As artificial intelligence (AI) systems assume more decisionmaking roles in government, the economy, and society, a question emerges: Will humans retain the capacity to shape collective outcomes? Several theories suggest that, once human decisionmaking erodes past a certain threshold, the skills, institutions, and political standing needed to reclaim that decisionmaking capacity may no longer exist. However, no widely accepted metrics exist for tracking this erosion. In this report, the authors draw on social choice theory to develop a formal model of how AI erodes collective human agency; they also model decisionmaking in terms of coalitions and propose quantitative metrics for tracking shifts in the distribution of decisionmaking power to identify the point beyond which those shifts could become irreversible.
Key Findings
Agency erosion is measurable across domains. Three metrics—distribution of decisive coalitions, minimal coalition size, and composition of minimal coalitions—are applicable to a wide variety of decisionmaking processes. These metrics provide a framework for tracking human agency impacts across domains, comparing changes, and detecting nonlinear acceleration.
Distinct mechanisms drive agency erosion. There are three pathways through which AI reduces human agency: human disenfranchisement (fewer humans in decisionmaking roles), AI enfranchisement (AI entities gaining decisionmaking power and changing the composition of decisive groups), and AI agenda control (AI systems shaping which alternatives reach human decisionmakers to consolidate power in unintended ways).
A terminal state exists. The mathematical structure of the model identifies a formal end state of agency erosion: a single minimal coalition that is decisive for all choices. This provides a target for monitoring how far the trajectory is from this point of irreversibility.
Recommendations
Develop agency evaluations. Existing AI evaluations assess capabilities, safety, and alignment, but they do not assess structural effects on human decisionmaking. Researchers should design benchmarks that measure when AI systems reduce the number of humans in decisive coalitions, influence outcomes, or shape which alternatives reach human decisionmakers.
Establish human participation thresholds. For high-stakes domains (such as democratic governance, military applications, and critical infrastructure), policymakers should consider minimum requirements for human presence in decisive coalitions. These thresholds should reflect domain-specific requirements for legitimacy and reversibility. Organizations, such as the National Institute of Standards and Technology, could incorporate coalition composition as a measurable dimension of AI risk alongside existing metrics for reliability and security.
Monitor coalition composition longitudinally. The danger of gradual disempowerment is that no single change appears catastrophic. Organizations and governments should track the human composition of decisive coalitions across domains over time.
Benchmark reversibility capacity. Organizations should assess whether they could restore human decisionmaking if AI-driven agency loss accelerates. Doing so would require maintaining the human expertise, institutional knowledge, and deliberative infrastructure needed to reverse course.
Question How much do nonprofit hospitals spend on management consultants, and following the initiation of a management consulting contract, are there changes in hospital finances, operations, or quality of care?
Findings Nonprofit hospitals in the US (n = 2343) collectively spent more than $7.8 billion on management consulting services from 2009 to 2023. A stacked difference-in-differences design comparing 306 US nonprofit hospitals that used a management consulting firm for the first time with 513 matched hospitals that did not use a management consulting firm during the study period found little evidence of substantial, statistically significant, or systematic changes attributable to management consulting engagements.
Meaning These findings raise questions about the net value that nonprofit hospitals receive from management consulting services and call for careful examination of these contracts.
Abstract
Importance The presence of management consultants in the US health care industry has increased dramatically in recent decades and is now higher than in most other sectors of the US economy. Hospitals hire management consultants to provide external expertise and advise on strategic planning, organizational change, cost cutting, and revenue-enhancement activities. Despite the prominence and influence of these firms, there is no empirical evidence in the US documenting either how much is spent on these services or whether that spending leads to measurable improvements.
Objective To quantify nonprofit hospitals’ spending on management consultants and to evaluate changes in finances, operations, and quality of care following the initiation of a contract with a management consulting firm.
Design, Setting, and Population Observational study using a stacked difference-in-differences design to compare 306 US nonprofit hospitals that used a management consultant firm for the first time in 2010-2022 with 513 matched hospitals that did not use management consultants during 2009-2023.
Exposure First use of a management consulting firm.
Main Outcomes and Measures Financial performance (eg, revenues, expenses, margins, cash reserves, and fixed assets), operational measures (eg, inpatient utilization, staffing, executive and worker compensation, charity care, and community benefits), and quality-of-care measures (eg, claims-based 30-day mortality and readmission for acute myocardial infarction, pneumonia, and stroke).
Results More than 20% of nonprofit hospitals hired management consultants during the study period. Nonprofit hospitals that hired management consultants paid an average of $15.7 million for their services, and nonprofit hospitals collectively spent more than $7.8 billion on these services from 2009 to 2023. Despite this substantial investment, analyses of hospitals’ financial performance, operational decisions, and claims-based patient outcomes revealed little evidence of substantial, statistically significant, or systematic improvements attributable to consulting engagements. Relative changes were estimated for financial measures, such as net patient revenue (−2.22%; 95% CI, −5.11% to 0.76%; P = .14), operating expenses (−1.07%; 95% CI, −3.56% to 1.49%; P = .41), fixed assets (2.05%; 95% CI, −6.54% to 11.42%; P = .65), bad debt (−6.31%; 95% CI, −19.82% to 9.48%; P = .41), days’ cash on hand (−8.56%; 95% CI, −28.00% to 16.13%; P = .46), total margin (−0.19 [95% CI, −1.20 to 0.82] percentage points; P = .71), and operating margin (0.15 [95% CI, −0.94 to 1.23] percentage points; P = .79). Relative changes were estimated for operational measures, such as inpatient length of stay (1.71%; 95% CI, −0.34% to 3.81%; P = .10) and total inpatient days (0.29%; 95% CI, −2.57% to 3.23%; P = .85). Relative changes for quality-of-care outcomes were also generally not significant. The sole exception was 30-day readmission for patients with stroke (1.37 [95% CI, 0.14 to 2.61] percentage points; P = .03), which was not robust to alternative specifications.
Conclusions and Relevance Nonprofit hospitals expend substantial resources on management consultants, but there was no evidence of meaningful changes in hospital finances, operations, or quality of care. These findings raise questions about the net value that nonprofit hospitals receive from management consulting services and suggest the need to carefully examine the widespread use of management consultants by hospitals and other organizations across the health care industry.
Introduction
The use of management consultants in the US health care industry has grown dramatically in recent years.1Management consultants now play a larger role in health care than in most other sectors of the US economy.2 While some parts of the health care industry have long used management consultants, including pharmaceutical companies, health insurers, and other financially motivated health care organizations, management consultants are also used by nonprofit health care organizations, government-run agencies (eg, Veterans Health Administration, Centers for Disease Control and Prevention), and local public health departments.3 The growing role of management consultants in the health care sector has raised public concern, with several recent news stories linking major public health failures to management consulting firms.4–6 On one hand, these services are expensive and may have little value or even cause harm if they sacrifice care in the service of improving financial or operating performance measures. On the other hand, management consultants may provide health care organizations with valuable expertise on how to improve operational efficiency, increase revenues, set strategic direction, and generally enhance management practices.7 If they do improve management practices, the literature suggests this could ultimately improve health care delivery and quality of care for patients.8–10
Despite the increasing role of management consultants in health care, there is almost no empirical research examining how management consultants affect health care organizations. The notable exceptions are studies focused on the UK National Health Service.11–13 Even outside of health care, little is known about the effect of management consultants owing to the difficulty in observing contracts and measuring their consequences. The only research we could identify was an experimental study based in India and a contemporaneous study using Belgian tax data.14,15
We leveraged detailed tax filings for all nonprofit hospitals in the US to provide conservative estimates of spending on management consultants by nonprofit hospitals. We characterized the nature of these management consulting contracts and leveraged a difference-in-differences approach to quantify their impact on hospital finances, operations, and quality of care. This study provides the first empirical analysis of the impact that management consultants have on the US health care industry. To our knowledge, it also provides the first systematic empirical analysis of management consultants in any US industry.
Methods
This research was approved by the institutional review board at the University of Chicago. Results are reported in accordance with the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) reporting guideline for observational studies.
Data Sources
IRS Form 990
The Internal Revenue Service (IRS) requires all nonprofit entities to report detailed financial information annually, including income statements, balance sheets, and spending on key line items, such as salaries and various community benefits. Importantly, Form 990 also requires nonprofits to detail their 5 largest external contracts, which may include contracts with management consultants. Form 990 data from 2009 to 2023 were obtained from a commercial vendor, Candid.16
Medicare Cost Reports
Limitations
Hospitals accepting Medicare submit cost reports to Medicare annually. These filings are publicly available and include detailed financial and operational data, such as information on utilization, discharges, revenues, unreimbursed costs, charges, and expenses. This study used Medicare cost report data from 2006 to 2023, compiled by RAND.17
Hospital Consumer Assessment of Healthcare Providers and Systems
This study used data from the 2009-2023 Hospital Consumer Assessment of Healthcare Providers and Systems (HCAHPS), which surveys patients about their experience during an inpatient stay.18
Medicare Claims
This study used hospital claims for 100% of Medicare fee-for-service beneficiaries between 2009 and 2019 from the Medicare Provider Analysis and Review (MedPAR) files and patient-level enrollment and demographic information from the Medicare Beneficiary Summary Files. We also identified each beneficiary’s comorbidities from the MedPAR files.
S&P Capital IQ Dataset
The S&P Capital IQ dataset was used to collect financial data and market intelligence for businesses from 2009 to 2023.
Outcome Measures
We extracted the following annual financial and operational measures from Medicare cost reports: net patient revenue, operating expenses, total margin, operating margin, cash flow margin, current ratio (current assets/current liabilities), days’ cash on hand, fixed assets (land, buildings, and equipment), average inpatient length of stay, total inpatient days, Medicaid inpatient days, average worker salary, and number of employees on payroll.
We extracted the following operational outcomes from IRS Form 990 data: chief executive officer (CEO) salary, average salary of the top 5 executives, bad debt, total charity care, and total community benefits. We extracted 2 operational outcomes from the HCAHPS data: overall patient experience score and patient recommendation score. Finally, we used Medicare claims to construct 30-day mortality and readmission outcomes for patients admitted into the study hospitals with a primary diagnosis of acute myocardial infarction, stroke, or pneumonia.
Identifying Management Consulting Contracts
IRS Form 990 data were identified for 2343 nonprofit hospitals in the US (eAppendix 1 in Supplement 1). Each Form 990 includes information on the 5 highest compensated external contractors that received more than $100 000, including the amount paid and a description of the services provided. Nearly 80% of hospital-years in the sample indicate 5 or fewer contracts exceeding the $100 000 threshold. For these, the Form 990 captures all contracts above the threshold. For the remainder, there may be some management consulting contracts we did not observe because they are outside the 5 largest.
We then used information from S&P Capital IQ to determine which contractors were management consultants (eAppendix 2 in Supplement 1). The IRS Form 990 also includes a short description of each contract, which was used to exclude contracts with management consultants that were definitively not for management consulting services. For example, contracts with descriptions focused entirely on accounting and auditing services were excluded. Data were collected on other types of consultants, such as human resources consultants.
Drawing on broader management theory for why firms hire management consultants (eTable 1 in Supplement 1), we aimed to characterize the specific objective of these contracts into 1 or more of 5 categories: improving quality of care, reorganizing staffing, enhancing financial performance, integrating or advancing technological capabilities, and assisting with a merger or acquisition (eTable 2 in Supplement 1). However, as IRS Form 990 data include only a short description of each contract, we looked to news stories, public relations material, and publicly available hospital records to characterize the purpose of each contract.
Specifically, 1 analyst conducted structured web searches using both traditional search engines and artificial intelligence search tools (deep research) to identify publicly available information on the services provided (eAppendix 3 in Supplement 1). The analyst verified all information obtained by deep research against original sources. A second analyst then validated all categorizations. For contracts that could not be characterized through this process, a second analyst manually classified contract service descriptions using IRS Form 990. Classifications were independently cross-validated by a third analyst.
Statistical Analysis
Results
We used a stacked difference-in-differences estimator to assess the impact of management consultants on hospital financial, operational, and quality-of-care outcomes (eAppendix 4 in Supplement 1). This approach relies on the parallel-trends assumption that the average trends followed by matched hospitals not using management consultants approximate the average trends that hospitals using management consultants would have followed had they not used management consultants. The treatment event was defined as the first year in which a hospital was observed to contract with a management consulting firm.
We excluded treatment events in 2009 to ensure that each treatment event has at least 1 pre-event year without a management consulting contract. We also excluded treatment events in 2023 to ensure that each treatment event had at least 1 post–event year observation. We included hospitals’ observations from 4 years prior to each treatment event until 4 years after the treatment event (eAppendix 5 in Supplement 1).
To construct a valid control group, a set of matched hospitals was identified that did not use management consultants during the study period. Specifically, we identified up to 2 nonprofit hospitals not using management consultants for each hospital using management consultants by matching on total beds, total inpatient discharges, and operating margin at the start of the event window (event time −4) (eAppendix 6 in Supplement 1).
We identified 306 nonprofit hospitals with treatment events—ie, instances in which a hospital contracted with management consultants for the first time—and matched these cases to 513 hospital observations (among 404 unique hospitals) that did not use management consultants from 2009 to 2023. Conventions were followed in winsorizing all financial and operational measures at the 2.5 and 97.5 percentiles.19,20
When modeling quality-of-care outcomes at the patient level, we adjusted for patient sex, age, race, ethnicity, dual eligibility status, and Charlson-Elixhauser Comorbidity Index (eAppendix 7 in Supplement 1).
For the majority of the analysis of financial and operational outcomes, we applied a log transformation to outcomes and report regression estimates as percentage changes. For some outcomes, such as profit margins or other measures with negative values, we did not apply a log transformation, as doing so would be inappropriate.
As a sensitivity analysis, we performed the staggered difference-in-differences analyses using a Callaway and Sant’Anna estimator.21 The analysis was also performed without matching, using matching based on the full pretreatment period rather than only event time −4, and after eliminating observations during the COVID-19 pandemic. We also demonstrated the robustness of the findings to excluding large firms known for providing accounting services in addition to management consulting services, as well as to limiting the sample to short-term general hospitals. We also performed various subgroup analyses, including based on the intensity of the contract (defined as contract expenditure per hospital bed) and by the objective of the contract. Because sample sizes for analyses based on the objective of the contract were particularly small, P values were computed using a permutation test.
