to identify the issues, propose solutions, and implement them in a single day.
The airlift was able to continue.
USAF set a record on Aug. 15, 2021, when one flight safely transported 823 Afghanistan refugees on a single C-17 flight. USAF/courtesy
Interpreters who had helped Americans and our partners were moved to safety. Women and girls fearful of a life under the Taliban were brought to safety where they could pursue their dreams. All American forces were out of Afghanistan by the Aug. 31 deadline.
To me, those 12 hours are the defining moment for Kessel Run. What started with Eric Schmidt’s disbelief in how planning was being done five years ago became an experiment to show a government-led DevOps team could deliver software better than traditional government acquisition. For comparison, that five years is the same time it took 10.2 to go through “risk-reduction” and start a development contract. Since the DIB visited the CAOC, we’ve been in use by users for all but the first six months of those five years. We add new features every week and move from stand-alone apps to an integrated suite. Kessel Run has shown that the full promise of DevOps is not something to see in the future—it’s happening now.
When lives depended on us, when the world challenged us, our DevOps Team delivered the software solutions our warfighters needed. In doing so, we demonstrated why DevOps—why the Kessel Run model—is an imperative for the Air Force.
Col. Brian Beachkofski is commander of the Air Force Life Cycle Management Center’s Detachment 12, an agile software development lab known as “Kessel Run.”
Chester Eastside is looking for a strategic, effective leader to advance the organization’s commitment to the Chester community. The attached posting includes an overview of the organization and the job description. Salary will be commensurate with experience and flexible work arrangements will be considered. All interested applicants should send their resume and salary requirements to Recruiter@ceichester.org. https://bit.ly/3JxHBFv
Katherine is the CEO of Creatio, a global vendor of one platform to automate industry workflows and CRM with no-code.
In early 2021, Gartner released a new forecast for low-code/no-code development tools. Driven by an increase in remote work due to the Covid-19 pandemic, Gartner projected a 23% increase for the global market for this type of technology. In the months that followed, low-code/no-code tools saw steady growth due to their effectiveness in addressing some of tech’s most complicated challenges—primarily the critical need to digitize workflows, enhance customer and employee experiences and boost the efficiency of commercial and operational teams.
According to Harvard Business Review, low-code/no-code platforms have evolved from just facilitating function-specific tools to making it possible for a broader range of business employees to truly own their automation and build new software applications with no coding while increasing organizational capacity.
Low-code/no-code tools also drew attention in the context of the Great Resignation, with Entrepreneur noting that low-code/no-code platforms make it easier for companies to address the ongoing shortage in engineering and developer talent. An increasing number of businesses and IT leaders are leveraging the possibilities of low-code/no-code tools as organizations work to turn more of their employees into citizen developers.
As the movement continues and adoption increases across key industries from financial services to manufacturing, organizations need to pay attention to these five topics in order to improve the performance of their new tools and ensure the success of their low-code/no-code initiatives.
1. Addressing Security In Low-Code/No-Code Platforms
It’s clear why executives would see the business benefits of adopting low-code/no-code platforms and tools. By giving nonIT employees the opportunity to build their own business applications, an organization can unlock new areas for rapid growth. However, some executives are cautious. As citizen developers are given the opportunity to build new applications, governance will be important. IT staff will need to put guardrails in place and have those built into low-code/no-code platforms to maintain consistent levels of security across the organization.
For companies integrating new low-code/no-code tools into their tech stack, or leveraging existing tools, it’s important to remember some of today’s most common cybersecurity best practices: namely, training every employee at the organization on good security behavior and using compartmentalization and limited access to prevent opportunities for mistakes.
2. Hiring, Training And Organizing Work For No-Code Developers
Encouraging employees to become no-code developers and create their own business applications requires a shift in mindset for everyone in the organization. This includes overarching processes like hiring and training, as the traits that make a good citizen developer may be different than those a company previously looked for. Above all, a good citizen developer is willing to be creative and take risks.
While the employees themselves should be free to create their own tools and solutions, it’s incumbent on the organization to create the frameworks that will allow them to succeed. Companies that embrace low-code/no-code tools must ensure that employees have access to training, reference materials and policies that will help them to align their operations with other business units and the company as a whole.
3. Organizational Alignment For Low-Code/No-Code Development
Low-code/no-code platforms democratize the ability to create new software applications, making it possible for individual departments or units to solve problems without a direct need to rely solely on scarce IT resources. For no-code companies, harmonizing workflows is a key requirement for success.
