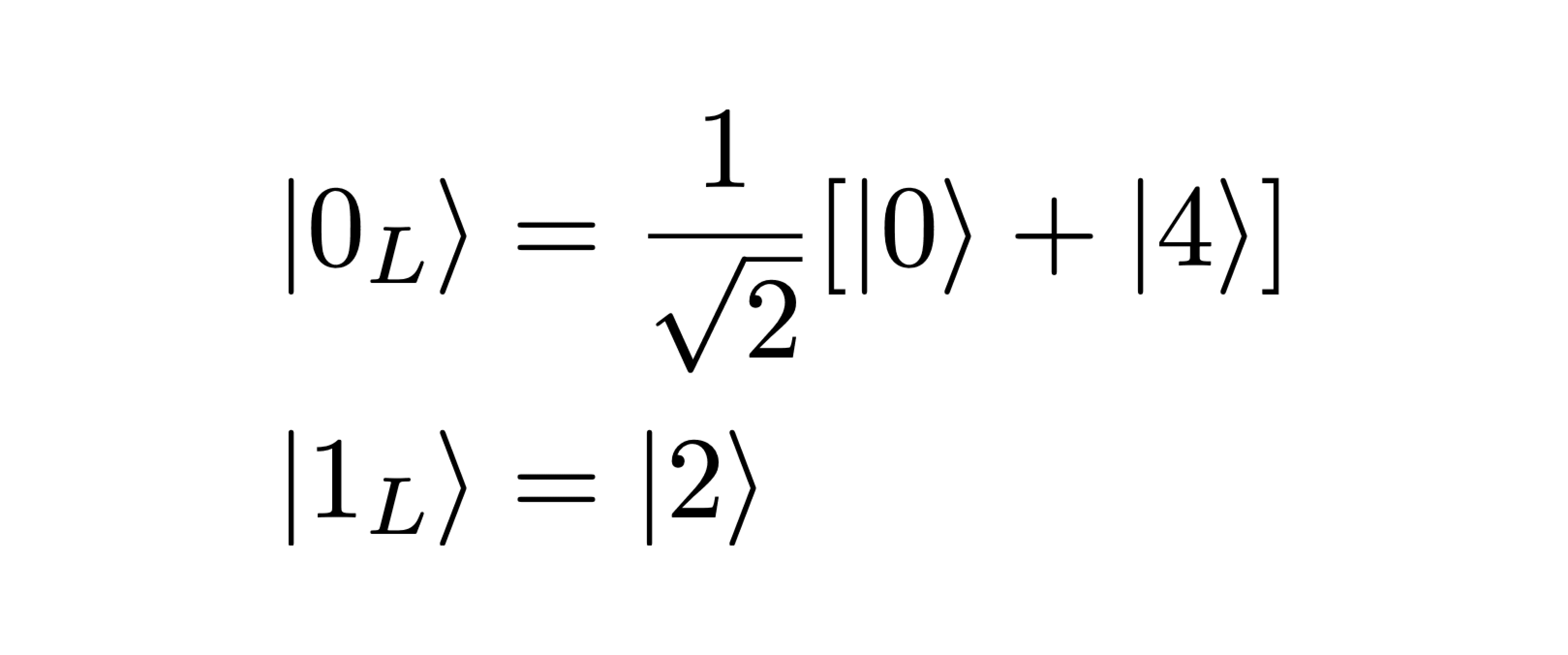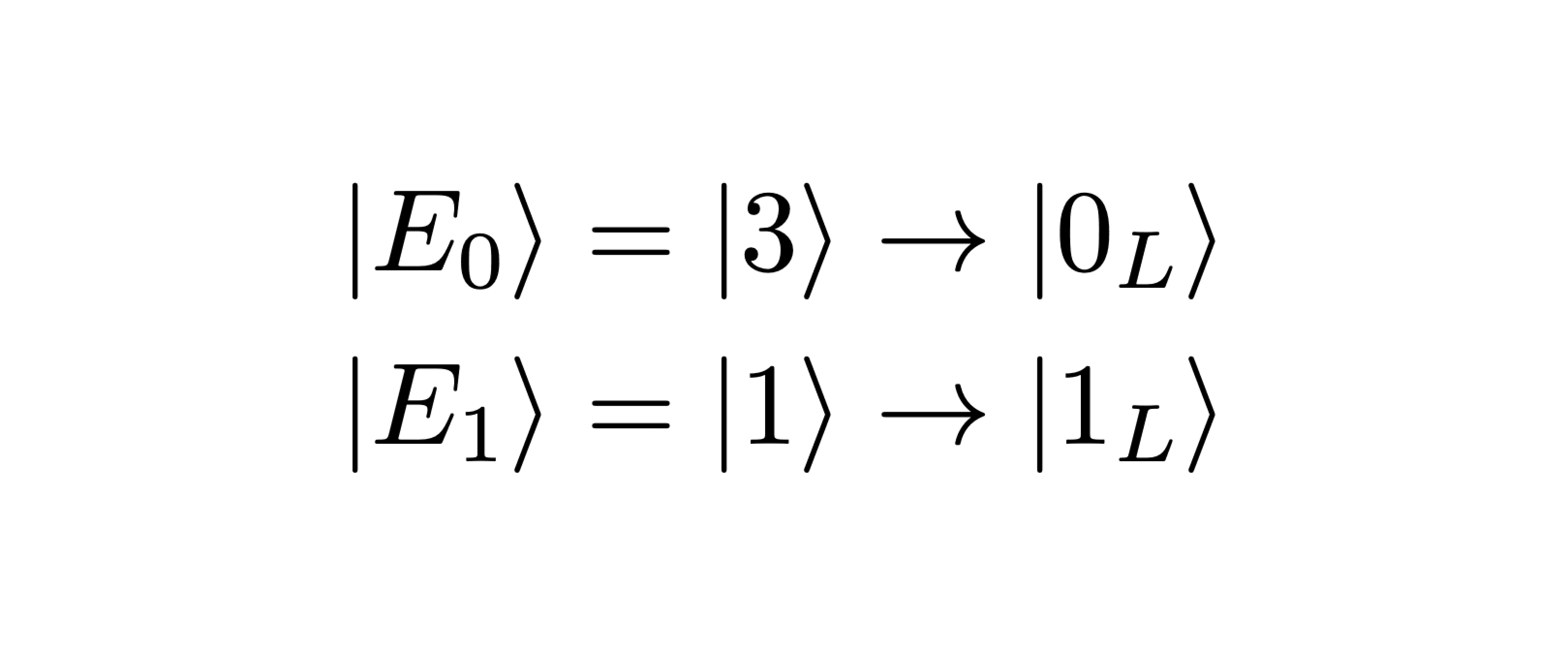On April 4, from noon to 2 p.m. ET, the Federal Electronic Health Record Modernization (FEHRM) office will host The State of the Federal EHR, an event held twice a year to discuss the current and future state of the federal electronic health record (EHR), health information technology, and health information exchange. The event highlights the progress made in implementing a single, common federal EHR and related capabilities across the Department of Defense, Department of Veterans Affairs, Department of Homeland Security’s U.S. Coast Guard, Department of Commerce’s National Oceanic and Atmospheric Administration, and other federal agencies.
The event will provide the latest updates and insights about the federal EHR including the recent deployment of the federal EHR at the Captain James A. Lovell Federal Health Care Center.
This event will be virtual via Microsoft Teams and open to the public. We invite active participation from individuals who possess relevant broad-based knowledge and experience. Additional details regarding the agenda and meeting will be distributed to registered participants prior to the event.
If you have any questions about this event, please send an email to FEHRMcommunications@va.gov and include “The State of the Federal EHR” in the subject line.
Karl FreundContributorOpinions expressed by Forbes Contributors are their own.
Founder and Principal Analyst, Cambrian-AI Research LLC
The IBM Institute for Business Value (IBV) has published a beautiful book, good to read and also a substantial addition to any executive office: the fourth edition of The Quantum Decade. The 168-page tome written by over 70 professionals in every industry, clearly lays out the appropriate problems, the approaches to solutions, and the amazing technology being invented as we speak. With dozens of uses cases, and in-depth portrayals, this book is a must-read for every CEO and CTO. Here’s a summary of select sections I found particularly interesting, and a few use cases from the book.