Reported confidence intervals and P values were not adjusted for multiple comparison testing. However, statistical significance of estimates are separately reported based on the Holm-Bonferroni adjustment for multiple comparisons using 26 tests where α = .05.
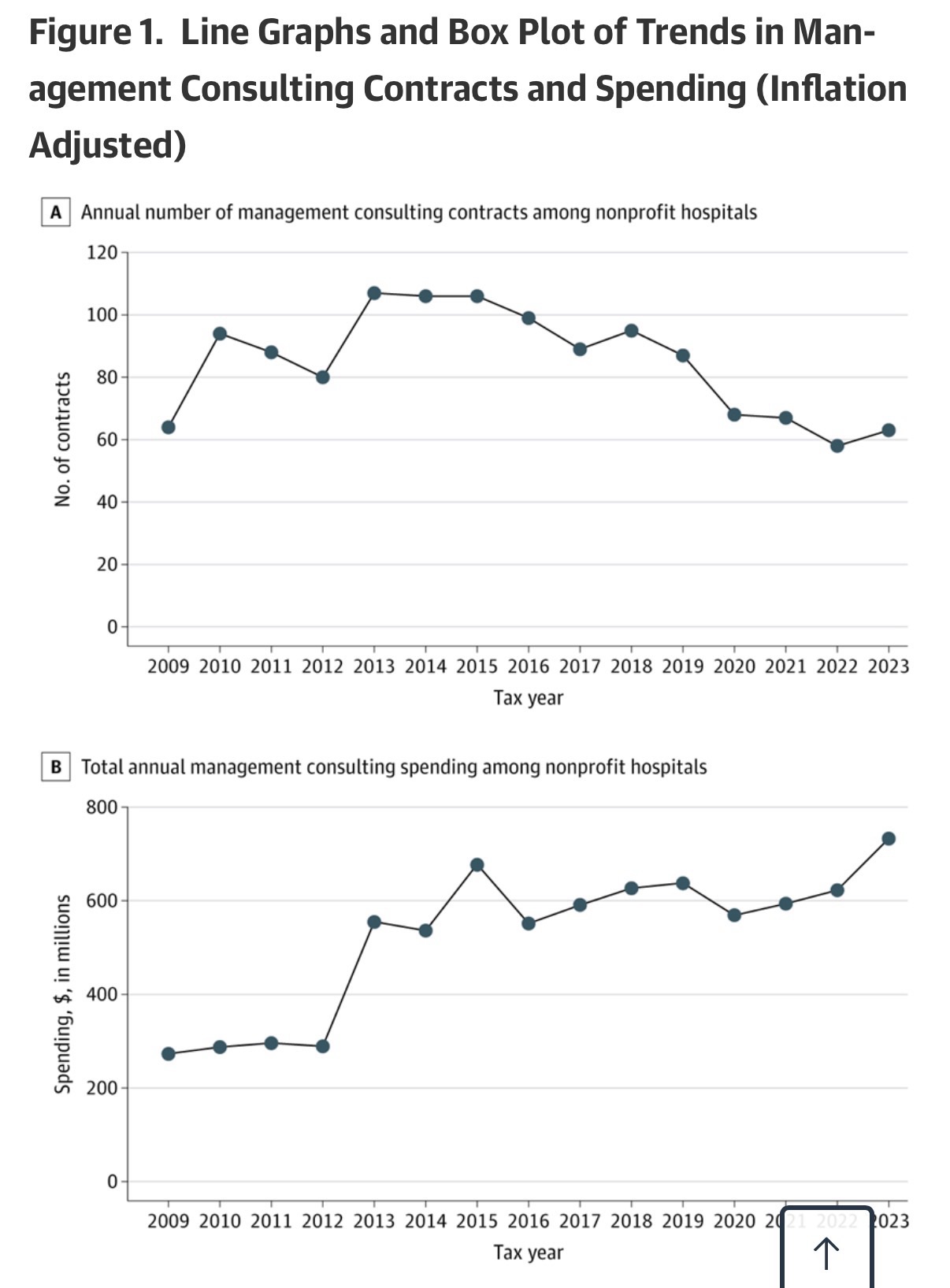
In total, nonprofit hospitals in the US (n = 2343) spent $732.9 million on management consultants in 2023, up from $273.2 million in 2009 (Figure 1). Approximately 21% of nonprofit hospitals had a management consulting contract during the study time frame, with an average of 77.5 nonprofit hospitals using management consultants each year (eFigure 1 in Supplement 1). On average, these hospitals paid $15.7 million (SD, $46.1 million) for management consulting services, with each contract costing an average of $6.2 million (SD, $14.8 million). Management consulting contracts lasted an average of 1.4 years (SD, 0.8 years), and the median number of management consulting contracts during the study period was 1.
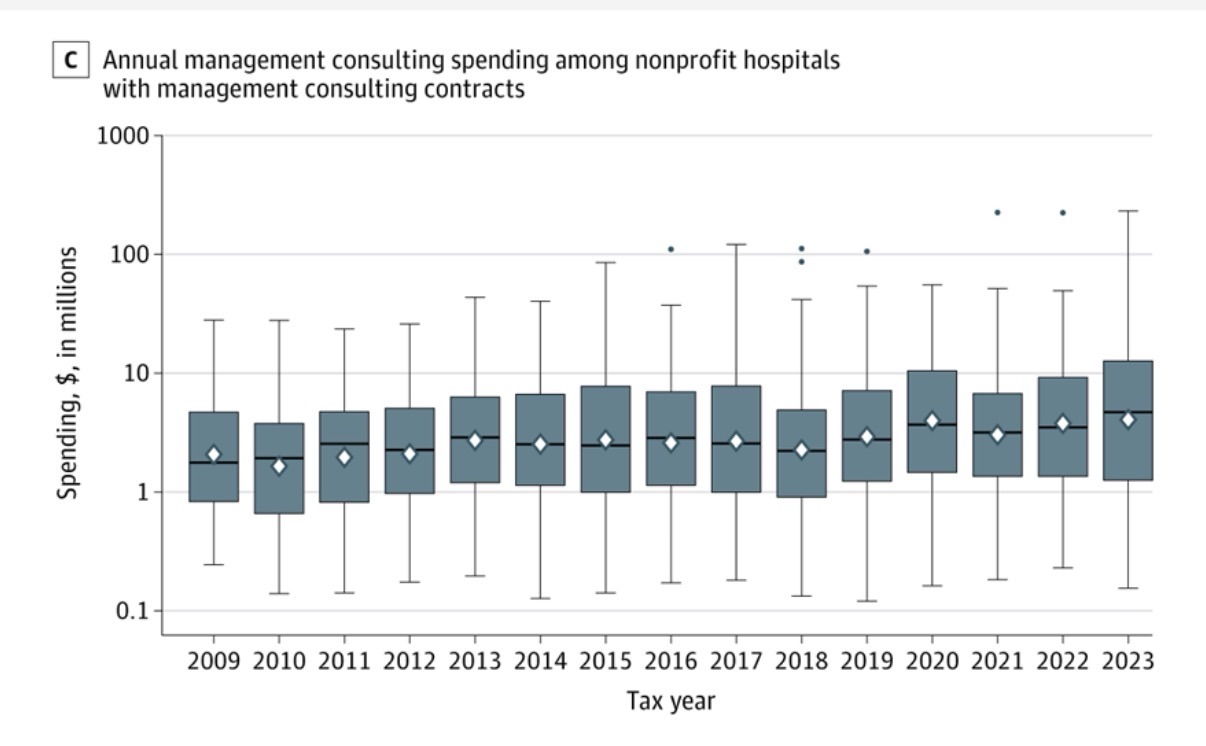
In panel A, dots connected by the line represent the total number of contracts active in each year, including both newly initiated contracts and contracts that remained ongoing from previous years. In panel C, diamonds indicate means, horizontal lines indicate medians, box tops and bottoms indicate IQRs, vertical whiskers extend to the largest and smallest observations within 1.5 times the IQRs, and observations beyond that are shown as individual points. In panels B and C, spending values are inflation adjusted to 2023 US dollars using the Consumer Price Index.
Annual spending on consultants other than management consultants also grew over the study period, from $635.4 million in 2009 to almost $1.7 billion in 2023, totaling $17.2 billion across the entire study time frame (eFigure 2 in Supplement 1). The management consulting firms that were paid the most during the study period included Deloitte ($1.2 billion), Accenture ($1.2 billion), Huron Consulting Group ($1.0 billion), PricewaterhouseCoopers ($0.8 billion), Premier ($0.6 billion), and McKinsey & Company ($0.4 billion) (eFigure 3 in Supplement 1).
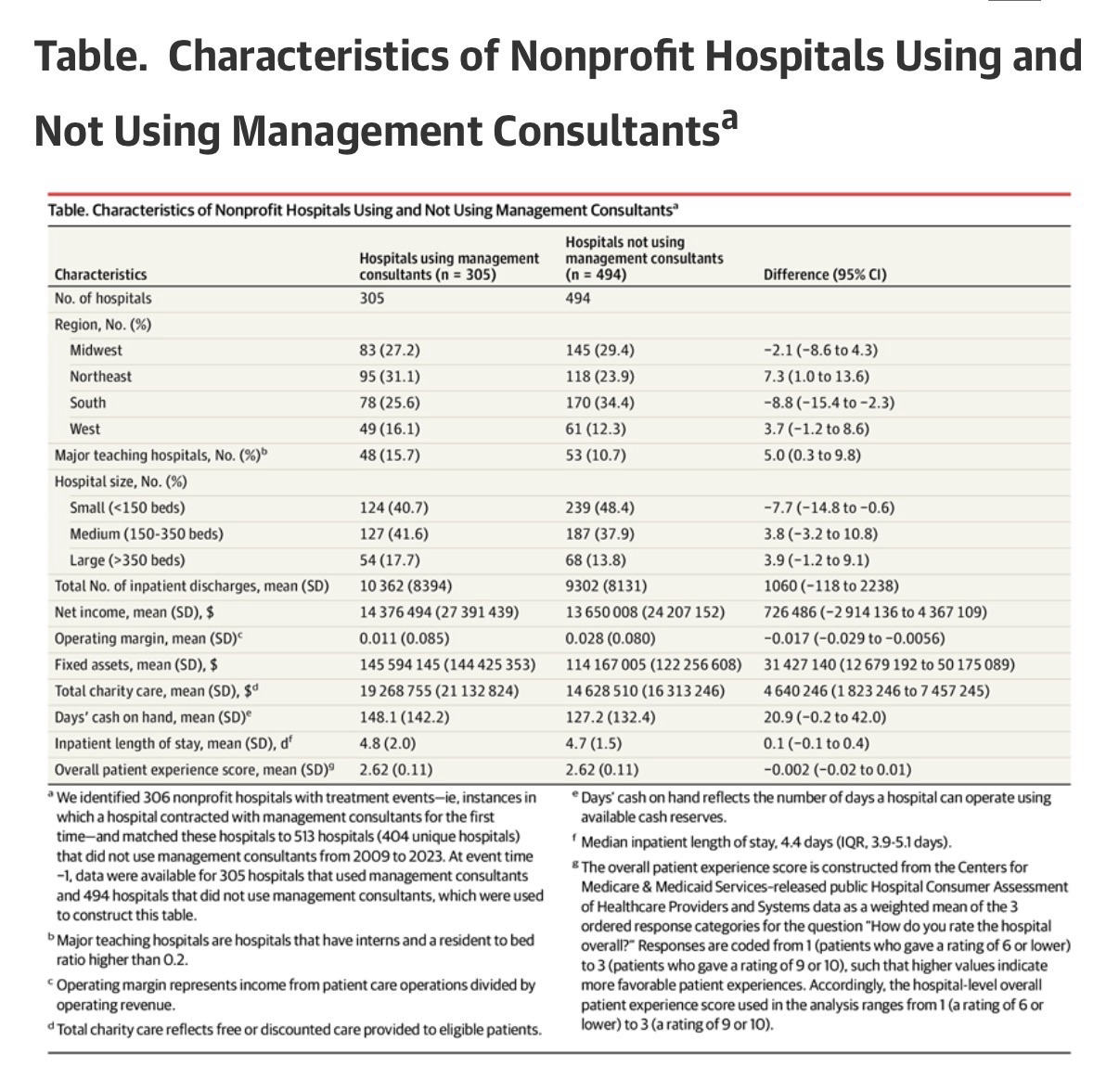
Hospitals using management consultants were geographically dispersed across the country: Midwest (27.2%), Northeast (31.1%), South (25.6%), and West (16.1%) (Table). On average, these hospitals were similar to the matched sample of hospitals not using management consultants on some dimensions, such as net income ($14.4 million vs $13.7 million, respectively; P= .70) and inpatient length of stay (4.8 vs 4.7 days, respectively; P= .36), but differed on other dimensions, such as operating margin (1.1% vs 2.8%, respectively; P= .004), charity care ($19.3 million vs $14.6 million, respectively; P= .001), and fixed assets ($145.6 million vs $114.2 million, respectively; P= .001).
The relative changes between hospitals using management consultants and those not using management consultants for all financial outcome measures were not statistically significant, including net patient revenue (−2.22%; 95% CI, −5.11% to 0.76%; P= .14), operating expenses (−1.07%; 95% CI, −3.56% to 1.49%; P= .41), fixed assets (2.05%; 95% CI, −6.54% to 11.42%; P= .65), bad debt (−6.31%; 95% CI, −19.82% to 9.48%; P= .41), days’ cash on hand (−8.56%; 95% CI, −28.00% to 16.13%; P= .46), total margin (−0.19 percentage points; 95% CI, −1.20 to 0.82 percentage points; P= .71), operating margin (0.15 percentage points; 95% CI, −0.94 to 1.23 percentage points; P= .79), cash flow margin (−0.78 percentage points; 95% CI, −2.85 to 1.29 percentage points; P= .46), and current ratio (0.02; 95% CI, −0.21 to 0.24; P= .88) (Figure 2).
