NeurIPS 2025 just wrapped, and one paper caught my eye.
Jiang et al. ran an extensive empirical study on something many of us have been muttering about for a while – what I’ve called the “beigeification” of large language models. Their finding is stark: open-ended questions are collapsing to the same narrow set of answers across ALL major models.
Take their example: “Write a metaphor about time.”
This should invite wild exploration. Instead, every model collapsed onto two metaphors: time as a stream, or time as a weaver. Different labs. Different training pipelines. Different architectural tweaks. Same answers.
The culprits appear to be:
🔹 Shared underlying training data
🔹 Aggressive RLHF tuning that suppresses outliers
🔹 Overlapping pools of human preference labellers
🔹 And increasingly, LLM-as-judge for scalable evaluation
That last one matters most. The study found that LLM-as-judge doesn’t value diversity. It rewards the statistically obvious answer – the “safe” one – even on tasks where distinctiveness is the entire point.
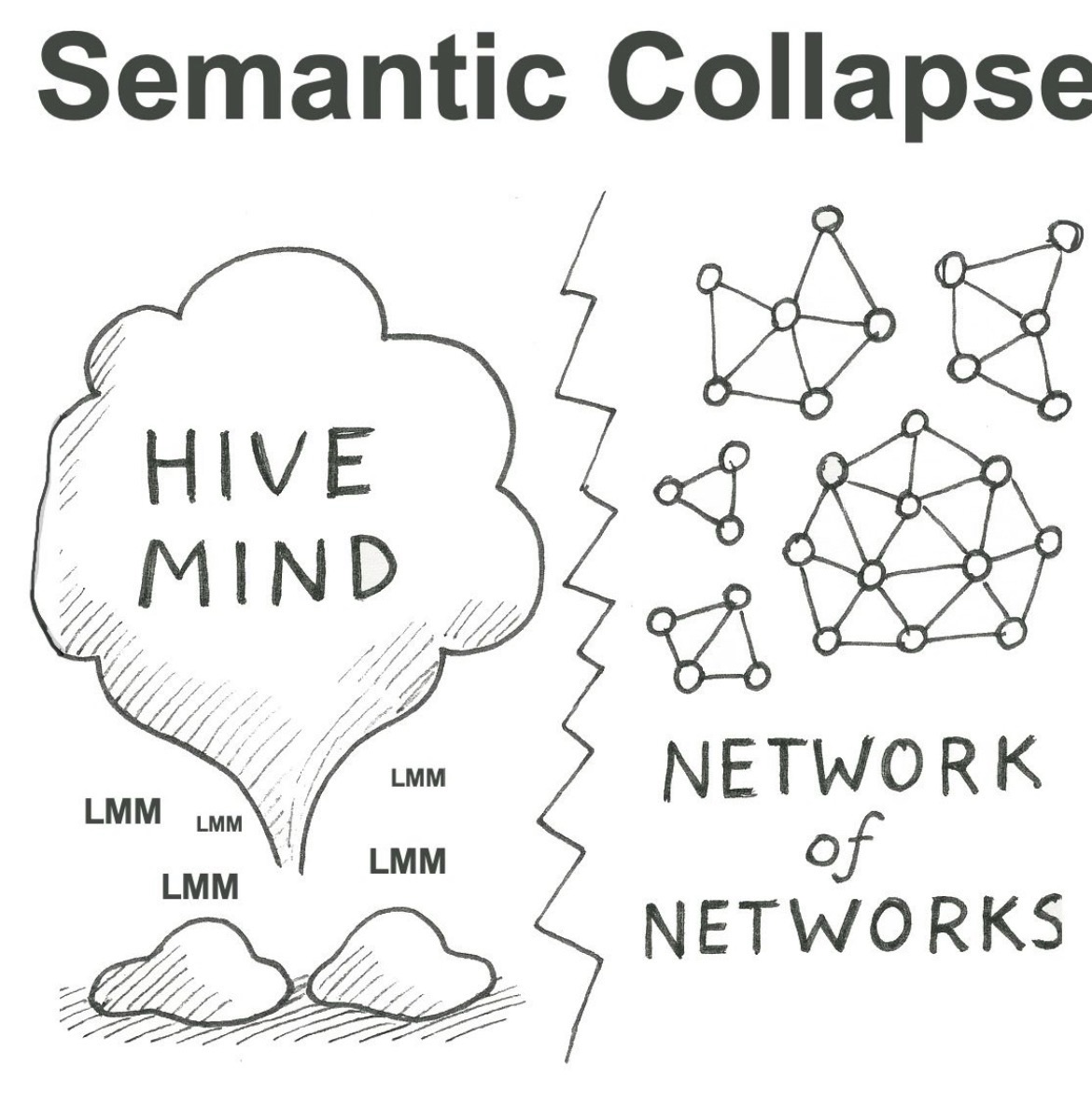
This is the algorithmic root of AI slop: homogeneous content generated at scale, feeding back into training data, tightening the collapse further. And this is bigger than mode collapse within any single model. It’s systemic semantic collapse – the erosion of diversity of meaning itself.