Quantum Thinking
The IBV did a CEO study in 2021 that revealed that 89% of over 3,000 chief executives surveyed did not consider quantum computing as a key technology for delivering business results in the next two to three years. While this lack of recognition may be understandable in the short term, given quantum computing’s disruptive potential in the coming decade, CEOs need to start mobilizing resources to understand and engage with quantum technology now. IBV research also finds that in 2023, organizations invested 7% of their R&D budget in quantum computing, up 29% from 2021. By 2025, this is expected to further increase by another 25%.
Ignoring quantum computing could pose significant risks, the authors assert, with consequences potentially greater than missing out on the opportunity presented by artificial intelligence a decade ago. Phase 1 of the quantum computing playbook involves acknowledging that the computing landscape is undergoing a fundamental shift. This shift from analytics to discovery of forward-looking models that can run on Quantum opens up possibilities for uncovering solutions that were previously impossible.
Phase 2 involves asking important questions: How might quantum computing disrupt and reshape your business model? How could it enhance your existing AI and classical computing workflows? What could be the “killer app” for quantum computing in your industry? How can your organization deepen its quantum computing capabilities, either internally or through partnerships with ecosystems? This is the time to experiment, iterate with scenario planning, and cultivate talent proficient in quantum computing to educate internal stakeholders and leverage deep tech resources.