After Holm-Bonferroni adjustment for multiple comparisons, no difference-in-differences estimate remained statistically significant at α = .05. Coefficients for log-transformed outcomes (panel A) were exponentiated, 1 was subtracted, and values were multiplied by 100, which were interpreted as percentage changes. Coefficients for non–log-transformed outcomes (panel B) were interpreted as estimated relative percentage point or unit changes. Median (IQR) values are reported for hospitals using consultants (treated) at relative time −1 to contextualize the magnitude of the estimated effects. Event time 0 (the treatment year) was excluded from pooled estimates to avoid partial exposure. Net patient revenue indicates total revenue from patient care services after contractual adjustments. Operating expenses reflect total costs of hospital operations. Fixed assets include land, buildings, and equipment (net of depreciation). Bad debt reflects unpaid patient care charges deemed uncollectible. Days’ cash on hand reflects the number of days a hospital can operate using available cash reserves. Inpatient length of stay represents the number of days patients remain hospitalized per admission. Total inpatient days represent aggregate days of inpatient care; Medicaid inpatient days reflect the subset attributable to Medicaid patients. Worker salary equals total salary expense divided by number of employees. Data on chief executive officer (CEO) salaries and average top 5 executive salaries were obtained from Internal Revenue Service Form 990. Total charity care reflects free or discounted care provided to eligible patients; total community benefits reflect total spending on community-oriented programs including charity care. Total margin represents overall net income divided by total revenue, and operating margin represents income from patient care operations divided by operating revenue. Cash flow margin reflects operating cash flow relative to revenue. Current ratio equals current assets divided by current liabilities and measures short-term liquidity.
Relative changes for operational outcomes were not statistically significant for almost all outcomes, including inpatient length of stay (1.71%; 95% CI, −0.34% to 3.81%; P = .10), total inpatient days (0.29%; 95% CI, −2.57% to 3.23%; P = .85), Medicaid inpatient days (−1.06%; 95% CI, −10.43% to 9.28%; P = .83), number of employees on payroll (−0.24%; 95% CI, −2.77% to 2.36%; P = .86), average CEO salary (9.25%; 95% CI, −1.28% to 20.90%; P = .09), average top 5 executive salary (−3.18%; 95% CI, −10.76% to 5.04%; P = .44), charity care (1.85%; 95% CI, −13.39% to 19.77%; P = .82), community benefit (3.10%; 95% CI, −8.64% to 16.36%; P = .62), overall patient experience score (0.00; 95% CI, −0.01 to 0.01; P = .48), and patient recommendation score (0.00; 95% CI, −0.01 to 0.01; P = .61). The only statistically significant change was a small decline in average worker salary (−1.03%; 95% CI, −2.03% to −0.01%; P = .047) (Figure 2).
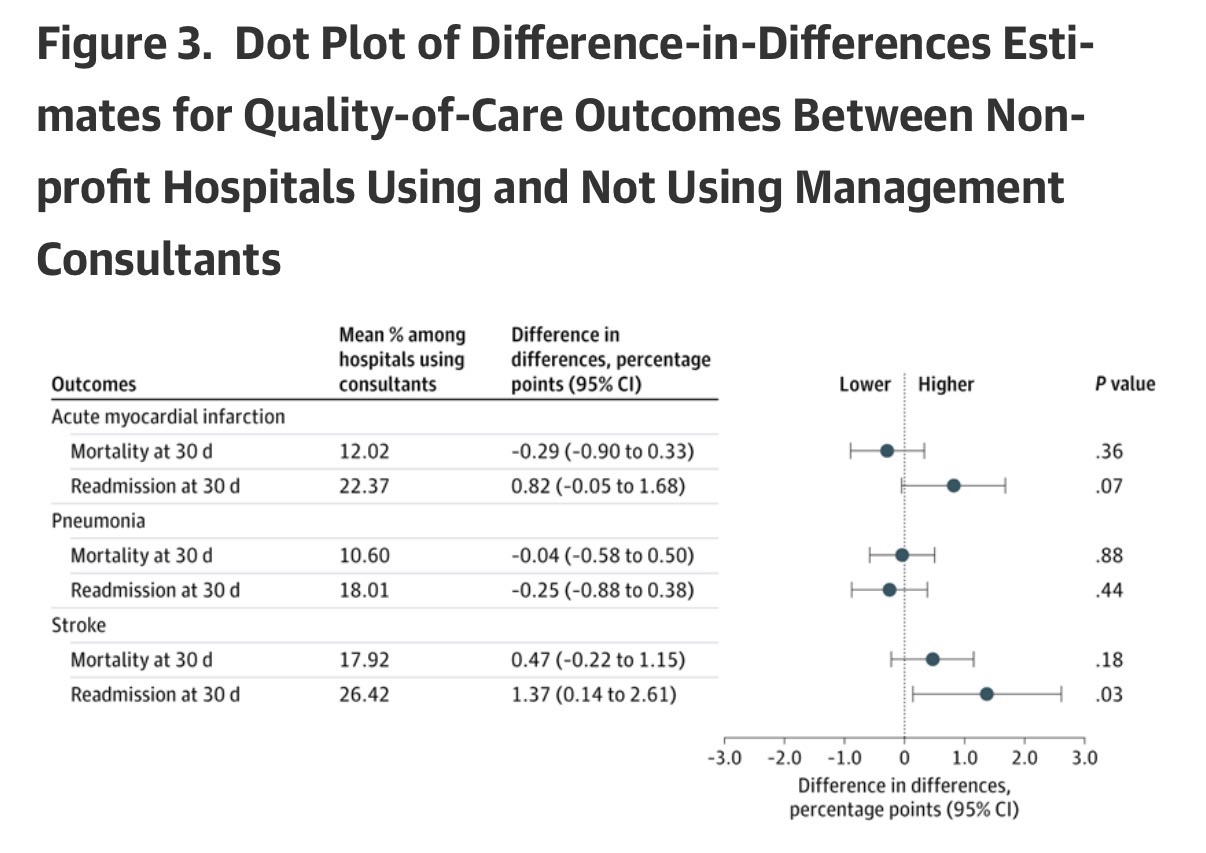
The relative changes in most patient health outcomes were not statistically significant, including 30-day mortality (−0.29 percentage points; 95% CI, −0.90 to 0.33 percentage points; P= .36) and readmission (0.82 percentage points; 95% CI, −0.05 to 1.68 percentage points; P= .07) for patients with acute myocardial infarction, 30-day mortality (−0.04 percentage points; 95% CI, −0.58 to 0.50 percentage points; P= .88) and readmission (−0.25 percentage points; 95% CI, −0.88 to 0.38 percentage points; P= .44) for patients with pneumonia, and 30-day mortality (0.47 percentage points; 95% CI, −0.22 to 1.15 percentage points; P= .18) for patients with stroke (Figure 3). The only notable exception was a relative increase in 30-day readmission for patients with stroke (1.37 percentage points; 95% CI, 0.14 to 2.61 percentage points; P= .03) (Figure 3).
After Holm-Bonferroni adjustment for multiple comparisons, no difference-in-differences estimate remained statistically significant at α = .05. Estimates represent absolute percentage point changes. Mean percentages are reported for hospitals using management consultants (treated) at relative time −1 to contextualize the magnitude of the estimated effects. Event time 0 (the treatment year) was excluded from pooled estimates to avoid partial exposure.
All financial performance, operational measures, and quality-of-care measures were not statistically significant after applying the Holm-Bonferroni method for 26 outcomes at the significance level of α = .05.
We also estimated event studies for more than 2 dozen financial, operational, and quality-of-care measures and did not find evidence of systematic divergence in trends prior to treatment (eFigures 4 and 5 in Supplement 1). This lends credence to the parallel-trends assumption underlying the difference-in-differences estimator. We also did not find evidence of preceding shocks that might bias estimates, such as CEO or board turnover or mergers/acquisitions (eFigure 4 in Supplement 1).
Estimates were also qualitatively similar when using a Callaway and Sant’Anna estimator (eFigures 6 and 7 in Supplement 1), estimating without matching (eFigures 8 and 9 in Supplement 1), matching on the average of all preperiods (event times −1 to −4) (eFigures 10 and 11 in Supplement 1), eliminating observations during the COVID-19 pandemic (eFigure 12 in Supplement 1), excluding management consulting firms known for providing accounting services (eFigures 13 and 14 in Supplement 1), restricting the sample to only short-term general hospitals (eFigures 15 and 16 in Supplement 1), and stratifying by the size of the contract (eFigures 17-20 in Supplement 1).
We were able to identify the nature of 108 management consulting contracts. Of these contracts, 64.8% were aimed at enhancing financial performance, 27.8% at integrating or advancing technological capabilities, 24.1% at improving quality of care, 13.9% at reorganizing staffing, and 13.0% at assisting in a merger or acquisition. (These objectives were not mutually exclusive.) Estimates were mostly null regardless of objective (eFigures 21 and 22 in Supplement 1).
Discussion
Hospitals’ increasing use of management consultants is emblematic of the health care industry’s trend toward corporatized behavior.22 This study shows that these practices are common even among nonprofit hospitals, at least 21.3% of which have paid contracts to management consultants in recent years. Between 2009 and 2023, these nonprofit hospitals spent $7.8 billion on management consulting services, with many contracts aimed at improving financial performance. Such large outlays have real opportunity costs—for example, among nonprofit hospitals that hired management consulting firms, the average expenditure of $15.7 million could alternatively fund the annual salaries of approximately 46 hospitalists or 167 registered nurses.23,24
Given these hospitals’ nonprofit status and their importance to communities, there is a strong public interest in evaluating the effects of their spending on management consultants. We did not find evidence of clear, statistically discernible benefits or harms to hospitals’ financial, operational, or quality-of-care outcomes from these major expenditures. It may be that changes induced by management consultants are simply too small to detect, that they affect dimensions of performance that we did not observe, or that the activities of these contracts are sufficiently varied as to make effects on any individual dimension difficult to discern. Alternatively, it may be that management consultants are primarily validating decisions or otherwise making recommendations that are very similar to what the hospital would have done without the contract.
Future research may build on and improve this study to further improve understanding of the role of management consultants in the health care industry. First, qualitative research is required to understand the precise nature of these contracts and to determine appropriate measures of benefit. Second, while large effects were ruled out in this study, future research might aim to rule out small effects as well. Third, future research might aim to study the use of management consultants by for-profit hospitals or in other parts of the health care industry, such as by local, state, and federal health agencies. Finally, this study examines only management consulting contracts, which represent just 31% of the nearly $2 billion that nonprofit hospitals spend on consultants each year. Examining other consulting contracts may be an important area for future research.
There are several limitations in this study. First, hospitals using management consultants may be on a different outcomes trajectory than hospitals that do not use management consultants. While event-study estimates do not exhibit concerning pretrends, sharp contemporaneous shocks could bias the estimates. We did not find evidence that mergers or acquisitions, CEO turnover, or board changes in the preperiod drove the results, but unobserved shocks cannot be ruled out. Notably, however, for any large bias-inducing shocks to rationalize the estimated null effects, they would need to be systematically correlated with management consultant use in a way that exactly offsets true effects.
Second, we examined only a subset of the outcomes that management consultants might plausibly affect. While this study analyzed extensive outcomes, the possibility of effects on outcomes not measured or analyzed cannot be ruled out.
Third, we studied only hospitals’ first observed contracts with management consultants. Some hospitals have multiple contracts that may occur simultaneously or in sequence. As such, the estimates are most precisely interpreted as relative changes associated with nonprofit hospitals starting to use the services of management consultants. Importantly, the results are specific to nonprofit hospitals and may not generalize to other health care settings.
Fourth, the data include only the 5 highest-paid contracts for each hospital. Although nearly 80% of hospital-years in the sample indicate 5 or fewer contracts, the remaining 20% may have some smaller management consulting contracts that were not observed.
Fifth, there was very little visibility into the exact nature of each contract. We were able to obtain some information on the objectives of 108 contracts but did not discern a clear pattern in estimates across objectives. Most notably, even for contracts aimed at improving financial performance—the largest subgroup that included 44 hospitals—we did not observe systematic differential effects, including for financial measures. In general, however, we urge caution in interpreting these subgroup analyses, as many subgroup samples were small.
Sixth, the nature of performing an extensive analysis on a modest number of contracts creates some challenges in interpreting estimates. For some outcomes, only large effects could be ruled out. In others, some differences were observed in magnitude, direction, or significance across specifications or subsamples, as is expected when testing many hypotheses and specifications in finite samples. In line with the primary findings, the most consistent pattern across sensitivity and subgroup analyses was a lack of sizeable, clear, or systematic effect.
Conclusions
Nonprofit hospitals spend considerable amounts of money on management consultants, but this study found no clear evidence of meaningful changes in hospital finances, operations, or quality of care. The findings suggest the need for further research and for careful examination of the widespread use of management consultants by health care organizations.
Article Information
Corresponding Author: Joseph Dov Bruch, PhD, Department of Public Health Sciences, University of Chicago, 5841 S Maryland Ave, Room W-250C, Chicago, IL 60637 (jbruch@bsd.uchicago.edu).
Accepted for Publication: March 23, 2026.
Published Online: May 4, 2026. doi:10.1001/jama.2026.5027
Author Contributions: Mr Fang had full access to all of the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. Additionally, Mr Zeng had full access to all of the cost report and Form 990 data in the study and takes responsibility for the integrity of these data and the accuracy of the respective data analyses.
Concept and design: Bruch, Fang, Zeng, Gandhi.
Acquisition, analysis, or interpretation of data: All authors.
Drafting of the manuscript: Bruch, Zeng, Gandhi.
Critical review of the manuscript for important intellectual content: All authors.
Statistical analysis: All authors.
Obtained funding: Bruch.
Administrative, technical, or material support: Bruch, Zeng, Parthan, Gandhi.
Supervision: Bruch, Gandhi.
Conflict of Interest Disclosures: Dr Bruch reported receipt of personal fees from the Robert Wood Johnson Foundation; receipt of grants from the Robert Wood Johnson Foundation, Rx Foundation, and Commonwealth Fund; receipt of personal fees from Adasina Social Capital through a grant from the Robert Wood Johnson Foundation; and provision of freelance consulting to McKinsey & Company from 2014 to 2017. No other disclosures were reported.
Additional Information: Perplexity AI and ChatGPT were used during 2025 to identify additional online information on nonprofit hospital contracts. Dr Bruch takes responsibility for the integrity of the content generated.