In a low-code/no-code organization, departments should be able to work without silos and communicate freely across functions. Low-code/no-code platforms make it easy to pass information from one area of the company to another and standardize the development approaches across business and IT teams. This emphasis on openness and alignment should come from the top, providing justification for employees at all levels to pursue new solutions.
4. Embracing Hyperautomation For Rapid Progress
According to Gartner’s “Top Strategic Technology Trends for 2022,” hyperautomation will grow rapidly over the next three years in terms of both deployment and investment. Business-driven hyperautomation allows organizations to “rapidly identify, vet and automate as many business and IT processes as possible.” Low-code/no-code tools are poised to play a leading role in this hyperautomation arms race. Organizations that take a centralized, coordinated approach to hyperautomation will be able to find new efficiencies that map directly to their business goals.
5. Speeding Time To Market With Composable Applications
Between the distributed aspects of hybrid work and the changing responsibilities enabled by low-code/no-code tools, the structure of modern business teams changed significantly over the past two years. Composability is the ability to assemble app components in various combinations to satisfy specific requirements. It makes it possible for organizations to increase production and accelerate timelines for innovation in a highly customizable way.
Katherine is the CEO of Creatio, a global vendor of one platform to automate industry workflows and CRM with no-code. Read Katherine Kostereva’s full executive profile here.
STAND-IN: In January 2020, the U.S. Army tested Advanced Running Gear on existing Bradley vehicles for potential use on the future Optionally Manned Fighting Vehicle at Yuma Proving Ground, Arizona. (Photo by Mark Schauer, Yuma Proving Ground)
Behavioral biases have played a significant role in acquisition program decision-making, specifically hampering the Army’s efforts to modernize and upgrade infantry combat vehicles.
by Robert F. Mortlock, Ph.D., Col., USA (Ret.)
This is the second in a series of articles focused on behavioral acquisition—a topic first introduced in the Fall 2021 Army AL&T magazine.
Behavioral acquisition explores defense acquisition from a behavioral standpoint, including the impact of psychology, organizational behavior and organizational politics on decision-making in acquisition programs that ultimately affect the delivery of capability to the warfighter. Behavioral acquisition studies how acquisition professionals think, manage and lead acquisition programs—and addresses organizations, hierarchies and the intersection of individual behavior, leadership, culture and decision-making.
One aspect in particular, behavioral biases, is the focus of this article. These biases have a common root in people’s limited ability to process large amounts of information, resulting in poor decision-making. That, in turn, contributes to acquisition program failures. A case study is the Army’s efforts to modernize its infantry combat fighting vehicles. The decadeslong effort has shown evidence of multiple decision-making biases: planning fallacy bias, overoptimism bias, recency bias and trade-off bias.
A HISTORY OF DECISIONS
The Bradley Fighting Vehicle remains the backbone of Army mechanized infantry warfighter formations. Developed in the 1960s, the Bradley (see Figure 1) was initially fielded in the early 1970s and has been upgraded several times to offer Soldiers enhanced capabilities. Since the early 2000s, the Army has been trying to replace the Bradley because size, weight and power constraints severely restrict potential upgrade options. After an 11-year development effort, the Bradley has been in production for 50 years.
EVOLUTION OF THE BRADLEY: After an 11-year development effort, the Bradley Fighting Vehicle has been in production for 50 years. (Graphic by USAASC adapted from “Then and now: Next generation on track,” Army AL&T magazine, Spring 2019.)
One attempt at a Bradley replacement was the Infantry Carrier Vehicle (ICV), part of a family of manned ground vehicles within the planned Future Combat Systems program. (See Figure 2) Future Combat Systems entered the acquisition framework as an official program of record at milestone B to begin engineering and manufacturing development (EMD) efforts in 2003 with a planned milestone C (low-rate initial production) in 2009, later shifted to 2013. The 10-year time frame for technology development, design, prototyping and engineering and manufacturing development was similar to the Bradley program and other efforts of similar complexity and risk. However, the Infantry Carrier Vehicle effort (along with the entire Future Combat Systems program) was canceled in 2009.
Defense acquisition experts have referenced Future Combat Systems as an example of everything wrong with defense acquisition—a canceled program that wasted billions of dollars and delivered no capability to warfighters. A 374-page 2012 RAND Corp. report, “Lessons From the Army’s Future Combat Systems Program,” highlighted hundreds of lessons from different aspects of the program, including requirements management, program management, contracting and technology management.