IBM says it is important to note that quantum computing doesn’t replace classical computing. Instead, quantum forms a progressive partnership with classical computing and AI, where the three work together iteratively, becoming more powerful as a collective than they are individually. In the hardware configuration above, each Quantum chassis is surrounded by classical computers, and the black rows are likely inference processing servers. So one needs to think about how to factor the solution to take advantage of these closely-knit but disparate systems.
Phase 3, known as Quantum Advantage, marks a significant milestone where quantum computing demonstrates its ability to perform specific tasks more efficiently, cost-effectively, or with better quality than classical computers. Today, IBM’s quantum systems deliver utility-scale performance: the point at which quantum computers can now serve as scientific tools to explore new classes of problems beyond brute-force, classical simulation of quantum mechanics. Quantum utility is an important step toward “advantage,” when the combination of quantum computers with classical systems enables significantly better performance than classical systems alone. As advancements in hardware, software, and algorithms in quantum computing converge, they enable substantial performance improvements over classical computing, unlocking new opportunities for competitive advantage across industries
Use Cases
However, achieving business value from quantum computing requires prioritizing the right use cases—those with the potential to truly transform an organization or an entire industry. Identifying and focusing on these strategic use cases is crucial for realizing the benefits of quantum technology. Here are a few examples that IBM articulates in the book.
Exxon Mobile and the Global Supply Chain
ExxonMobil is exploring the potential of quantum computing to optimize global shipping routes, a crucial component of international trade that relies heavily on maritime transport. With around 90% of the world’s trade carried by sea, involving over 50,000 ships and potentially 20,000 containers per ship, optimizing these routes is a complex challenge beyond the capabilities of classical computers. In partnership with IBM, ExxonMobil is leveraging the IBM Quantum Network, which it joined in 2019 as the first energy company, to develop methods for mapping the global routing of merchant ships to quantum computers.
The core advantage of quantum computing in this context lies in its ability to minimize incorrect solutions and enhance correct ones, making it particularly suited for complex optimization problems. Utilizing the Qiskit quantum optimization module, ExxonMobil has tested various quantum algorithms to find the most effective ones for this task. They found that heuristic quantum algorithms and the Variational Quantum Eigensolver (VQE)-based optimization showed promise, particularly when the right ansatz (a physics term for an educated guess) is chosen.
This exploration into quantum computing for maritime shipping optimization not only has the potential to significantly impact the logistics and transportation sectors but also demonstrates broader applications in other industries facing similar optimization challenges, such as goods delivery, ride-sharing services, and urban waste management.
The University of California and Machine Learning
Researchers from IBM Quantum and the University of California, Berkeley have developed a breakthrough algorithm in quantum machine learning, demonstrating a theoretical Quantum Advantage. Traditional quantum machine learning algorithms often required quantum states of data, but this new approach works with classical data, making it more applicable to real-world scenarios.
The team focused on supervised machine learning, where they utilized quantum circuits to map classical data into a higher dimensional space—a task naturally suited for quantum computing due to the high-dimensional nature of multiple qubit states. They then estimated a quantum kernel, a measure of similarity between data points, which was used within a classical support vector machine to effectively separate the data.
In late 2020, the researchers provided solid proof that their quantum feature map circuit outperforms all possible binary classical classifiers when only classical data is available. This advancement opens up new possibilities for quantum computing in various applications, such as forecasting, predicting properties from data, or conducting risk analysis, marking a significant step forward in the field of quantum machine learning.
E.ON and Machine Learning
E.ON, a major energy operator in Europe, is leveraging quantum computing to enhance risk management and achieve its emission reduction goals. With a vast customer base and a significant increase in renewable assets expected by 2030, the company faces the challenge of managing weather-related risks and ensuring affordable energy costs. Collaborating with IBM, E.ON has implemented quantum computing strategies to conduct complex Monte Carlo simulations across various factors like locations, contracts, and weather conditions.
Key quantum computing applications include:
Using quantum nonlinear transformations for calculating energy contract gross margins via quantum Taylor expansions.
Performing risk analysis with quantum amplitude estimation to improve dynamic circuit leveraging.
Integrating quadratic speed-ups in classical Monte Carlo methods to optimize hardware resources.
These strategies have enabled real-time planning, finer risk diversification, and more frequent portfolio risk reassessments, thus aiding in the renegotiation of hedging contracts. E.ON views quantum computing as a pivotal technology for advancing machine learning, risk analysis, accelerated Monte Carlo techniques, and combinatorial optimization for logistics and scheduling, marking a significant shift in managing energy-related challenges.
Wells Fargo and Financial Trading
Wells Fargo is actively exploring the potential of quantum computing for practical applications in the financial sector, partnering with IBM within the IBM Quantum Network. This collaboration grants Wells Fargo access to IBM’s quantum computers via the cloud, allowing for pioneering work in quantum computing use cases, including sampling, optimization, and machine learning, aimed at deriving valuable results from quantum technologies.