Salehnejad R, Ali M, Proudlove NC. The impact of management practices on relative patient mortality: evidence from public hospitals. Health Serv Manage Res. 2022;35(4):240-250. doi:10.1177/09514848211068627PubMedGoogle ScholarCrossref
Kirkpatrick I, Sturdy AJ, Reguera Alvarado N, Veronesi G. Beyond hollowing out: public sector managers and the use of external management consultants. Public Adm Rev. 2023;83(3):537-551. doi:10.1111/puar.13612Google ScholarCrossref
Sturdy AJ, Kirkpatrick I, Reguera N, Blanco‐Oliver A, Veronesi G. The management consultancy effect: demand inflation and its consequences in the sourcing of external knowledge. Public Adm. 2022;100(3):488-506. doi:10.1111/padm.12712Google ScholarCrossref
Chandra A, Finkelstein A, Sacarny A, Syverson C. Health care exceptionalism? performance and allocation in the US health care sector. Am Econ Rev. 2016;106(8):2110-2144. doi:10.1257/aer.20151080PubMedGoogle ScholarCrossref
In a well-publicized case that stoked public outrage, Providence, a nonprofit health system headquartered in the state of Washington, implemented a program in 2018 called Rev Up to increase revenue collection from patients.1 Following enforcement action by the state’s attorney general, Providence was ultimately forced to refund or forgive nearly $160 million worth of payments and outstanding debt,2 but not before throwing the management consultants behind the program squarely under the bus. “The intent of Rev Up, a program developed with the consulting firm McKinsey & Company, was not to target or pressure those in financial distress…We recognize the tone of the training materials developed by McKinsey was not consistent with our values.”3
Was Providence’s experience with McKinsey an outlier? In this issue of JAMA, Bruch and coauthors4 report on their systematic study of the effects associated with management consultants for nonprofit hospitals. The authors constructed an impressive database that combined detailed financial information from hospitals’ Internal Revenue Service Form 990 with measures of financial performance, operations, and outcomes for all nonprofit hospitals in the US spanning the years 2009 through 2023. In the Form 990 data, it is possible to identify most large contracts ($100 000 or more) with outside consultants and, for a subset of the contracts, to characterize the focus of the engagement.
The analysis shows that over this period, nearly one-quarter of nonprofit hospitals engaged a management consulting firm at least once, with an average total payment of about $6.2 million. In a matched comparison with otherwise similar hospitals that did not engage consultants, the analysis finds that hiring a consulting firm had essentially no effect on hospital finances, operations, or patient outcomes.
A superficial reading of these results is that on average, management consultants do not do much for nonprofit hospitals beyond consuming resources (which is, at least, not as bad as the cautionary tale of Providence and McKinsey). But there is likely more to the story.
An obvious concern with the study’s difference-in-differences approach, which the authors acknowledge and do their best to address, is that hospitals do not randomly decide to spend more than $100 000 on consulting. Hospitals that engage a consulting firm to improve financial performance are likely to include ones facing financial difficulties, which can have spillover effects on health outcomes and patient satisfaction. This would mean that the results may understate positive effects that consultants might have on outcomes. The event history analyses, which show generally similar patterns for hospitals that do and do not engage consultants prior to the start of the consulting contract, are reassuring but do not definitively rule out this type of selection bias. One productive direction for future research would be to investigate the factors that predict a hospital’s decision to hire a consulting firm.
In addition, some of the estimates have wide confidence intervals. Although it is accurate to say that the analysis shows no statistically significant improvements in finances, operations, or quality of care, for several outcomes, fairly large effects cannot be ruled out. For example, engagement of consultants may have increased or decreased Medicaid inpatient days by as much as 10%; charity care may have declined by 13% or increased by 20%; and chief executive officer salaries may have increased by as much as 20%.
The article also presents results that distinguish among different types of consulting contracts—quality of care, staffing, finances, technology, or mergers and acquisitions—for the approximately one-third of contracts for which it was possible to identify the nature of the engagement. Although the smaller sample size makes these estimates even more imprecise than the main results, drilling down into the substance of the contracts is likely a promising avenue for future research. For example, one-quarter of the contracts for which the purpose could be identified concerned “integrating or advancing technological capabilities.”4 Given the timing of the data, many of these likely involved implementing electronic health records systems in response to the 2009 Health Information Technology for Economic and Clinical Health (HITECH) Act.
On one hand, this study’s null results are in line with a research literature that finds that health care information technology has generally not delivered a large payoff in terms of greater efficiency or improved health outcomes.5 On the other hand, information technology implementation involves large initial outlays (including payments for consulting services), while the benefits may take time to be realized. And the benefits may be in specific areas that, while not reflected in aggregate data, are extremely important. For example, a study found that the implementation of electronic medical records led to a reduction in in-hospital infant mortality, driven by a reduction in deaths from conditions requiring careful monitoring.6 As a result, even successful implementation may not be evident based on the data and research design of this study. Qualitative research could be helpful to better understand the reasons that hospitals hire consultants and whether the engagement was successful in achieving specific goals.
Another important extension will be to consider spending on consultants in the context of overall administrative costs. All hospitals need someone to run them. But are consultants being used judiciously by hospitals that otherwise run a lean administrative shop? Or are consultants a symptom of administrative bloat? Again, there is likely to be heterogeneity, and the marginal value of consultant engagement may be highest at the extremes, where in-house administration is either too much or too little.
As one of the first studies of its kind, this article raises as many questions as it answers. We applaud the authors’ success in laying the groundwork for more research that can improve understanding of how nonprofit hospitals balance financial and social objectives.
Article Information
Corresponding Author: Thomas C. Buchmueller, PhD, Ross School of Business, University of Michigan, 701 Tappan St, Ann Arbor, MI 48104 (tbuch@umich.edu).
Published Online: May 4, 2026. doi:10.1001/jama.2026.4362
4. Bruch JD, Fang CC, Zeng YB, Parthan A, Gandhi AD. Changes in nonprofit hospitals’ finances, operations, and quality of care after using management consultants. JAMA. Published online May 4, 2026. doi:10.1001/jama.2026.5027 ArticleGoogle Scholar
Once, the dominant frustration among US population health experts was inaction, the nation’s failure to enact policies to improve health outcomes. Now the problem is action, the government’s adoption of sweeping policies that overtly threaten population health.
For decades, US disease and mortality rates exceeded those in other high-income countries,1 a gap that widened over time. When US life expectancy flatlined after 2010, experts recommended policies to address the leading causes of death and structural factors that systematically put the health of the US population at risk.2 They called for widening access to health care, alleviating economic stresses on low-income and middle-class households, reducing income inequality, strengthening the social safety net, and tightening regulations to protect public health.
Few of these recommendations were implemented. Such policies are politically unpopular in the US and are opposed by powerful special interests. Although the nation made some progress in addressing the drug and obesity epidemics, too little was done to address structural issues or slow the trajectory. Between 2010 and 2019, all-cause mortality at ages 25 to 64 years increased by 19.6%.3
Too little was done during the COVID-19 pandemic. Other countries outperformed the US in controlling viral transmission and vaccinating their populations. US life expectancy losses were greater than in most high-income countries.1 By 2023, 37 countries had higher life expectancy than the US.4 The high US mortality rates produced an enormous death toll. By one estimate, not having achieved the low mortality rates of peer countries cost 13.3 million US lives between 1984 and 2021.5
Actions by the Trump administration could escalate this crisis. A pivot has occurred: the nation’s inaction in addressing the US health disadvantage has been replaced by something worse, government actions that—intentionally or not—endanger population health. Since taking office, the Trump administration has done the opposite of what experts, policy research, and logic recommend to improve population health. Widening access to health care was recommended, but the Trump administration slashed Medicaid funding by more than $1 trillion and allowed Patient Protection and Affordable Care Act premiums to skyrocket.6 Tighter regulations were recommended, but the administration weakened health and safety regulations in what it called the “biggest deregulatory action in US history.”7
Education and income are the most powerful social determinants of health, but the administration began dismantling the Department of Education and adopted economic policies that tightened the vise on all but the wealthiest households. Job and wage growth slowed, prices increased, and social welfare programs were defunded to finance regressive tax cuts, what some consider the largest wealth transfer in US history.8
The administration’s Make America Healthy Again campaign took positive steps, such as working to speed approvals and lower the costs of prescription drugs. The Secretary of Health and Human Services, Robert F. Kennedy Jr, brought welcome attention to food quality. However, these positive steps occurred against the backdrop of countervailing policies that jeopardized health. The administration began dismantling the nation’s premiere health agencies, firing thousands of workers, replacing top scientists with ideologues, and terminating vital programs on disease surveillance, tobacco control, chronic diseases, injury prevention, firearms, primary care, mental health, and more. It cut medical research funding by more than $1 billion and banned work on health inequities and other topics disliked by the president.9
Secretary Kennedy took steps to decrease vaccine use, risking the return of preventable infectious diseases. Inexperienced advisors, who replaced vaccine experts on the Advisory Committee on Immunization Practices, began undoing childhood and COVID-19 vaccine recommendations. Kennedy canceled messenger RNA vaccine research, weakening the nation’s capacity to produce vaccines rapidly in future pandemics.6 Kennedy stoked parental worries about vaccine safety and encouraged states to drop school mandates for childhood immunizations. Levels of vaccine coverage and herd immunity waned.6 Measles cases reached record highs.6
It is as if the government’s policy is to no longer concern itself with the health consequences of its choices. Data collection to document the consequences is also ending. Health agencies have idled dozens of databases.10Along with cutting food assistance, the administration stopped tracking the prevalence of hunger.11 The Environmental Protection Agency stopped considering the cost of human life in cost-benefit analyses.12
This disregard for population health extends overseas. The administration banned global health research, slashed humanitarian assistance in low-income or low-resource countries, and gutted the US Agency for International Development, on which more than 100 countries depended. These actions could claim more than 14 million lives worldwide by 2030.13 Risking planetary health, the administration promoted fossil fuels and opposed climate mitigation.
To be fair, not everyone sees health as their top priority. Strengthening the economy, lowering taxes, satisfying shareholders, or retaining political office often takes precedence for those in power. Some US residents with fervent beliefs are willing to forgo health to preserve personal autonomy, limit government intrusion, or uphold other ideologic principles. The premise that the administration’s policies will compromise health is disputed. Deregulators consider market forces more effective in optimizing outcomes. Vaccine critics like Kennedy see net gain in reducing vaccine exposure; they apply a different risk-benefit calculus, assigning greater risks to vaccines and fewer benefits than conventional science would suggest. Public health has become politicized. Those who distrust data and mainstream scientists may question claims that current policies are harmful.
Evidence on how current policies are affecting health will take years to gather. Mortality data for 2025 and beyond will be unavailable until at least 2027. However, there are reasons to predict adverse health outcomes. The causal pathways are easy to imagine. Policies that do little to help people get an education, find sustainable employment, or earn livable wages diminish the resources they need to protect their health (eg, eat well, exercise, live in healthy homes and neighborhoods), screen for disease, or obtain care when illnesses occur. Reducing safety net assistance at a time of increasing prices, housing costs, health insurance premiums, and medical bills could deepen economic deprivation, forcing struggling families to neglect their health. Economic precarity and stress can heighten depression, smoking, addiction disorders, domestic violence, and self-harm.
Policies have consequences. Rural hospitals close when Medicaid funding declines. Injuries increase when safety regulations are lifted. Respiratory illnesses worsen when smokestacks emit more pollutants. Disease outbreaks widen as immunization levels wane. Deaths occur when lifesaving research is canceled. If current policies increase mortality rates, the gap in life expectancy between the US and other countries will likely widen further. The list of countries with better health statistics will grow. These are grim predictions, but a nation that removes health protections, heightens exposure to infectious diseases and toxins, slows scientific advances, and restricts access to health care should expect bad outcomes.
The degree to which the public supports, or is even tracking, these developments is unclear. Data are lacking to know how public attitudes are distributed across the population or what people understand about the health implications for themselves or their children. Some percentage of the US population is following and concerned about the tumult at health agencies and the policy drift from conventional science. Some percentage is pleased with what they see. Some are unaware, either uninformed or misinformed about recent developments. Some are disinterested, trusting the authorities to make responsible choices.
Regardless of their views, people deserve to know when policies will increase their risk of experiencing diseases, injuries, or an early death, even if they will dismiss the warning. When policies put lives at stake, health professionals and organizations must speak out. They cannot count on news organizations to keep the public informed. The duty to present the data with scientific rigor and to clarify how policy changes could help or hurt individuals falls on the health and scientific communities. Academic and scientific institutions should build coalitions to safeguard vital data and surveillance programs, conduct independent assessments that forecast the health consequences of policy choices, and communicate their concerns to legislatures, town halls, and media outlets. Although speaking out carries risks in the current climate, the duty to warn remains, even if it invites recrimination or will go unheeded. Informed consent matters. US citizens may be content to live shorter lives than people in other countries and to accept policies that further compromise their health, but they should do so knowingly.
Article Information
Corresponding Author: Steven H. Woolf, MD, MPH, Virginia Commonwealth University School of Medicine, Department of Family Medicine and Population Health, 830 E Main St, Ste 5035, Richmond, VA 23298-0212 (steven.woolf@vcuhealth.org).
Published Online: March 16, 2026. doi:10.1001/jama.2026.1396
Conflict of Interest Disclosures: None reported.
Disclaimer: The views expressed are those of the author and do not represent those of his employer.
Woolf SH. Falling behind: the growing gap in life expectancy between the United States and other countries, 1933-2021. Am J Public Health. 2023;113(9):970-980. doi:10.2105/AJPH.2023.307310PubMedGoogle ScholarCrossref
National Research Council; Institute of Medicine. US Health in International Perspective: Shorter Lives, Poorer Health. National Academies Press; 2013.