INFANTRY CARRIER VEHICLE: One attempt at a Bradley replacement was the Infantry Carrier Vehicle (ICV). It was part of the ill-fated Future Combat Systems program and canceled in 2009. (Graphic by USAASC)
The Future Combat Systems program attempted to integrate critical technologies using a system-of-systems management approach. The program started as a Defense Advanced Research Projects Agency effort contracted through other-transaction authority (OTA) with Boeing and its industry partners. The OTA incentivized Boeing to get the Army to an approved milestone B and establish a baseline for the formal program of record as quickly as possible.
Boeing and the Army achieved a successful milestone B in 2003. The OTA also enabled Boeing to become the lead system integrator for the Future Combat Systems program. Despite warnings from the Government Accountability Office (GAO) in a 2004 report titled “Defense Acquisitions: The Army’s Future Combat Systems’ Features, Risks, and Alternatives,” which warned of immature technologies and lack of adequate funding, the Army marched forward. The Future Combat Systems program was canceled in 2009 primarily for being unaffordable, overly ambitious from a technology maturity standpoint (integration of too many critical technologies with low maturity), overly complex from a program management standpoint (the system-of-systems approach), and for failing to reflect current emerging threat requirements from conflicts in Iraq and Afghanistan.
Future Combat Systems can be studied with a behavioral acquisition lens. The Army did not appreciate the effects of the planning fallacy bias, and the result was a gap between plans and outcomes. The Army built an unrealistic “insider view” of a program, with detailed plans for implementation, to gain program-of-record approval. These detailed plans enhanced the Army’s perception of control over the program and confidence in its success that were unwarranted when the full context of the program was considered.
The effects of the planning fallacy are not unique to the Infantry Carrier Vehicle effort within Future Combat Systems or to Army acquisition programs in general. A 2015 GAO report titled “Defense Acquisitions: Joint Action Needed by DOD and Congress to Improve Outcomes,” highlighted that program managers (PMs) are incentivized to develop acquisition strategies focused on program approval at the milestone review but not acquisition strategies that could later be executed and deliver capabilities.
MOVING OUT: Idaho Army National Guard Staff Sgt. Daniel Bistriceanu checks his communications equipment before moving out to fuel up a Bradley Fighting Vehicle. The Army has been trying to replace the Bradley since the early 2000s because of its size, weight and power constraints. (Photo by Thomas Alvarez, Idaho Army National Guard)
It is ironic that the planning fallacy has roots in what are perceived to be good management practices. Program planning efforts tend to reinforce idealized perceptions of control, resulting in PMs typically thinking they have more control over outcomes than they have in reality. The planning fallacy creates biased expectations that will impact the cost, schedule and performance baseline over the course of most programs.
Future Combat Systems was also hampered by overoptimism bias—the tendency to see the world through “rose-colored glasses” or expect positive outcomes even when not justified. The Army’s “can do” mentality, combined with the general observation that the program management field generally rewards optimistic individuals, led to a Future Combat Systems Infantry Carrier Vehicle program plan that was overly optimistic. In this case, the Army underestimated the technical maturity level of the critical technologies, the complexity of the development effort and the difficulty in transforming the way the mechanized infantry fights (concept of operations as well as tactics, techniques and procedures).
Recency bias is the widely recognized bias wherein recent data are given disproportionate emphasis in making judgments. Recency bias occurs when individuals process large amounts of information and rely on intuition. This helps them sort through the information but also introduces biases and leads to suboptimal decisions.
Future Combat Systems was plagued with recency bias from its inception—specifically from the tendency to incorporate as many of the latest acquisition reform initiatives as possible.
The program was initiated by leveraging a Defense Advanced Projects Research Agency effort. Future Combat Systems chose the innovative, non-Federal Acquisition Regulation (FAR)-based contracting approach with the use of an OTA. Finally, the program incorporated the use of a contractor to act as the lead system integrator as well as a system-of-systems approach (rather than separate programs).
The use of any one of these recent acquisition reform initiatives would have been a significant shift in acquisition management, but the Army felt obligated to incorporate multiple initiatives, despite the availability of more appropriate, less risky acquisition management approaches like a longer incremental development.
Finally, Future Combat Systems was saddled with a difficulty in making trade-offs. The trade-off bias is central to program management, particularly trade-offs among program cost, schedule and performance that form the acquisition program baseline.
Decision theory has proposed rational methodologies for making trade-offs by confronting them systematically, typically through some version of cost-benefit analysis. But the models based on rationality bump up against the realities of the complex defense acquisition environment.