A notable area of investigation between Wells Fargo and IBM is sequence modeling, particularly for predicting mid-price movements in financial markets. This involves analyzing the Limit Order Book, which records ask-and-bid orders on exchanges, and focuses on the mid-price—the average between the lowest ask and the highest bid prices at any moment.
Wells Fargo has explored using quantum hidden Markov models (QHMMs) for stochastic generation, a quantum approach to sequence modeling. QHMMs aim to generate sequences of likely symbols (e.g., representing price increases or decreases) from a given start state, similar to how large language models generate text. This quantum approach has shown to be more efficient than its classical counterpart, hidden Markov models (HMMs), offering new ways to enhance artificial intelligence technology in finance through the more efficient definition of stochastic process languages.
JSR and Chip Manufacturing
IBM and JSR are exploring how quantum computing could shape the future of computer chip manufacturing. Gordon Moore famously predicted in 1965 that the number of transistors on a computer chip would double approximately every two years, a forecast that has held true for decades, known as “Moore’s Law.” This progress has been largely enabled by innovations in semiconductor manufacturing, notably the development of a photoresist-based method by IBM in the 1980s. This technique, which uses a light-sensitive material to print transistors on chips, became widespread, with companies like JSR Corporation becoming leading producers.
The continuous miniaturization and performance improvement of chips are challenged by the costs and complexities of designing new photoresist molecules, a task for which modern supercomputers struggle due to the difficulty of simulating quantum-scale phenomena. Quantum computing, which operates on the principles of quantum mechanics, offers a potential solution by efficiently simulating molecular systems, including those comprising photoresist materials.
In a collaborative effort, IBM and JSR Corporation have started to explore the application of quantum computing in this field. A 2022 study demonstrated the use of IBM Quantum hardware to simulate small molecules akin to parts of a photoresist. This research represents a step toward utilizing quantum computing for developing new materials, potentially ensuring that Moore’s Law can continue to apply well into the future by enabling further advancements in semiconductor technology.
Conclusions
As you can see, the new edition of IBM’s Quantum Decade is a fabulous resource that should start more conversations and exploration in board rooms around the world. And thats exactly what IBM intended; by collaborating with early thinkers, we can jump start the Quantum Journey and accelerate the time to real-world solutions.
Bosonic Qiskit is an open-source software package from the Qiskit ecosystem that invites users to construct, simulate, and analyze quantum circuits using bosonic modes. In our latest for the IBM Quantum blog, two of the developers behind Bosonic Qiskit show users how to use their package to explore one of the most promising applications of hybrid qubit-bosonic hardware: bosonic error correction.
A common approach to quantum error correction is to redundantly encode a logical qubit using many physical qubits. In practice, a major hurdle for implementing such many-qubit-based codes is the fact that, as the code “scales-up” in the number of errors it can correct, there is a corresponding increase in the number of noisy physical qubits over which the logical information must be spread. This, in turn, creates more opportunities for errors to occur.
One promising alternative strategy is to instead encode a logical qubit into a single bosonic mode, using its infinite-dimensional Hilbert space to provide the “extra space” to encode redundancy and detect errors. An immediate advantage of this approach is its hardware efficiency, requiring just a single mode (of, for example, a microwave cavity) to encode an error-corrected logical qubit. Another advantage is the simplicity of the dominant error channel, photon loss.
In this blog post, Bosonic Qiskit developers Zixiong Liu and Kevin C. Smith show users how to simulate the binomial “kitten code,” a simple variant of one of the three bosonic codes that have recently been demonstrated to surpass the “break-even” point. Take a look: https://ibm.co/3x3Ivbi
Date
20 Mar 2024
Authors
Zixiong Liu
Kevin C. Smith
In a previous post on the Qiskit Medium, we introduced Bosonic Qiskit, an open-source project in the Qiskit ecosystem that allows users to construct, simulate, and analyze quantum circuits that contain bosonic modes (also known as oscillators or qumodes) alongside qubits. Now, we’re following up on that work with a closer look at one of the most promising applications of hybrid qubit-bosonic hardware: bosonic error correction.
Bosonic error correction is an error handling strategy in which logical qubits are encoded into the infinite-dimensional Hilbert space of a type of quantum system known as the quantum harmonic oscillator. Much like the quantum systems we use to encode qubits, a quantum harmonic oscillator has discrete or “quantized” energy levels. However, qubits have only two energy levels while oscillators are formally described as having infinite levels, a quality that offers key advantages for applications like quantum error correction. Physical realizations of quantum harmonic oscillators include the electromagnetic modes of a microwave cavity and the vibrational modes of a chain of ions, to name a few examples.