Centers for Disease Control and Prevention. About underlying cause of death, 1999-2020. Accessed January 30, 2026. https://wonder.cdc.gov/ucd-icd10.html
Bor J, Stokes AC, Raifman J, et al. Missing Americans: early death in the United States—1933-2021. Proc Natl Acad Sci U S A Nexus. 2023;2(6):pgad173. doi:10.1093/pnasnexus/pgad173PubMedGoogle ScholarCrossref
Jacobs JW, Booth GS, Brewer NT, Freilich J. Unexplained pauses in Centers for Disease Control and Prevention surveillance: erosion of the public evidence base for health policy. Ann Intern Med. Published online January 27, 2026. doi:10.7326/ANNALS-25-04022PubMedGoogle ScholarCrossref
Cavalcanti DM, de Oliveira Ferreira de Sales L, da Silva AF, et al. Evaluating the impact of two decades of USAID interventions and projecting the effects of defunding on mortality up to 2030: a retrospective impact evaluation and forecasting analysis. Lancet. 2025;406(10500):283-294. doi:10.1016/S0140-6736(25)01186-9
This year’s report, which dropped today, is full of striking stats. A lot of the value comes from having numbers to back up gut feelings you might already have, such as the sense that the US is gunning harder for AI than everyone else: It hosts 5,427 data centers (and counting). That’s more than 10 times as many as any other country.
There’s also a reminder that the hardware supply chain the AI industry relies on has some major choke points. Here’s perhaps the most remarkable fact: “A single company, TSMC, fabricates almost every leading AI chip, making the global AI hardware supply chain dependent on one foundry in Taiwan.” One foundry! That’s just wild.
But the main takeaway I have from the 2026 AI Index is that the state of AI right now is shot through with inconsistencies. As my colleague Michelle Kim put it today in her piece about the report: “If you’re following AI news, you’re probably getting whiplash. AI is a gold rush. AI is a bubble. AI is taking your job. AI can’t even read a clock.” (The Stanford report notes that Google DeepMind’s top reasoning model, Gemini Deep Think, scored a gold medal in the International Math Olympiad but is unable to read analog clocks half the time.)
Michelle does a great job covering the report’s highlights. But I wanted to dwell on a question that I can’t shake. Why is it so hard to know exactly what’s going on in AI right now?
The widest gap seems to be between experts and non-experts. “AI experts and the general public view the technology’s trajectory very differently,” the authors of the AI Index write. “Assessing AI’s impact on jobs, 73% of U.S. experts are positive, compared with only 23% of the public, a 50 percentage point gap. Similar divides emerge with respect to the economy and medical care.”
That’s a huge gap. What’s going on? What do experts know that the public doesn’t? (“Experts” here means US-based researchers who took part in AI conferences in 2023 and 2024.)
I suspect part of what’s going on is that experts and non-experts base their views on very different experiences. “The degree to which you are awed by AI is perfectly correlated with how much you use AI to code,” a software developer posted on X the other day. Maybe that’s tongue-in-cheek, but there’s definitely something to it.
The latest models from the top labs are now better than ever at producing code. Because technical tasks like coding have right or wrong results, it is easier to train models to do them, compared with tasks that are more open-ended. What’s more, models that can code are proving to be profitable, so model makers are throwing resources at improving them.
This means that people who use those tools for coding or other technical work are experiencing this technology at its best. Outside of those use cases, you get more of a mixed bag. LLMs still make dumb mistakes. This phenomenon has become known as the “jagged frontier”: Models are very good at doing some things and less good at others.
The influential AI researcher Andrej Karpathy also had some thoughts. “Judging by my [timeline] there is a growing gap in understanding of AI capability,” he wrote in reply to that X post. He noted that power users (read: people who use LLMs for coding, math, or research) not only keep up to date with the latest models but will often pay $200 a month for the best versions. “The recent improvements in these domains as of this year have been nothing short of staggering,” he continued.
Because LLMs are still improving fast, someone who pays to use Claude Code will in effect be using a different technology from someone who tried using the free version of Claude to plan a wedding six months ago. Those two groups are speaking past each other.
Where does that leave us? I think there are two realities. Yes, AI is far better than a lot of people realize. And yes, it is still pretty bad at a lot of stuff that a lot of people care about (and it may stay that way). Anyone making bets about the future on either side should bear that in mind.
Let us begin with the Japanese dentist. Not a specific dentist. The concept. In Japan, you make an appointment, you see the dentist, you pay a modest fee that the national insurance has already negotiated, and you go home. The appointment was on time. The equipment was current. The dentist went to medical school without accumulating the debt load of a medium-sized house. This is not a utopia. Japan has its own healthcare problems, mostly involving an extremely old population and a hospital system that is at capacity. But the dentist was on time.
Now let us describe the British experience of the same dentist. There are not enough NHS dentists. This has been true for a decade and is getting worse. In 2023, 26% of people in the UK skipped dental care because of the cost, compared to just 6% in 2013. The people who wanted NHS dental appointments and could not get them because there were no appointments available had a choice: pay privately, which is expensive enough that a significant number of people did not do it, or fly to Turkey. They flew to Turkey. More than 1.2 million people from Europe visit Turkey annually for surgical procedures. Search volume for cosmetic surgery Turkey from UK users grew 500% between 2015 and 2023. Turkey’s health tourism revenue reached a record 10 billion dollars in 2024. The NHS then spent up to 20,000 pounds per patient managing the complications that some of them brought home. The NHS is paying for the sequel to a film it refused to produce.
This essay is about the global healthcare system, which is not a single thing but which has a very clear hierarchy of functioning. At the top are countries where healthcare works. At the bottom are countries where it demonstrably does not. And in the middle is a specific group of English-speaking countries that were once considered among the more enlightened models on earth, that made a series of structural decisions in the 1980s and 1990s, and that are now producing wait times, outcomes, and access failures that belong in a much lower tier than their GDP per capita would suggest. They planted the seeds thirty years ago. They are currently eating the harvest and calling it a crisis, which is what happens when you eat the harvest of seeds you planted and are surprised.
The Countries Where It Works. And the Specific Reason It Works There.
Japan’s healthcare system spends approximately 4,100 dollars per capita per year. Life expectancy is 84.6 years, the highest of any large economy. Infant mortality is 1.9 per 1,000 live births, among the lowest on earth. Out-of-pocket spending is 9% of total health expenditure. The system covers 100% of the population through a universal fee-schedule based insurance model. Administrative waste is kept to under 10% of total costs. Japan does not have a particularly simple system, it has multiple insurers, multiple payers, complex regional structures, but it has one thing that prevents complexity from becoming corruption: the government sets the fees. Every procedure has a nationally negotiated price. Nobody can charge more. Nobody can charge less. The market forces that would otherwise allow prices to detach from reality have been removed from the equation by design.
This is the thing that makes Japan’s model hard to copy and easy to explain. The price is the price. A hospital cannot charge more for an appendectomy because it is the only hospital in the region. A pharmaceutical company cannot charge 40 times more for a drug in Japan than in France because it needs to fund American marketing campaigns. The price is the price. The system has costs, mostly related to an ageing population stretching a fixed infrastructure, but the fundamental mechanism works because the fundamental mechanism is not permitted to be exploited.
Germany spends 12.7% of GDP on healthcare. Japan spends about 11%. The United States spends about 18%. Japan gets a life expectancy of 84.6 years. The US gets 76.4. Germany gets 81.1. These are not small differences. These are years of life per person that are simply not being lived in the country spending the most money. The US healthcare system is the most expensive in the world and produces outcomes that rank 69th globally. This is the same rank as countries with a fraction of the per capita spending. The graph of money versus outcomes for the United States looks like a child drew it.
Singapore is a slightly different model but produces a comparable result. It blends mandatory savings accounts, called MediSave, with government subsidies and a competitive private market. Life expectancy is 83.5 years. Patient satisfaction is 89%. Out-of-pocket spending averages 10% of total health costs, among the lowest for a high-income economy. Administrative waste is under 5%. Singapore ranks first for healthcare efficiency globally on multiple indices. The specific insight Singapore applied is that the government negotiates drug prices directly, which keeps medication costs low, and that the savings account mechanism means people have a personal financial stake in not overusing the system, without creating the American problem where fear of cost prevents people from using it at all. This balance is genuinely difficult to strike and Singapore mostly struck it.
South Korea, Taiwan, and the Netherlands produce similar results through similar philosophies: universal coverage, centrally negotiated prices, strong primary care as the first line, and administrative systems that are designed to serve the patient rather than to serve the administrative system. The Numbeo Healthcare Index for 2026 places Taiwan first, South Korea second, and the Netherlands third. The United States is not in the top 60. This is the country that spends the most money on healthcare, producing outcomes that rank 69th globally, which would be an extraordinary satirical invention if it were not a publicly verifiable fact.
The countries where healthcare works have a common feature. The price is controlled. Not by market forces, which left to their own devices in healthcare produce the American result. By governments that understood the information asymmetry problem, decided to address it rather than celebrate it, and built pricing mechanisms that prevent the extraction of maximum value from someone who is sick and has no alternative. This is not complicated. It required political will. The countries that applied it are, by outcome measurement, better places to have a body.
The English-Speaking Countries. A Separate Category of Avoidable Failure.
There is a specific phenomenon happening in the United Kingdom, Canada, Australia, and New Zealand that deserves its own section, because it is distinct from both the successful models described above and from the American catastrophe that gets most of the attention. These countries built functional universal healthcare systems in the mid-20th century. They built them well. They worked. And then, beginning in the 1980s and accelerating through the 1990s and 2000s, they made a series of structural decisions that have been slowly dismantling what they built while maintaining the name, the logo, and the political rhetoric.
Canada’s median wait time from referral by a general practitioner to specialist consultation to actual treatment in 2025 was 28.6 weeks, the second-longest ever recorded by the Fraser Institute in 30 years of tracking this data. That is seven months. For non-emergency treatment of conditions that are nonetheless affecting your quality of life, potentially your ability to work, potentially your ability to function. Seven months is what Canada produced with its universal healthcare system in 2025. Canada consistently ranks in the bottom tier of OECD countries for wait times despite spending 12 to 13% of GDP on healthcare, which is broadly comparable to Germany and Japan and Switzerland, all of which produce dramatically shorter waits. The money is going somewhere. It is not going to making treatment faster.
The United Kingdom’s National Health Service is a system that inspires genuine love and genuine despair in roughly equal proportions. In 2023, 61% of people in the UK reported waiting more than 4 weeks for a specialist appointment. That number was 14% in 2013. In one decade, a wait that affected one in seven people now affects three in five. 19% waited more than a year for non-emergency surgery. The NHS has 121,000 full-time equivalent staff vacancies. It has a 7.5% nursing vacancy rate. It has a dental crisis so severe that it is functionally creating a market for Turkish dentistry. The NHS was not always like this. The NHS spent decades being one of the more functional health systems on earth. The current situation is the result of specific policy decisions about funding, privatisation, outsourcing, and staffing that were made in the 1980s and 1990s and whose consequences are being harvested now.
Australia’s Medicare system is genuinely good by many measures, and the Australians are right to value it. The rural access problem is real and documented. The private insurance two-tier issue, where those who can afford private insurance access a faster and better-equipped system while those who cannot wait longer for public care, is a structural equity problem that has been growing since the Howard government’s incentive structures pushed people toward private insurance in 1997. The same incentive, applied at the same moment, by the same ideology, in multiple countries simultaneously. The English-speaking world had a shared political consensus in the 1990s about what healthcare should look like. That consensus has produced shared results. The results are not good.
New Zealand’s system has particular problems with primary care access. The general practitioner visit costs money in New Zealand in ways that it does not in Japan or Germany, which creates the same deterrence effect that the American system produces at scale, just at a lower level of severity. The deterrence means people do not see a doctor when a small problem is manageable. The small problem becomes a large one. The large one is addressed in an emergency department, which is expensive, which creates the same cost spiral that every system experiences when it prices primary care out of reach.
The English-speaking healthcare systems have a common problem that is distinct from the American problem and the Japanese solution. They built the architecture of universal care and then introduced market mechanics into the wrong parts of it. Fee structures, outsourcing, private participation incentives, workforce decisions driven by cost reduction rather than service capacity. The result is systems that are philosophically universal and operationally fragmented. They have the brand of Japan’s model without the discipline. They have the spend of America’s model without the innovation. They have produced a generation of patients who are technically covered and practically waiting.
Turkey. South Korea. The Countries That Saw a Gap and Built an Industry.
Here is the uncomfortable observation about medical tourism. It is not a story about adventurous individuals taking a calculated risk for a cheaper procedure. It is a story about the systematic failure of healthcare systems in wealthy countries creating demand that other countries are efficiently serving. Turkey did not build a 10 billion dollar health tourism industry by accident. It built it by correctly identifying that the UK could not provide timely dental care, that Canadians were waiting seven months for procedures, that Germans and Dutch and Scandinavians could access faster or cheaper options by flying four hours, and that people with money and a health problem and a long waiting list will spend that money somewhere. Turkey simply made itself that somewhere.
The numbers are striking. More than 1.2 million Europeans visited Turkey annually for surgical procedures as of 2024. Turkey’s health tourism revenue of 10 billion dollars in 2024 was generated at an average spend of 5,000 to 10,000 dollars per visitor. These are not budget travellers picking a destination on price alone. These are people with a medical need and the financial capacity to address it, who have calculated that flying to Istanbul and returning in a week is better than waiting seven months in their home country for a procedure that their home country is nominally obligated to provide.
South Korea has built a comparable industry but at the higher end of the quality spectrum. The K-beauty cultural phenomenon, which positioned Korean aesthetics and Korean medical standards as aspirational globally, has created a medical tourism market for cosmetic surgery and aesthetic medicine that attracts patients from China, Japan, Southeast Asia, the Middle East, and increasingly North America and Europe. South Korean clinics offer rhinoplasty, facial contouring, skin treatments, and complex aesthetic procedures with wait times measured in days and costs measured at 50 to 70% below comparable procedures in Western markets. Seoul’s Gangnam district has a higher density of plastic surgery clinics than any comparable area on earth. This is not incidental. It is a deliberately constructed industry responding to genuine global demand.
Malaysia has emerged as the preferred destination for Middle Eastern and South Asian patients who want Western-standard care at Asian prices, close to home, in a Muslim-majority country with English-speaking medical staff. Kuala Lumpur’s private hospital sector is accredited to international standards, priced at a fraction of Singapore or the Gulf’s premium facilities, and offers procedures from cardiac surgery to fertility treatment to oncology at price points that make flying there economically rational even for patients from wealthy countries. Malaysia’s medical tourism sector processed over a million patients in 2024 and continues to grow.