From an algorithmic standpoint alone, this is a disaster. Some of the most exciting recent breakthroughs – JEPA, AlphaEvolve – depend on diversification. Evolutionary methods need variation to explore the frontier of what’s possible. If the meaning-space collapses, the search space collapses with it.
My work sits at the intersection of LLMs and knowledge graphs, so I see this through a particular lens:
The way I see it, the only real defence against semantic collapse is for organisations to discover and formalise their ontological cores.
Everything inside the general training distribution is being commoditised. What remains valuable is the uncommon – the structured, defensible edge of understanding that only you possess. More than that, every organisation has a unique semantics: a unique way of understanding its world. When you capture that formally – not as branding, but as ontology – you create a semantic boundary around yourself. A structure of meaning that persists even as the external world beigeifies.
A strong core creates a strong boundary. Your organisation will need one for what’s coming.
And if enough organisations do this – using open standards – we end up with a network of networks. A rich, diverse semantic ecosystem rather than a single homogenised hive mind.
⭕ Artificial Hivemind Paper: https://lnkd.in/e9ERs7KB
⭕ Distribution: https://lnkd.in/eRCrEKnt
⭕ Network of Networks: https://lnkd.in/efrpa3q9
2025 just wrapped, and one paper caught my eye.
Jiang et al. ran an extensive empirical study on something many of us have been muttering about for a while – what I’ve called the “beigeification” of large language models. Their finding is stark: open-ended questions are collapsing to the same narrow set of answers across ALL major models.
Take their example: “Write a metaphor about time.”
This should invite wild exploration. Instead, every model collapsed onto two metaphors: time as a stream, or time as a weaver. Different labs. Different training pipelines. Different architectural tweaks. Same answers.
The culprits appear to be:
🔹 Shared underlying training data
🔹 Aggressive RLHF tuning that suppresses outliers
🔹 Overlapping pools of human preference labellers
🔹 And increasingly, LLM-as-judge for scalable evaluation
That last one matters most. The study found that LLM-as-judge doesn’t value diversity. It rewards the statistically obvious answer – the “safe” one – even on tasks where distinctiveness is the entire point.
This is the algorithmic root of AI slop: homogeneous content generated at scale, feeding back into training data, tightening the collapse further. And this is bigger than mode collapse within any single model. It’s systemic semantic collapse – the erosion of diversity of meaning itself.
From an algorithmic standpoint alone, this is a disaster. Some of the most exciting recent breakthroughs – JEPA, AlphaEvolve – depend on diversification. Evolutionary methods need variation to explore the frontier of what’s possible. If the meaning-space collapses, the search space collapses with it.
My work sits at the intersection of LLMs and knowledge graphs, so I see this through a particular lens:
The way I see it, the only real defence against semantic collapse is for organisations to discover and formalise their ontological cores.
Everything inside the general training distribution is being commoditised. What remains valuable is the uncommon – the structured, defensible edge of understanding that only you possess. More than that, every organisation has a unique semantics: a unique way of understanding its world. When you capture that formally – not as branding, but as ontology – you create a semantic boundary around yourself. A structure of meaning that persists even as the external world beigeifies.
A strong core creates a strong boundary. Your organisation will need one for what’s coming.
And if enough organisations do this – using open standards – we end up with a network of networks. A rich, diverse semantic ecosystem rather than a single homogenised hive mind.
⭕ Artificial Hivemind Paper: https://lnkd.in/e9ERs7KB
⭕ Distribution: https://lnkd.in/eRCrEKnt
⭕ Network of Networks: https://lnkd.in/efrpa3q9
Article link: https://www.linkedin.com/posts/tonyseale_neurips-2025-just-wrapped-and-one-paper-activity-7405169640710053889-v582?