In this article, we will demonstrate the utility of Bosonic Qiskit for exploring this promising approach to quantum error correction through an explicit, tutorial-style demonstration of one of the simplest bosonic error correction codes — the Binomial “kitten” code. We’ve also created a companion Jupyter notebook that serves as a tutorial on the Bosonic Qiskit GitHub repository. The notebook provides many further details on the basics of error correction, the kitten code, and its implementation in Bosonic Qiskit.
Benefits of bosonic error correction
A common approach to quantum error correction is to redundantly encode a logical qubit using many physical qubits. A well-known example of such a strategy is the surface code, where logical information is nonlocally “smeared” across many qubits such that it cannot be corrupted by local errors.
In practice, a major hurdle for implementing such many-qubit-based codes is the fact that, as the code “scales-up” in the number of errors it can correct, there is a corresponding increase in the number of noisy physical qubits over which the logical information must be spread. This, in turn, creates more opportunities for errors to occur. Implementing an error correction code reliable enough to tame this vicious cycle and improve the lifetime of logical information — despite the increase in additional parts — is not a trivial task.
One promising alternative strategy is to instead encode a logical qubit into a single bosonic mode, using its infinite-dimensional Hilbert space to provide the “extra space” to encode redundancy and detect errors. An immediate advantage of this approach is its hardware efficiency, requiring just a single mode (of, for example, a microwave cavity) to encode an error-corrected logical qubit. Another advantage is the simplicity of the dominant error channel, photon loss.
Technically speaking, an ancillary nonlinear element such as a superconducting qubit is also needed for universal control and measurement of the bosonic mode.
These advantages have recently been realized experimentally in superconducting platforms, with three distinct bosonic codes demonstrated to surpass the “break-even” point, meaning the lifetime of the logical qubit exceeds that of all base components in the system. These include the cat code [1], the GKP code [2], and the binomial code [3]. In the next section of this blog post (and in the companion Jupyter notebook), we will discuss a simple variant of the binomial code known as the “kitten code.” In particular, we will describe its basic properties, and show how the built-in functionality of Bosonic Qiskit allows us to simulate and analyze this code.
Error correction with the binomial “kitten” code
The binomial code refers to a family of codes which seek to approximately correct amplitude damping noise (i.e., photon loss errors). This is a desirable property given that photon loss is the dominant error of bosonic modes. The simplest version of the binomial code is commonly referred to as the ‘kitten’ code, which can correct a single photon loss error. Multiple photon loss events can result in a logical error.
The code words — physical states that encode logical information — of Bosonic error correcting codes can be represented as superpositions of Fock states. Fock states are quantum states with definite photon number n, labelled by |n⟩. In the kitten code, our two logical code words are:
Beyond the property that single photon loss errors do not result in a logical error, there are a few additional advantages to defining our logical states as such.
First, the average photon number for both code words is two. As the average rate of photon loss for a qumode is proportional to the photon number, this rate will be the same in both code words. Crucially, this means it is therefore impossible to infer logical information based on the rate of photon loss detection.
Second, as both code words have even photon number parity, single photon loss errors will map the logical states onto odd parity Fock states (|1L⟩ → |1⟩, |0L⟩ → |3⟩), conveniently enabling the detection of single photon loss errors by measuring the photon number parity (i.e., whether it is even or odd). Importantly, this is done without learning the photon number. By extracting only the minimal information needed to detect errors, the logical information will be preserved.
Implementing the kitten code in Bosonic Qiskit
Now that we have a sense of how the kitten code works, let’s see how we can use it to simulate error correction by leveraging the built-in functionality of Bosonic Qiskit. In brief, we’ll need to implement the following components:
The photon-loss error channel (for simulating errors)
Measurement of the photon-number parity (for detecting errors)
Recovery operation (when an error is detected)
Below, we briefly highlight the various functionalities that support our simulations. Please refer to our Jupyter Notebook for further implementation details.
Photon loss
Photon loss is implemented using Bosonic Qiskit’s PhotonLossNoisePass(), which takes as input the loss rate of the mode. Here, we choose 0.5 per millisecond, corresponding to a lifetime of 2 ms — roughly speaking, the average amount of time that Fock state |1⟩ will “survive.” We model idling time between error correction steps using the cv_delay() gate.