The logic is identical everywhere. A wealthy country’s healthcare system has a gap: in affordability, in access, in waiting time, in the specific procedure offered. Another country identifies the gap, builds the infrastructure to serve it, prices it appropriately, and captures the spend that the first country’s system was unwilling or unable to retain. This is how markets work. The irony is that the countries being bypassed are the ones that most loudly advocate for market solutions to healthcare problems. The market has spoken. The market says go to Istanbul.
The sequel cost is the part that the receiving healthcare systems prefer not to discuss. Bangor University research found that complications from medical tourism cost the NHS between 1,058 and 19,549 pounds per patient, with an average hospital stay for complications of 17 days, the longest being 45 days. The NHS is not only failing to provide timely dental care. It is paying to manage the consequences of that failure when the people it failed go abroad and return with complications. This is the structural logic of a system eating itself. The failure creates demand that goes elsewhere. The elsewhere creates complications. The complications come back. The complications cost more than the original failure would have cost to prevent.
The Philosophical Question That Is Also a Numbers Question.
The standard defence of the NHS, of Canadian Medicare, of Australian Medicare, of every struggling universal system, is that universal coverage is a moral achievement even if the execution is imperfect. This is true. Universal coverage is genuinely a moral achievement. The question worth asking is what universal coverage means when the waiting time for a specialist is seven months, when dental care is effectively inaccessible to a quarter of the population, when 19% of people wait more than a year for non-emergency surgery.
Japan covers 100% of its population. Singapore covers 100% of its population. Germany covers 100% of its population. Taiwan covers 100% of its population. These countries also have better outcomes, shorter wait times, lower costs per capita, and higher patient satisfaction than the English-speaking universal systems. The moral achievement of universal coverage does not require the operational failures that are being treated as inevitable consequences of providing that coverage. They are not inevitable. They are the result of specific decisions about funding, about pricing, about workforce, about the relationship between public and private provision, and about whether the system’s purpose is to serve patients or to serve the administrative and commercial interests that have grown up around patient care.
The United States is the clearest case of what happens when those commercial interests are given full authority. 18% of GDP. 69th globally in outcomes. A prior authorisation system where insurance companies employ physicians whose entire job is to deny the treatments that other physicians have prescribed. Pharmaceutical companies making 40% of their global revenue from 4% of the world’s population. A hospital consolidation process so advanced that private equity has created local monopolies in enough regions that patients have no alternative but to use the overpriced facility that has captured their geography. The US case is not a cautionary tale. It is the result of a deliberate and sustained policy of allowing commercial interests to dominate a market that does not behave like other markets because the consumer cannot shop around while dying.
The English-speaking universal systems are not the American system. But they have been moving toward it incrementally for thirty years. The outsourcing decisions. The private finance initiative contracts that locked public hospitals into expensive long-term arrangements with private providers. The two-tier incentive structures that pushed people toward private insurance. The workforce decisions that capped medical training places to protect income levels. The lobbying by various professional groups that turned healthcare administration into a growth industry while the number of actual clinicians relative to population fell. These are American decisions applied at a smaller scale. They produce American results at a smaller scale.
The countries that solved healthcare did not solve a medical problem. They solved a political economy problem. They decided who would be allowed to profit from illness, to what extent, and in what parts of the system. Japan and Singapore and Taiwan answered that question clearly and consistently. The English-speaking universal systems answered it less clearly, more inconsistently, in response to electoral cycles and industry lobbying rather than system design. The harvest is being eaten now. Seven months in Canada. Turkey teeth. Nineteen percent waiting a year for surgery. It is exactly what was planted.
What the Working Models Tell Us. And Why Nobody Copies Them.
There is a specific frustration in the global healthcare discussion, which is that the working models exist, have existed for decades, produce documented superior outcomes at comparable or lower cost, and are not copied. The reason they are not copied is not that they are too complex to replicate. Japan’s fee schedule model is well documented. Singapore’s 3M system is published. Germany’s regulated multi-payer model is publicly studied. The reason they are not copied is that copying them requires removing the profitability from the parts of the healthcare system that are currently most profitable, which are the parts that do not provide patient care.
The American private insurance industry generates several hundred billion dollars in annual revenue. A significant portion of this revenue is generated by the administrative machinery that exists between the patient and the physician: the prior authorisation system, the claims processing system, the appeals system, the legal system that defends denied claims, the consulting industry that advises on navigating the system. This machinery employs hundreds of thousands of people. It contributes to GDP. It lobbies Congress with approximately 750 million dollars per year to maintain the conditions that justify its existence. Removing it would require replacing it with something simpler, which would be better for patients and worse for the people currently employed to make the system complicated.
The NHS has a different but structurally analogous problem. The market mechanisms introduced into the NHS over thirty years have created internal markets, commissioning groups, procurement systems, outsourcing contracts, and quality monitoring frameworks that employ a large number of people who are not clinicians but whose existence depends on the NHS remaining complex enough to require their services. Simplifying the NHS would require acknowledging that complexity, and the employment it generates, is itself a cost with no patient care return. This is politically painful in a different way from the American political pain but produces the same result: the system that works for patients cannot be built because too many people are employed by the system that does not.
Japan avoided this by building the system before the administrative class had an opportunity to colonise it. Singapore avoided this by building the system with explicit constraints on what private profit could be extracted from it. South Korea avoided it through a combination of strong state architecture and a cultural consensus that healthcare outcomes mattered more than healthcare industry profits. The English-speaking countries built their systems in an era when these protections seemed unnecessary, watched the administrative class arrive and expand, and are now in the position of trying to remove it while it employs enough people to vote.
This is not a counsel of despair. It is a description of the mechanism. The mechanism can be changed. Simple antitrust enforcement in hospital consolidation. Transparent price-setting for common procedures. Workforce expansion to match population growth rather than to protect existing income levels. Primary care investment that reduces emergency department overload. These are not radical interventions. They are the normal maintenance of a system that stopped being maintained. The Japanese health ministry performs this maintenance continuously. The NHS maintenance budget was cut in the name of efficiency. The efficiency delivered 19% waiting more than a year for surgery and a medical tourism market worth 10 billion dollars in Turkey.
The final word belongs to the patient. Not the patient as a statistical unit in a healthcare quality index. The patient who checked their bank account before making the appointment. The Canadian who waited 28.6 weeks. The British person who flew to Istanbul for the teeth their NHS said could not see them for months. The Australian in a rural postcode whose nearest specialist is four hours away. The American who did not go to the doctor because the deductible was the rent. These people are not data points in a policy debate. They are the people the system was built for. The gap between what the system says it does and what it delivers to these specific people is where the cynicism earns its place. And where the accountability for the decisions of the 1990s should also live.
AI may accelerate work, but it can’t lead people. MIT SMR columnist Benjamin Laker suggests leaving the mechanical tasks to artificial intelligence so that you can focus on the meaningful work — the work that requires the management skills at which humans excel. Rely on your own judgment to deliver messages and make decisions involving values, relationships, or trust, he advises. That’s your job as a manager, and a responsibility that should not be outsourced to AI.
AI PROMISES TO MAKE MANAGERS more productive and give them access to more information more quickly. It can draft plans, summarize reports, and even coach you on how to deliver feedback. Yet the same technology that accelerates decision-making can also erode your judgment, if you let it. Rely on artificial intelligence too little, and you miss its advantages. Rely on it too much, and you risk delegating your thinking instead of sharpening it.
Leading well in the age of AI is about balance. You need to know when to let algorithms lighten the load — and when to carry the weight on your own shoulders so your judgment stays strong.
Where AI Helps You Think Faster
AI excels at compressing time. It can scan vast quantities of information, synthesize key points, and produce first drafts of documents or presentations in seconds. Used wisely, AI accelerates the slowest parts of managerial work: gathering data, preparing materials, and finding patterns.
When time is tight, use AI to handle the groundwork so that you can focus on sensemaking. Let it outline a report so that you can spend your energy on the real managerial work: deciding what findings matter, what signals to prioritize, and what the implications are for strategy or next steps. Have it summarize team feedback so that you can concentrate on what action to take. Use it to prepare talking points for a performance review, and then spend your time planning your tone and delivery. This keeps you in the driver’s seat of decisions rather than buried in prep work.
The key is to treat AI’s output as raw material, not finished work. Skim it, shape it, and then make it yours. If you publish or present it exactly as generated, you are not accelerating your thinking — you are bypassing it. The goal is speed with discernment, not speed alone.
Where AI Can Quiet Your Judgment
The danger comes when speed begins to replace scrutiny. AI makes suggestions confidently, even when they are shallow or wrong. It can lull you into skipping the second look you would normally take, which will dull your judgment over time.
This risk of using AI is highest when you are making decisions that depend on values, nuance, or relationships — precisely the work that defines good management. AI cannot sense the emotional weight of a change announcement, the politics around a promotion, or the fragility of a struggling employee’s confidence. It will give you an answer with no sense of the human context.
In hiring, for example, AI can short-list resumes in seconds, but it cannot gauge a candidate’s resilience based on how they talk about a setback during an interview. When it comes to strategy development, AI can surface competitive trends, but it cannot sense how your team will emotionally react to a bold new direction. In these moments, your presence matters more than your productivity.
If you notice yourself accepting AI’s outputs without editing them, slow down. Ask yourself: Would I stand by this recommendation if my name were on it alone? Would I say it out loud to someone I respect? Those questions reinsert accountability — and accountability sharpens judgment.
Putting AI in Its Place
You have the opportunity to make deliberate choices about how and when artificial intelligence can best serve you and your team. Here are three ways to make the most of AI — and your own skills.
Automate Tasks, Not Trust
A practical way to stay balanced is to divide your work into tasks and trust. Tasks are the repeatable processes that benefit from speed. Trust is the human currency of management — the beliefs, emotions, and loyalties that bind a team together.
Use AI on tasks. Let it draft timelines, crunch numbers, or generate slides. Do not use it where trust is paramount. Deliver feedback yourself. Write the opening paragraph of a promotion announcement in your own voice. Decide when to change a goal or approve a hire with your own mind engaged, not on autopilot.
This distinction keeps AI working as your tool, not your proxy. It does the mechanical work while you do the meaningful work.
Consider your weekly team meeting. AI can help you build the agenda, surface metrics, and compile questions from your team’s project boards. But the tone of that meeting — whether people feel heard, valued, and motivated — is yours alone to create. No algorithm can do that for you. When trust is at stake, resist the urge to outsource.
Use AI to Widen Perspective, Not Narrow It
Another trap is using AI only to confirm what you already believe. Because these tools are designed to be agreeable, they will happily produce arguments that support your instincts. This can make you feel more decisive while actually limiting the options you consider.
When trust is at stake, resist the urge to outsource.
To avoid getting stuck in your own ideas, occasionally instruct AI to make a counterargument to your preferred option. If you are leaning toward reorganizing a team, ask for reasons not to. If you are ready to approve a budget, ask for the strongest case to reject it. This will force you to confront counterarguments before you commit — and it protects you from becoming overly certain about a decision simply because a machine echoed your view.
The best managers use AI to challenge their thinking, not to cushion it. They treat it as a sparring partner, not a cheerleader.
Build a Personal Guardrail
Even experienced managers can slip from using AI wisely to leaning on it too heavily. The shift is subtle — and it often feels like efficiency. To prevent that, build a simple guardrail: Track how much of your day involves thinking that you could not delegate. Ask yourself: Did I use AI to enhance my thinking or replace it? Did I exercise my judgment critically, or did I accept recommendations more automatically? These questions force you to notice the slope before you slide.
Some leaders set time blocks for “AI-free thinking” each week — no prompts, no tools, just unstructured reflection. Others limit AI use to specific tasks and keep a manual list of decisions where they want to feel the full weight of responsibility. Whatever the method you choose, the point is to keep drawing on your own judgment and critical thinking.
Thriving in the AI era does not mean adopting it fastest but remaining unmistakably human while using it. AI can accelerate your work, but it cannot care. It can generate options, but it cannot hold responsibility. That is your job — and the more AI can do for you, the more deliberate you must be about what you still do yourself. Let the machine do the lifting, not the leading.
Earlier this month, Microsoft launched Copilot Health, a new space within its Copilot app where users will be able to connect their medical records and ask specific questions about their health. A couple of days earlier, Amazon had announcedthat Health AI, an LLM-based tool previously restricted to members of its One Medical service, would now be widely available. These products join the ranks of ChatGPT Health, which OpenAI released back in January, and Anthropic’s Claude, which can access user health records if granted permission. Health AI for the masses is officially a trend.
There’s a clear demand for chatbots that provide health advice, given how hard it is for many people to access it through existing medical systems. And some research suggests that current LLMs are capable of making safe and useful recommendations. But researchers say that these tools should be more rigorously evaluated by independent experts, ideally before they are widely released.
In a high-stakes area like health, trusting companies to evaluate their own products could prove unwise, especially if those evaluations aren’t made available for external expert review. And even if the companies are doing quality, rigorous research—which some, including OpenAI, do seem to be—they might still have blind spots that the broader research community could help to fill.
“To the extent that you always are going to need more health care, I think we should definitely be chasing every route that works,” says Andrew Bean, a doctoral candidate at the Oxford Internet Institute. “It’s entirely plausible to me that these models have reached a point where they’re actually worth rolling out.”
“But,” he adds, “the evidence base really needs to be there.”
Tipping points
To hear developers tell it, these health products are now being released because large language models have indeed reached a point where they can effectively provide medical advice. Dominic King, the vice president of health at Microsoft AI and a former surgeon, cites AI advancement as a core reason why the company’s health team was formed, and why Copilot Health now exists. “We’ve seen this enormous progress in the capabilities of generative AI to be able to answer health questions and give good responses,” he says.
But that’s only half the story, according to King. The other key factor is demand. Shortly before Copilot Health was launched, Microsoft published a report, and an accompanying blog post, detailing how people used Copilot for health advice. The company says it receives 50 million health questions each day, and health is the most popular discussion topic on the Copilot mobile app.
Other AI companies have noticed, and responded to, this trend. “Even before our health products, we were seeing just a rapid, rapid increase in the rate of people using ChatGPT for health-related questions,” says Karan Singhal, who leads OpenAI’s Health AI team. (OpenAI and Microsoft have a long-standing partnership, and Copilot is powered by OpenAI’s models.)