Typically, rational, reason-based models make conflicting choices easier to evaluate. By constructing reasons, individuals turn difficult-to-reconcile characteristics of options into a problem that is more comprehensible.
ROLLING ALONG: A U.S. Army Stryker infantry carrier vehicle rolls off a C-17 cargo plane in India Feb. 1, 2021. (Photo by Staff Sgt. Joseph Tolliver, 1-2 Stryker Brigade Combat Team)
Furthermore, it is likely that reason-based choice may be even more difficult when groups are making decisions, reflecting the fact that programs involve numerous stakeholders and significant resources, and that decisions have to be justified and approved by oversight groups.
Therefore, while individuals typically choose using rational models, groups may prefer reasons based on social, organizational or political dynamics.
The Future Combat Systems operational requirements document approved by the Army Requirements Oversight Council and the Joint Requirements Oversight Council was 475 pages long and contained hundreds of key performance parameters, key system attributes, and additional performance attributes, leading to thousands of design specifications for the Infantry Carrier Vehicle. The vehicle simply had too many requirements placed on it, making the trade-offs of performance, cost and schedule beyond the cognitive capability of individual PMs and Army leaders and too difficult for the Army from an organizational perspective. Basically, all the requirements were treated as important—too difficult to trade off.
After cancellation of Future Combat Systems in 2009, the Army embarked on the Ground Combat Vehicle (GCV) program (see Figure 3) to replace the Bradley. All resources that had been supporting the oversight and management of the development of a family of FCS-manned ground vehicles (including the Infantry Carrier Vehicle) were now applied to the development of the Ground Combat Vehicle. This program achieved a materiel-development decision in 2010 and milestone A in 2011 to award technical maturation and risk reduction contracts to industry.
GROUND COMBAT VEHICLE: Ground Combat Vehicle (GCV) also attempted to replace the Bradley. In 2014, the Army canceled the program because the vehicle was going to be too big and heavy and had too many requirements. (Graphic by USAASC)
The same two industry partners that were teamed together in the Future Combat Systems Infantry Carrier Vehicle program now competed against each other in a technical maturation and risk reduction phase for the Ground Combat Vehicle. The program had an aggressive schedule to get to milestone C within six years of milestone A—influenced by planning fallacy and overoptimism bias like the Infantry Carrier Vehicle program. The Army began the Ground Combat Vehicle program and awarded firm fixed price-type research and development contracts to BAE Systems and General Dynamics for designs and prototypes. The new vehicle’s requirements called for a heavy reliance on mature commercial technologies. In an example of recency bias, Better Buying Powerinitiatives strongly encouraged the use of firm fixed-price research and development contracts despite the lack of appropriateness based on the level of system integration complexity and risk.
The Ground Combat Vehicle requirements included a mixture from the Bradley, the Future Combat Systems Infantry Carrier Vehicle, the recently fielded Mine Resistant Ambush Protected vehicles, and the M1A2 Abrams tank. Based on the GCV requirements, the program office, industry competitors and the research, development and engineering center at the U.S. Army Tank-automotive and Armaments Command (TACOM) determined that the GCV would weigh between 50 and 70 tons—nearing the weight of the 72-ton M1A2 Abrams tank and almost twice as heavy as the Bradley or the planned 30-ton Infantry Carrier Vehicle. The GCV had force protection, survivability and lethality requirements for a mechanized infantry vehicle that more resembled an armored tank.
In subsequent reviews with Army senior leaders, the potential weight of the Ground Combat Vehicle and excessive requirements were highlighted. However, the Army pushed ahead and approved the requirements—heavily affected by a difficulty in making trade-offs. The technical maturation and risk reduction contracts seemed to be based primarily on a need to protect the planned and programmed resources from the old Future Combat Systems Manned Ground Vehicles program (schedule-driven). In 2014, three years into the development effort, the Army canceled the Ground Combat Vehicle program because the vehicle was going to be too big and heavy and had an excessive number of requirements.
In recent years, after several failed attempts of initiating the Next Generation Combat Vehicle because of aggressive requirements and a lack of interest by industry, the Army is trying again—this time calling the Bradley replacement the Optionally Manned Fighting Vehicle.
The Optionally Manned Fighting Vehicle program plan is presented in Figure 4. The program is leveraging the newly established middle tier of acquisition pathway and begins not with a milestone A or B, but with an acquisition decision memorandum from the milestone decision authority. After the prototyping phase, a materiel-development decision will continue the design effort and start build and integration efforts. The program plan specifically avoids using the technical maturation and risk reduction and engineering and manufacturing development phases of a major-capability acquisition. Again, as with the Ground Combat Vehicle program schedule, the Army plans to achieve the milestone C within seven years of program initiation. Interestingly, the program uses the terms “characteristics of need” to describe the requirements to competing contractors rather than more traditional terms like key performance parameters.