Error detection
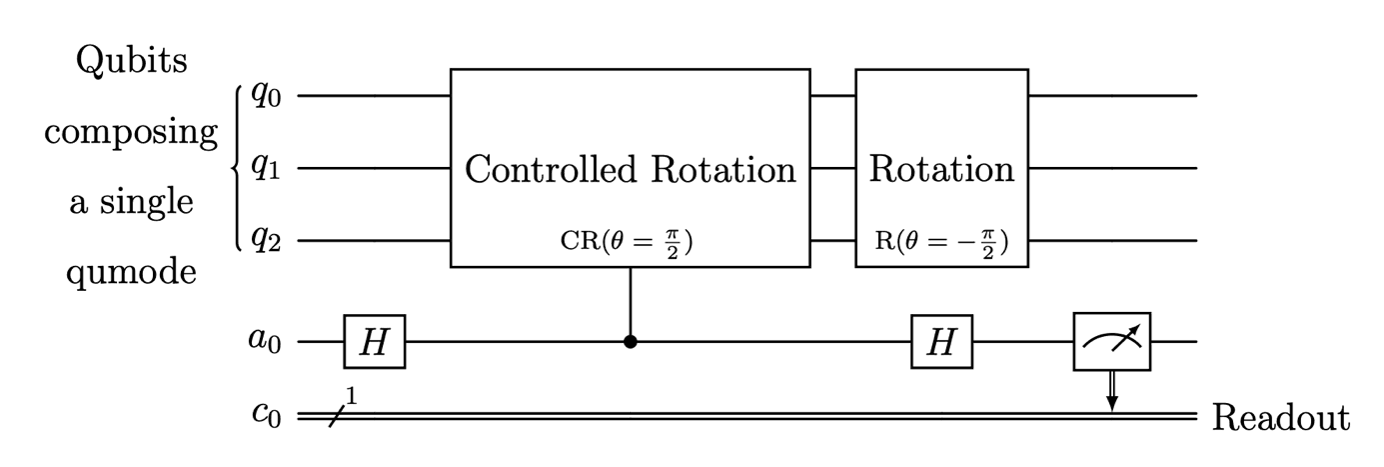
As previously discussed, we can detect single photon loss errors by measuring the photon-number parity. In practice, this is achieved via the Hadamard test, a technique that relies on phase kickback using an ancillary qubit. In particular, we can use a controlled-rotation operation of the form CR(π/2) = e-i(π/2)σza†a such that final qubit state depends on the photon-number parity (see Figure 1).
Figure 1: Circuit diagram for the parity check subcircuit. This subcircuit uses the Hadamard test to measure the parity of the qumode. The second uncontrolled rotation R(θ) = e-iθa†a removes a global phase. As discussed in our previous blog post, Bosonic Qiskit represents a single qumode (with some cutoff) using a logarithmic number of qubits.
Recovery operation
When an error is detected, we need to apply a correction that maps the system back onto the appropriate logical state. For the purposes of this tutorial, we will not go into detail on the specific sequence of gates needed to physically implement the error recovery operators for the binomial code. Instead, we will simply state the expected theoretical state transfer operation that maps the error states back onto our logical qubits.
If parity changes due to photon loss, the qumode will end up in one of two error states depending on the initial logical state: |1L⟩ → |1⟩ ≡ |E1 ⟩ or |0L ⟩ → |3⟩ ≡ |E0⟩. To correct the error state back to the logical state, we therefore require some unitary operation Ûoddthat realizes the following mapping:
What if an error is not detected? You might guess that the answer is to do nothing, but this turns out to be incorrect. Quite non-intuitively, not detecting photon loss itself produces error!
To see why, imagine someone gives you a qumode prepared either in Fock state |0⟩ or |2⟩, and you have the ability to detect single photon loss through parity measurements. Now imagine that you repeatedly measure the parity over a timescale much longer than expected rate of photon loss, and keep finding that no photon loss has occurred. You might begin to suspect that the qumode is in the state |0⟩, and each repeated measurement will only enhance this suspicion.
In this way, even when the mode is in a superposition of |0⟩ or |2⟩, the state will decay toward |0⟩ through this phenomenon known as “no-jump backaction”. Consequently, we can further improve our error correction protocol by applying a correction Ûeventhat undoes this no-jump backaction when even parity is measured.