It’s possible that people simply prefer posing their health problems to a nonjudgmental bot that’s available to them 24-7. But many experts interpret this pattern in light of the current state of the health-care system. “There is a reason that these tools exist and they have a position in the overall landscape,” says Girish Nadkarni, chief AI officer at the Mount Sinai Health System. “That’s because access to health care is hard, and it’s particularly hard for certain populations.”
The virtuous vision of consumer-facing LLM health chatbots hinges on the possibility that they could improve user health while reducing pressure on the health-care system. That might involve helping users decide whether or not they need medical attention, a task known as triage. If chatbot triage works, then patients who need emergency care might seek it out earlier than they would have otherwise, and patients with more mild concerns might feel comfortable managing their symptoms at home with the chatbot’s advice rather than unnecessarily busying emergency rooms and doctor’s offices.
But a recent, widely discussed study from Nadkarni and other researchers at Mount Sinai found that ChatGPT Health sometimes recommends too much care for mild conditions and fails to identify emergencies. Though Singhaland some other experts have suggested that its methodology might not provide a complete picture of ChatGPT Health’s capabilities, the study has surfaced concerns about how little external evaluation these tools see before being released to the public.
Most of the academic experts interviewed for this piece agreed that LLM health chatbots could have real upsides, given how little access to health care some people have. But all six of them expressed concerns that these tools are being launched without testing from independent researchers to assess whether they are safe. While some advertised uses of these tools, such as recommending exercise plans or suggesting questions that a user might ask a doctor, are relatively harmless, others carry clear risks. Triage is one; another is asking a chatbot to provide a diagnosis or a treatment plan.
The ChatGPT Health interface includes a prominent disclaimer stating that it is not intended for diagnosis or treatment, and the announcements for Copilot Health and Amazon’s Health AI include similar warnings. But those warnings are easy to ignore. “We all know that people are going to use it for diagnosis and management,” says Adam Rodman, an internal medicine physician and researcher at Beth Israel Deaconess Medical Center and a visiting researcher at Google.
Medical testing
Companies say they are testing the chatbots to ensure that they provide safe responses the vast majority of the time. OpenAI has designed and released HealthBench, a benchmark that scores LLMs on how they respond in realistic health-related conversations—though the conversations themselves are LLM-generated. When GPT-5, which powers both ChatGPT Health and Copilot Health, was released last year, OpenAI reported the model’s HealthBench scores: It did substantially better than previous OpenAI models, though its overall performance was far from perfect.
But evaluations like HealthBench have limitations. In a study published last month, Bean—the Oxford doctoral candidate—and his colleagues found that even if an LLM can accurately identify a medical condition from a fictional written scenario on its own, a non-expert user who is given the scenario and asked to determine the condition with LLM assistance might figure it out only a third of the time. If they lack medical expertise, users might not know which parts of a scenario—or their real-life experience—are important to include in their prompt, or they might misinterpret the information that an LLM gives them.
Bean says that this performance gap could be significant for OpenAI’s models. In the original HealthBench study, the company reported that its models performed relatively poorly in conversations that required them to seek more information from the user. If that’s the case, then users who don’t have enough medical knowledge to provide a health chatbot with the information that it needs from the get-go might get unhelpful or inaccurate advice.
Singhal, the OpenAI health lead, notes that the company’s current GPT-5 series of models, which had not yet been released when the original HealthBench study was conducted, do a much better job of soliciting additional information than their predecessors. However, OpenAI has reportedthat GPT-5.4, the current flagship, is actually worse at seeking context than GPT-5.2, an earlier version.
Ideally, Bean says, health chatbots would be subjected to controlled tests with human users, as they were in his study, before being released to the public. That might be a heavy lift, particularly given how fast the AI world moves and how long human studies can take. Bean’s own study used GPT-4o, which came out almost a year ago and is now outdated.
Earlier this month, Google released a study that meets Bean’s standards. In the study, patients discussed medical concerns with the company’s Articulate Medical Intelligence Explorer (AMIE), a medical LLM chatbot that is not yet available to the public, before meeting with a human physician. Overall, AMIE’s diagnoses were just as accurate as physicians’, and none of the conversations raised major safety concerns for researchers.
Despite the encouraging results, Google isn’t planning to release AMIE anytime soon. “While the research has advanced, there are significant limitations that must be addressed before real-world translation of systems for diagnosis and treatment, including further research into equity, fairness, and safety testing,” wrote Alan Karthikesalingam, a research scientist at Google DeepMind, in an email. Google did recently reveal that Health100, a health platform it is building in partnership with CVS, will include an AI assistant powered by its flagship Gemini models, though that tool will presumably not be intended for diagnosis or treatment.
Rodman, who led the AMIE study with Karthikesalingam, doesn’t think such extensive, multiyear studies are necessarily the right approach for chatbots like ChatGPT Health and Copilot Health. “There’s lots of reasons that the clinical trial paradigm doesn’t always work in generative AI,” he says. “And that’s where this benchmarking conversation comes in. Are there benchmarks [from] a trusted third party that we can agree are meaningful, that the labs can hold themselves to?”
They key there is “third party.” No matter how extensively companies evaluate their own products, it’s tough to trust their conclusions completely. Not only does a third-party evaluation bring impartiality, but if there are many third parties involved, it also helps protect against blind spots.
OpenAI’s Singhal says he’s strongly in favor of external evaluation. “We try our best to support the community,” he says. “Part of why we put out HealthBench was actually to give the community and other model developers an example of what a very good evaluation looks like.”
Given how expensive it is to produce a high-quality evaluation, he says, he’s skeptical that any individual academic laboratory would be able to produce what he calls “the one evaluation to rule them all.” But he does speak highly of efforts that academic groups have made to bring preexisting and novel evaluations together into comprehensive evaluations suites—such as Stanford’s MedHELM framework, which tests models on a wide variety of medical tasks. Currently, OpenAI’s GPT-5 holds the highest MedHELM score.
Nigam Shah, a professor of medicine at Stanford University who led the MedHELM project, says it has limitations. In particular, it only evaluates individual chatbot responses, but someone who’s seeking medical advice from a chatbot tool might engage it in a multi-turn, back-and-forth conversation. He says that he and some collaborators are gearing up to build an evaluation that can score those complex conversations, but that it will take time, and money. “You and I have zero ability to stop these companies from releasing [health-oriented products], so they’re going to do whatever they damn please,” he says. “The only thing people like us can do is find a way to fund the benchmark.”
No one interviewed for this article argued that health LLMs need to perform perfectly on third-party evaluations in order to be released. Doctors themselves make mistakes—and for someone who has only occasional access to a doctor, a consistently accessible LLM that sometimes messes up could still be a huge improvement over the status quo, as long as its errors aren’t too grave.
With the current state of the evidence, however, it’s impossible to know for sure whether the currently available tools do in fact constitute an improvement, or whether their risks outweigh their benefits.
In January, OpenAI, developer of ChatGPT, launched ChatGPT Health, one of many patient-facing generative artificial intelligence (AI) tools in various stages of development.
From educating patients on women’s sexual health and hip replacement surgery to generating postoperative instructions and digitizing informed consent, the potential medical applications of generative AI tools for the public are vast. In general, their goal is to increase patients’ comprehension of complex medical information and, in the case of ChatGPT Health, provide personalized information based on individual users’ own data. In the not-too-distant future, some experts predict new AI technologies will be able to independently make decisions about patient care.
At their most sophisticated, though, these technologies should serve as a “clinician extender,” not a clinician replacer, said cardiologist Haider Warraich, MD, a program manager at the US government’s Advanced Research Projects Agency for Health (ARPA-H) who previously helped shape digital health and AI policy at the US Food and Drug Administration (FDA).
“I hate the term AI doctor,” Warraich said. “There’s a lot more to me than what these technologies can do.”
There’s more than one reason why using an AI chatbot for health advice is not the same as consulting a physician. Recent studies have raised questions about the accuracy of health information provided by chatbots, and physicians and consumers have expressed concerns over the sharing of personal medical data with large language models (LLMs) that aren’t covered by the Health Insurance Portability and Accountability Act (HIPAA).
ChatGPT Health failed to properly triage the most and the least serious cases in what might be the first studyto assess the new tool’s performance, according to an accelerated preview of the article published in late February. The authors, who tested the chatbot using vignettes written by physicians, noted that under-triage of emergency conditions may delay or preclude lifesaving treatment, while over-triage of nonurgent presentations may increase health care utilization.
But LLMs hold promise as a way of expanding access to medical expertise or, at the very least, preparing patients to make the best use of visits with their physicians. “There’s a reason patients want to use these models,” said radiation oncologist Danielle Bitterman, MD, clinical lead for data science and AI at Mass General Brigham. “It’s so hard to access health care right now.”
ChatGPT vs ChatGPT Health
Of the 800 million users of ChatGPT each week, 1 in 4 seek health-related information, according to Nate Gross, MD, MBA, who leads health care strategy at OpenAI, which developed the chatbot.
“We said, ‘Hey, let’s build some differences to the product to make it a more contextually aware experience,’” as well as one with additional privacy and security connections, he recalled.
Users of “vanilla” ChatGPT, as Gross describes the forerunner of ChatGPT Health, can upload a physician’s note or copy laboratory results from their patient portal, he explained, but those bits of information lack context. “Just uploading a really short doctor’s note could be interpreted very differently if you’re age 20 or age 70.”
ChatGPT Health, on the other hand, invites users to upload all their personal health information, including laboratory test and imaging results as well as data collected by their Apple watch.
Although OpenAI consulted with hundreds of physicians from around the world to improve its models, ChatGPT Health is not designed to play doctor, Gross emphasized.
“We train our models specifically to guide patients to health care professionals for diagnosis and treatment,” he said. “We’re looking to give people information, not tell them if they’re sick, not tell them if they’re healthy. We’re a partner to the health care system in that regard.”
By late February, ChatGPT Health was not yet available to all comers; prospective users could add their name to a waitlist for using the chatbot. OpenAI declined to say how many people have used ChatGPT Health so far.
Privacy is one of users’ main concerns about ChatGPT Health and other LLMs that allow people to upload personal health information.
Elon Musk recently suggested in an X post that “[y]ou can just take a picture of your medical data or upload the file to get a second opinion from Grok,” an AI chatbot developed by his company, xAI.
Commenters were aghast at the idea. One decided to ask Grok’s opinion and posted its reply: “Grok is not HIPAA compliant, and we strongly advise against uploading sensitive medical data.”
Gross acknowledged that ChatGPT Health isn’t HIPAA compliant either. That’s not due to negligence, he pointed out, but because ChatGPT Health, like Grok, is not an entity covered by HIPAA, such as a physician or health insurance plan, or a business associate of a covered entity.
“They are not held to the same legal requirements that doctors and health care institutions are,” Bitterman said of the AI companies.
ChatGPT Health “is building on a lot of very proprivacy protections that ChatGPT already had, with additional layers of protection,” Gross said. “We wanted to set a really high bar.” For example, he noted, OpenAI will not include any ChatGPT Health conversations among the data it uses to train the LLM. And, he explained, as with ChatGPT, ChatGPT Health users can opt to make chats temporary, meaning they won’t appear in their history and ChatGPT Health won’t save them.
Even so, “those assurances may not be worth that much if companies get sold,” pointed out David Liebovitz, MD, codirector of the Institute for Artificial Intelligence in Medicine’s Center for Medical Education in Data Science and Digital Health at the Northwestern University Feinberg School of Medicine.
For now, he said, if patients asked him whether he thought they should try ChatGPT Health, he’d probably suggest “they could wait a little bit longer, when there could be more privacy-related tools.”
The Complete Picture?
Even if they want to, chatbot users—especially clinically challenging patients with long, complex medical histories—can’t always upload all their medical records, Bitterman pointed out.
“It’s very hard to ensure that you have all your medical records,” she said. “Those are the missing pieces that make clinical practice hard.”
Gross acknowledged that “our health care system is very fragmented.” But, he said, if patients forget to upload records from a particular physician or hospital, their physicians’ most recent notes likely will at least mention them.
Even patients who have all the relevant information may not paint a complete picture of their situation when interacting with LLMs, concluded research published in February.
The study, led by the Oxford Internet Institute in the UK, tested whether LLMs could help individuals without medical training identify underlying conditions and choose a course of action in 10 physician-drafted health scenarios. Researchers randomly assigned 1300 participants to receive assistance from 1 of 3 LLMs or, to serve as the control, a source of their choice, which was typically Google. The 3 LLMs were ChatGPT-4o, Meta’s Llama 3, and Command R+, which was developed by Cohere, a Canada-based company.
On average, when the scientists presented the vignettes directly to the LLMs, bypassing human interaction, the chatbots correctly identified the condition 95% of the time and the appropriate course of action 56% of the time.
But when study participants presented the vignettes to the same LLMs, the chatbots correctly identified relevant conditions only about a third of the time and the appropriate course of action less than 44% of the time. The LLMs performed no better than Google did in the control group.
“The limiting factor wasn’t just the model’s medical knowledge,” coauthor Rebecca Payne, MBBS, PhD, MPH, a general practitioner at the North Wales Medical School, Bangor University, said in an email. “It was the human-AI communication loop: people providing incomplete information, the model misinterpreting key details, and, importantly, people failing to carry forward a relevant diagnostic suggestion that the model didraise during the exchange.”
Whether using an LLM or Google, study participants “tended to underestimate the severity in the vignettes we tested,” Payne said. “That raises the risk that some users may feel falsely reassured or may delay seeking care.”
Payne’s findings didn’t surprise Bitterman. “With these chatbots, it’s incumbent on the user to know what they need to provide to the model to get the best information,” she said. “Having that kind of clinical nuance requires a lot of on-the-ground training,” not just the LLMs’ training on medical literature and textbooks.
The advice she gives to patients: “Don’t take immediate action just based on what you find online. We can discuss it together.”
Shorter and Simpler
The result could be deadly if, say, a chatbot mistakenly told a user that they didn’t need to go the emergency department because their chest pain was due to indigestion, not a heart attack.