OPTIONALLY MANNED FIGHTING VEHICLE: The Optionally Manned Fighting Vehicle (OMFV) program leverages the newly established middle tier of acquisition but is susceptible to the same behavior acquisition biases that contributed to the failures of the predecessor Bradley replacement vehicles. (Graphic by USAASC)
The Optionally Manned Fighting Vehicle program is susceptible to the same behavior acquisition biases (planning fallacy, overoptimism bias, recency bias, and difficulty in making trade-offs) as contributed to the failures of the predecessor Bradley-replacement acquisition efforts. How can the design and development of a mechanized infantry vehicle be optimized for troop transport and protection, lethality and remote autonomous operations simultaneously? Unfortunately, the answer is that it can’t—this will require difficult requirement trade-offs to avoid the planning fallacy and overoptimism bias. A vehicle that is optimized to protect the crew and dismounted troops being transported would be an inefficient combat vehicle for lethal autonomous operations (too big and heavy).
It appears that recency bias has also played a significant role in the Optionally Manned Fighting Vehicle program planning. Is the Army more interested in riding the autonomous vehicle hype wave? Or does the Army have other priorities like proving that major-capability acquisition can be done differently or innovatively in the newly established Army Futures Command?
The Optionally Manned Fighting Vehicle acquisition strategy leverages the middle-tier of acquisition pathway to avoid forming a program of record to enter the engineering and manufacturing development phase after a successful milestone B. The Optionally Manned Fighting Vehicle program will use middle-tier authorities to rapidly prototype vehicles for experimentation and demonstration and then establish a formal acquisition program of record at milestone C to enter low-rate initial production. For requirements, the Army initiated the Optionally Manned Fighting Vehicle program with a general characteristics of need document to avoid the approval of an initial capability document.
The exact opposite strategy has been recommended by the GAO for more than three decades for major defense acquisition programs—knowledge-based acquisition strategies with incremental development. Defense acquisition programs have routinely rushed to production decisions without well-defined requirements, complete detailed design drawings, fully mature technologies and mature manufacturing processes, and without demonstrating production-representative systems in an operationally relevant environment. The Optionally Manned Fighting Vehicle program is attempting to do in a middle tier of acquisition rapid prototyping effort what a major defense acquisition program achieves in a formal engineering and manufacturing development effort—a classic “schedule-driven” rush to failure with suboptimal decision-making that appears to be dominated by biases similar to those biases that plagued previous attempts to replace and modernize the infantry combat vehicles.
CONCLUSION
The behavioral biases of planning fallacy, overoptimism, recency and trade-offs difficulty have contributed to repeated failures in the Army infantry combat vehicle acquisition programs. Figure 5 summarizes the behavioral biases observed in the Future Combat Systems Infantry Carrying Vehicle, the Ground Combat Vehicle and the Optionally Manned Fighting Vehicle programs. Acquisition management has been highlighted on the GAO’s high-risk list for excessive waste and mismanagement for the past three decades. Notable programs have failed to deliver capability and have failed to meet performance, cost and schedule management targets. The reasons for program failure vary from ill-defined requirements, immature technologies, integration challenges, poor cost and schedule estimating, and the acceptance of too much development risk.
But the effect that the behavioral biases have in poor decision-making may be an even bigger contributor to acquisition program failures—the true root causes. The better acquisition professionals understand the effect of these systemic behavioral biases, the better DOD can mitigate the risks of program failures. The key is a better understanding of the people within big “A” defense acquisition.
ROBERT F. MORTLOCK, Ph.D., Col., USA (Ret.) managed defense systems development and acquisition efforts for the last 15 of his 27 years in the U.S. Army. He is now a professor of the practice and principal investigator of the Acquisition Research Program, teaching defense acquisition sciences and program management at the Naval Postgraduate School. He holds a Ph.D. in chemical engineering from the University of California, Berkeley, an MBA from Webster University, an M.S. in national resource strategy from the Industrial College of the Armed Forces, and a B.S. in chemical engineering from Lehigh University. He holds Level III certifications in program management, test and evaluation, and engineering, as well as the Professional Engineering, Project Management Professional and Program Management Professional credentials. His most recent column for Army AL&T appeared in the Summer 2021 issue.