Putting it all together
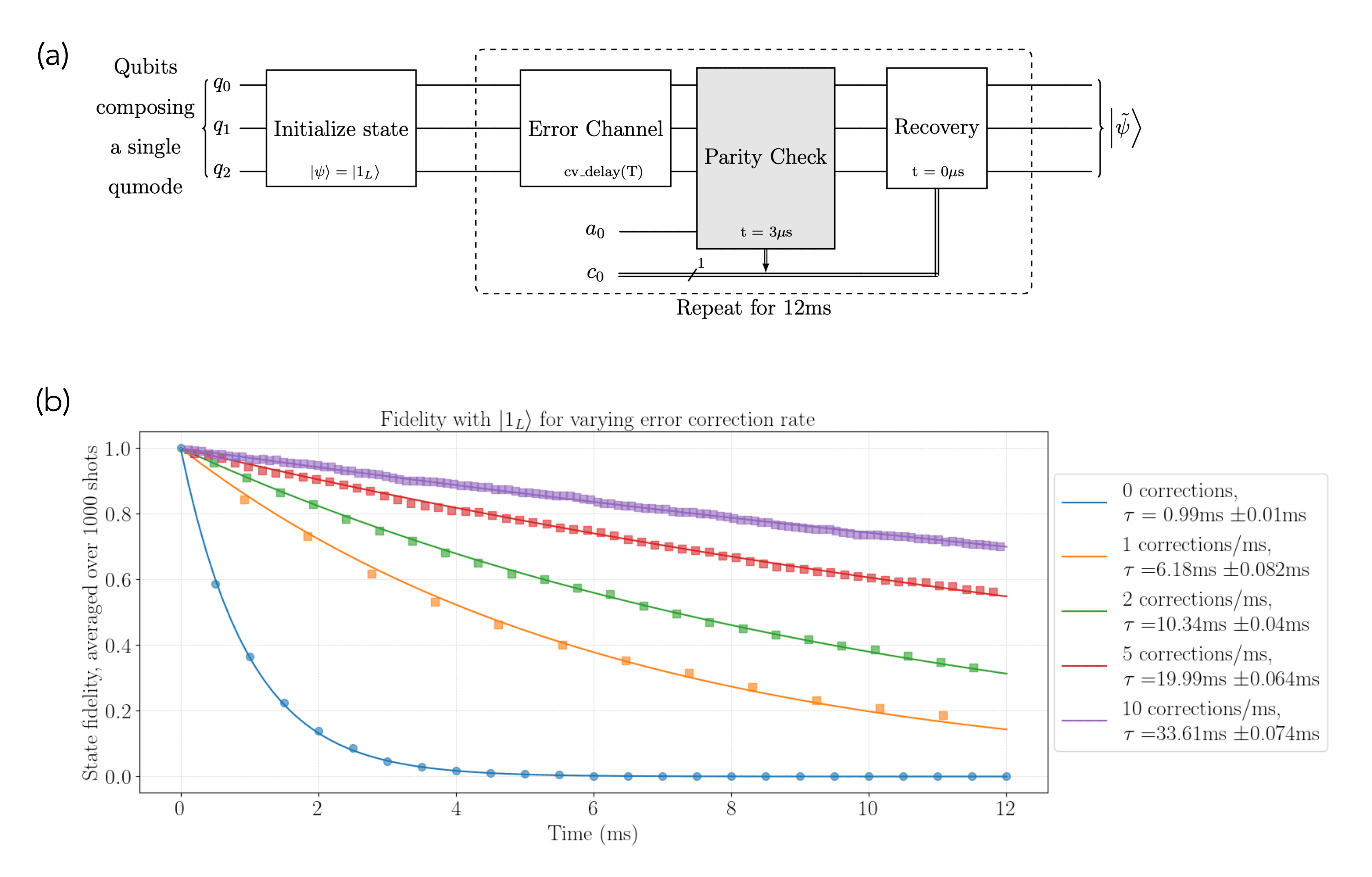
Finally, we can put these components together to realize the protocol illustrated in Figure 2a. As this simulation does not include any other errors beyond photon loss, it is possible for us to achieve arbitrary enhancement by increasing the rate of error-correction. (Note: This would not be the case in a more realistic model where ancilla and gate errors are included. We’ve included the ability to add these additional error types as an option in the full Jupyter notebook).
In Figure 2b, we show the average fidelity of the initially prepared logical state |1L ⟩ as a function of time for various error-correction rates. These results clearly demonstrate the expected trend that the lifetime of the logical state increases with the rate of error-correction.
For simplicity, here we have shown the results for the application of Û_odd only. For complete results that include Û_even , see the full implementation in the Jupyter notebook.
Figure 2: Implementation of the binomial “kitten” error correcting code. (a) A circuit implementing the error correction cycle. Here,cv_delay(T)implements the error channel for chosen time T. The parity check (during which errors can also occur) is used to detect errors. Finally, we apply a recovery operation dependent on the outcome of this measurement. This cycle is repeated for 12 ms. (b) State fidelity averaged over 1000 shots as a function of time for various error correction rate. The no error correction case is shown in blue, while successive colors illustrate the (theoretical) improvement in lifetime enabled by error correction. To extract estimates of the error-corrected lifetime, we have fit exponential curves to each data set.
Try it yourself!
In this article, we have described the basics of the binomial “kitten” code and have illustrated how to simulate it using the built-in features of Bosonic Qiskit. For more details on the full implementation that includes additional options (such as inclusion of Ûeven and ancillary qubit errors), we recommend that interested readers download the full Jupyter notebook, designed to be interactive such that users can generate error-correction simulations using parameters of their choosing.
For more information about Bosonic Qiskit, including installation instructions, see the GitHub repository. We particularly encourage new users to look at the tutorials and PyTest test cases. For those unfamiliar with bosonic quantum computation in general, we recommend the recently developed Bosonic Qiskit Textbook written by members of the Yale undergraduate Quantum Computing club Ben McDonough, Jeb Cui, and Gabriel Marous.
Bosonic Qiskit is a Qiskit ecosystem community project. Click here to discover more Qiskit ecosystem projects and add your own!