That’s why Payne advises patients to use chatbots only for low-stakes support, such as explaining medical terms, preparing questions for a clinician, and summarizing what they’ve been told. “LLMs currently perform best as ‘assistants/secretaries’ that help organize known information rather than generate high-stakes clinical interpretations,” she said.
Physicians are working on a number of generative AI applications for more focused, lower-stake purposes.
For urologist Gio Cacciamani, MD, the diagnosis of a loved one with a serious disease unrelated to his specialty gave him a taste of what patients face when trying to decipher scientific information.
“When it comes to something outside my field, it’s very challenging to read,” said Cacciamani, director of the Artificial Intelligence Center for Surgical and Clinical Applications in Urology at USC’s Keck School of Medicine. “That situation opened my eyes.”
Cacciamani discovered 2 types of medical information online—either “extremely readable but not certified,” such as blog posts, or “peer-reviewed, certified, but not readable at all,” mainly publications in scientific journals.
Generative AI “has the potential to bridge long-standing gaps between certified medical knowledge and patient understanding,” Cacciamani and coauthors noted in a commentary published in February.
Using the retrieval-augmented generation, or RAG, technique, which trains the LLM with a medically verified knowledge base, he developed a new tool that can translate and summarize abstracts and full articles. More than 6000 people have turned to Pub2Post, and some medical journals are using it for their social media posts, Cacciamani said.
Antonio Forte, MD, a plastic surgeon at the Mayo Clinic in Jacksonville, Florida, used RAG to develop an LLM virtual assistant for postoperative instructions.
Patients often are discharged after surgery while still experiencing the residual effects of anesthesia or painkillers, making it difficult to remember postoperative instructions, Forte said. And, he added, they frequently misplace printouts of the information. “That’s why we thought, ‘What if we got patients the ability 24/7 to have access to high-quality, medically verified information?’”
Federal Initiatives
Using simulated patient interactions, testing the virtual assistant demonstrated strong technical accuracy, safety, and clinical relevance, albeit at a relatively high 11th-grade reading level, Forte and his coauthors recently reported.
And Bitterman has tested the ability of ChatGPT-4o and Llama 3.2-8B to answer patients’ questions about clinical trials with the goal of simplifying informed consent forms. In a recent study, she and her coauthors found that ChatGPT-4o was significantly more reliable and safer that Llama 3.2-8B in answering these queries.
In January, 2 federal agencies, both part of the US Department of Health and Human Services, launched initiatives focusing on digital health tools for patients with common, chronic conditions. One is designed to evaluate a regulatory pathway for digital health tools including LLMs, and the other aims to spur the development of an LLM for patients with heart failure.
The FDA, working with the Center for Medicare & Medicaid Innovation, announced the Technology-Enabled Meaningful Patient Outcomes (TEMPO) for Digital Health Devices Pilot.
According to the FDA, the voluntary pilot will evaluate a new enforcement approach “that supports digital health devices intended for use to improve patient outcomes in cardio-kidney-metabolic, musculoskeletal, and behavioral health conditions.”
The FDA has not yet authorized any LLM, Warraich said. Generative AI applications such as LLMs “present a unique challenge because of the potential for unforeseen, emergent consequences,” according to a Special Communication he coauthored in JAMA in 2024.
Today, Warraich is leading a new ARPA-H initiative whose goal is the development of new LLM systems that are ready for submission to the FDA within 2 years for authorization as medical devices. The Agentic AI-Enabled Cardiovascular Care Transformation (ADVOCATE) program “aims to transform advanced cardiovascular disease management with an agentic AI system that can provide 24/7 holistic clinical care.”
“I believe that as AI presents an opportunity to fundamentally transform what it means to be a clinician, a patient, and the relationship between them, cardiology will be at the tip of the spear…,” Warraich noted in an opinion piece published in February in the Journal of the American College of Cardiology.
The first use for technologies developed through ADVOCATE will be providing care for patients with congestive heart failure. If a patient is feeling short of breath, for example, the technology will decide if the patient should go to the emergency department and whether they might need a new prescription or a higher dose of a current medication, Warraich explained. Along with developing AI agents that can be trusted to make such changes autonomously, ADVOCATE will also support the creation of a supervisory AI “overseer” to monitor the safety and effectiveness of clinical AI agents after they’ve been deployed by health systems.
Given that ChatGPT is only 3 years old, the rapid development of new generative AI applications for patient use may seem like science fiction. As Bitterman said, “This is so far beyond what I would have predicted 5 years ago.”
Published Online: March 6, 2026. doi:10.1001/jama.2026.1122
Conflict of Interest Disclosures: Dr Bitterman reported serving as an associate editor of JCO Clinical Cancer Informatics, Annals of Oncology, and radiation oncology for HemOnc.org. She also reported receiving consulting fees from Inspire Exercise Medicine LLC and honoraria from Harvard Medical School, Med-IQ, and the National Comprehensive Cancer Network and serving as a scientific advisory board member for Blue Clay Health LLC and Mercurial AI. Dr Liebovitz reported receiving research grants from Children’s Hospital of Philadelphia, the FDA, Merck Sharp & Dohme, the National Institutes of Health, the National Science Foundation, and the University of Chicago. He also reported that he has an ownership or investment interest in CodeAccelerate, Dendritic Health AI, KYRAL Inc, and Optima Integrated Health Inc. Dr Cacciamani reported holding equity in EditorAIPro, of which Pub2Post is a product. Dr Forte reported that his research at Mayo has been funded by Dalio Philanthropies, the Gerstner Family Foundation, the Richard M. Schulze Family Foundation, and Schmidt Sciences and that he is a paid medical advisor for OpenEvidence. No other disclosures were reported.
Scientific research underpins the things we do. Huge investments are made capitalizing on technological developments; governments declare that their policies will be based on academic evidence; doctors decide what treatments to use for their patients. And beneath all that is the idea that, ultimately, we can trust that published research fairly reflects the realities of the world: that it is true, that it is balanced, and that it has been produced and reviewed by expert researchers. But that foundation is starting to wobble.
Shortly after ChatGPT was released, it became clear that it was beginning to affect scholarly research. Published papers became much more likely to meticulously delve into intricate questions, and to do so with great enthusiasm, in ways they never had before (Stokel-Walker 2024). Distinctive quirks of large language model (LLM) writing such as these began to explode in popular usage, first in certain fields such as computer science or engineering, before spreading to other disciplines. Some researchers estimate that in 2024, 13.5 percent of all papers in PubMed indexed journals had been processed using LLMs, representing around 200,000 articles that year (Kobak 2025). In preprints—papers posted online as unreviewed drafts—the rates increased even faster, with more than 20 percent of computer science preprints showing signs of LLM involvement by late 2024 (Liang 2025).
In retrospect, this was not surprising. For many researchers, forced by the conventions of academia to publish in a second language, a tool that could help with fluent translation is a blessing. And across the world, researchers have been under strong pressure to publish more papers for decades; a tool which could speed up the process of writing was always going to be attractive. And it does speed it up; researchers who have used LLMs in their writing produce around a third more preprints than their colleagues (Kusumegi et al 2025).
But it can be tempting to use it too much. Some researchers have fallen into the trap of simply getting the LLM to generate large portions of papers for them, or to rewrite a draft so extensively that it might unintentionally change the meaning (Conroy 2023). What emerges is something that looks superficially like research, written fluently, convincingly, and confidently, but which might potentially just turn out to be so much smoke and mirrors. In extreme cases, they can be capable of generating entire papers based on research that simply never took place. It is no surprise that researchers have found that identifiably LLM-edited papers are retracted twice as often as average (Kousha & Thelwall 2025).
To a reader, though, LLM-copyedited papers are hard to distinguish from LLM-generated ones. One can sometimes tell that the tools were used, but not how much they were used in any given paper. When surveyed, 28 percent of researchers said they had used LLMs for copyediting and 8 percent for generating new text, but half or more of both groups didn’t disclose it in the paper (Kwon 2025).
Alongside this reluctance to disclose LLM use, many researchers appear keen to disguise it. When some of the distinctive markers of AI writing in research papers were first reported, they suddenly became less popular in newer publications, but the use of the less-publicized markers continued to grow (Geng & Trotta 2025). Together, this strongly implies that many authors just don’t want it known that they are using these tools.
And it is not just in writing the papers where people are trying to cut corners with AI. Most research papers are peer-reviewed by other researchers, giving a degree of confidence that the research is robust and legitimate. This can be a time-consuming and thankless task, and—unsurprisingly—is one where LLMs have begun to creep in. Most publishers now have explicit warnings against reviewing papers with LLMs, but it almost certainly still happens. Some less scrupulous authors have even been discovered leaving invisible comments in drafts, instructing the LLM that they expect will review it to skip straight to approval (Sugiyama & Eguchi 2025). If nothing else, this technology has invented new kinds of research integrity problems!
These tools are also beginning to affect how we find research. The major scholarly databases are all beginning to offer “AI-assisted search” in some form or another, using LLMs to interpret a user question and find results—either as a list of recommended papers, or as a summary and analysis of the results. When this works well, it can be very convincing. It may return six useful and interesting papers. But will it give you what you want: the right six papers, or the best six? We just don’t know.
And here lies a big risk. LLMs are often described as black boxes; any oddities in the way they work, or biases they encode, will be baked into the results, with no easy ways to spot them. There is no reason to think that any of the scholarly databases are intentionally skewing their results, but biases or censorship can easily arise unintentionally, especially in such a complex system as these (Tay 2025).
The most prominent and accessible of these databases, for non-academics, is Google Scholar. Google Scholar works by indexing everything found by Google, with results which look broadly like a research paper. This is unlike traditional databases, which work from a selective list of publications. It is more expansive than more traditional databases, indexing things like preprints and working papers as well as published research. But this has made it more vulnerable to disruption or manipulation by LLMs (Haider et al 2024). Because it includes a wider range of material, it already indexes a higher proportion of the unreviewed types of items that are more likely to involve LLM text. Because it is entirely automated, it does not have the manual screening which could keep out some of the lowest-value junk.
That automated approach causes other problems. Google Scholar identifies papers it does not otherwise know about by looking in the references list of the ones it indexes. This means it can report a reference to them even if no digital copy exists, which can be very useful for more obscure material. But one of the more dramatic failures of LLMs is that they often hallucinate citations—works that do not exist, plausible sounding mirages, often in journals that themselves do not exist. Google Scholar does not have any way to distinguish between real and false references—understandably, its developers never expected that anyone would be including false references—so it reports that they exist. People trying to validate what another LLM tells them look up the paper, find it indexed in Google Scholar, and, well, surely it must be real! It’s in the database.
Most researchers would never admit to citing a paper they have not read… but one can imagine that it is tempting, especially when it seems to perfectly address the question in hand, and you seem to have a fair summary of it but just can’t track it down however hard you try. And so those fictional citations creep out into real papers. Entire fictional journals may be conjured into a shadowy existence this way (Klee 2025).
This is a perfect storm brewing for the integrity of scholarly publishing. The volume of significantly AI-generated material is increasing, and it is being masked by a flood of “AI polished” papers, which have the same surface style. It’s no wonder that readers, especially casual readers, cannot be confident in distinguishing between real research and fictional, and cannot tell how much of the paper might potentially be hallucinated.
At the same time, the system is stumbling under the extra burdens placed on it by the use of LLMs; it has become easier to produce papers, without becoming easier to assess or peer review them. In late 2025, the preprint server arXiv reported that it would tighten its rules and no longer accept the submission of computer science review articles; the volume of them was simply too large for their moderators to cope with (Castelvecchi 2025). As the system creaks under strain, more and more venues will be faced with an unpleasant choice: Restrict submissions, and add yet more work to their volunteer reviewers? Or loosen standards and risk problematic material slipping through?
Then we have to consider why those problematic papers are out there. At the moment, most of the primarily AI-generated papers appear to be from academics trying to bolster their own publication lists. They are unlikely to be deliberately malicious, though they may fit into more traditional patterns of scientific fraud (Richardson et al 2025). But they are still cluttering up the databases, filled with information that may or may not be valid, conclusions and recommendations that may or may not be true, citations pointing to other non-existent literature. These AI-edited papers will place a burden on every future researcher to try to make sense of them, even if that’s not the intention.
But not all examples might be so innocent. Scientific papers—and all the prestige, reliability, and authority that they carry—are a prime target for intentional misinformation campaigns (Bergstrom & West 2023, Haider 2024). Should someone wish to publish a large number of deliberately skewed papers to bolster a certain position—that a new drug is remarkably effective; that an industrial process is perfectly safe; that a particular policy decision has made us all happier and wealthier—then they have found themselves a new tool to help produce them quickly and easily, at the same time that the system is less resilient at keeping them out. It is difficult to say for sure whether this is yet happening, but it is clear that the opportunity cost of doing it has become easier, cheaper, and more achievable.
The ways in which we access research are also changing. The move towards LLM-based information retrieval means that an opaque system is being inserted between readers and the information they are looking for, opening up the opportunity for third parties to control access to research in ways that may not be obvious, or even intentional.
And to cap it all off, anyone who is motivated to reject the validity of research which does not fit their preconceptions now has a perfect pretext to do so, regardless of its quality: “Oh, you can’t trust that anyway, don’t you know it’s all AI rubbish now?”
A compelling analogy here, suggested by the historian Kevin Baker, is to think of the publishing system as an immune system for science: It rejects things that might harm the system, perhaps not perfectly, but reliably enough to keep everything ticking along and reasonably healthy. But when our immune system is stressed, we can succumb more easily to a minor infection that we would normally brush off (Baker 2025).
The scholarly publishing system is, undeniably, not in the best of health. It is beset by a whole range of pressures. It carries on, but it is limping. The well-meaning use of AI to help speed things up might, in this analogy, be the fever that ends up sending the whole thing to its sickbed, opening the door for much more damaging illnesses—in the form of intentional and malicious disinformation—to take root and do real harm.
Kousha K & Thelwall M. 2025. “How much are LLMs changing the language of academic papers after ChatGPT? A multi-database and full text analysis.” September 11. arXivhttps://arxiv.org/abs/2509.09596
Richardson, R, et al. 2025. “The entities enabling scientific fraud at scale are large, resilient, and growing rapidly.” August 4. Proceedings of the National Academy of Sciences122(32). https://www.pnas.org/doi/10.1073/pnas.2420092122