ICYMI: The National Strategy on Microelectronics Research, recently released by the White House Office of Science and Technology Policy, provides future-focused framework to shape U.S. leadership in #microelectronics. This guidance outlines four central goals supporting research and development, manufacturing infrastructure, an innovation ecosystem, and a robust technical workforce for next-gen advances. While DARPA is not funded by the CHIPS Act, agency leaders remain part of the cross-agency strategy, working collaboratively to accelerate U.S. #semiconductor R&D and strengthen national and economic security.
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
It’s official. After three years, the AI Act, the EU’s new sweeping AI law, jumped through its final bureaucratic hoop last week when the European Parliament voted to approve it. (You can catch up on the five main things you need to know about the AI Act with this story I wrote last year.)
This also feels like the end of an era for me personally: I was the first reporter to get the scoop on an early draft of the AI Act in 2021, and have followed the ensuing lobbying circus closely ever since.
But the reality is that the hard work starts now. The law will enter into force in May, and people living in the EU will start seeing changes by the end of the year. Regulators will need to get set up in order to enforce the law properly, and companies will have between up to three years to comply with the law.
Here’s what will (and won’t) change:
1. Some AI uses will get banned later this year
The Act places restrictions on AI use cases that pose a high risk to people’s fundamental rights, such as in healthcare, education, and policing. These will be outlawed by the end of the year.
It also bans some uses that are deemed to pose an “unacceptable risk.” They include some pretty out-there and ambiguous use cases, such as AI systems that deploy “subliminal, manipulative, or deceptive techniques to distort behavior and impair informed decision-making,” or exploit vulnerable people. The AI Act also bans systems that infer sensitive characteristics such as someone’s political opinions or sexual orientation, and the use of real-time facial recognition software in public places. The creation of facial recognition databases by scraping the internet à la Clearview AI will also be outlawed.
There are some pretty huge caveats, however. Law enforcement agencies are still allowed to use sensitive biometric data, as well as facial recognition software in public places to fight serious crime, such as terrorism or kidnappings. Some civil rights organizations, such as digital rights organization Access Now, have called the AI Act a “failure for human rights” because it did not ban controversial AI use cases such as facial recognition outright. And while companies and schools are not allowed to use software that claims to recognize people’s emotions, they can if it’s for medical or safety reasons.
2. It will be more obvious when you’re interacting with an AI system
Tech companies will be required to label deepfakes and AI-generated content and notify people when they are interacting with a chatbot or other AI system. The AI Act will also require companies to develop AI-generated media in a way that makes it possible to detect. This is promising news in the fight against misinformation, and will give research around watermarking and content provenance a big boost.
However, this is all easier said than done, and research lags far behind what the regulation requires. Watermarks are still an experimental technology and easy to tamper with. It is still difficult to reliably detect AI-generated content. Some efforts show promise, such as the C2PA, an open-source internet protocol, but far more work is needed to make provenance techniques reliable, and to build an industry-wide standard.
3. Citizens can complain if they have been harmed by an AI
The AI Act will set up a new European AI Office to coordinate compliance, implementation, and enforcement (and they are hiring). Thanks to the AI Act, citizens in the EU cansubmit complaints about AI systems when they suspect they have been harmed by one, and can receive explanations on why the AI systems made decisions they did. It’s an important first step toward giving people more agency in an increasingly automated world. However, this will require citizens to have a decent level of AI literacy, and to be aware of how algorithmic harms happen. For most people, these are still very foreign and abstract concepts.
4. AI companies will need to be more transparent
Most AI uses will not require compliance with the AI Act. It’s only AI companies developing technologies in “high risk” sectors, such as critical infrastructure or healthcare, that will have new obligations when the Act fully comes into force in three years. These include better data governance, ensuring human oversight and assessing how these systems will affect people’s rights.
AI companies that are developing “general purpose AI models,” such as language models, will also need to create and keep technical documentation showing how they built the model, how they respect copyright law, and publish a publicly available summary of what training data went into training the AI model.
This is a big change from the current status quo, where tech companies are secretive about the data that went into their models, and will require an overhaul of the AI sector’s messy data management practices.
The companies with the most powerful AI models, such as GPT-4 and Gemini, will face more onerous requirements, such as having to perform model evaluations and risk-assessments and mitigations, ensure cybersecurity protection, and report any incidents where the AI system failed. Companies that fail to comply will face huge fines or their products could be banned from the EU.
It’s also worth noting that free open-source AI models that share every detail of how the model was built, including the model’s architecture, parameters, and weights, are exempt from many of the obligations of the AI Act.
The decline of Generation Z’s mental health raises a red flag about the role phones play in childhood development. Although generations “are not monolithic,” Jonathan Haidt writes, “if a generation is doing poorly … the sociological and economic consequences will be profound for the entire society.”
Haidt looked to the 2010s for answers. What he found was the watershed transition from flip phones to smartphones, which likely contributed to rising levels of depression and anxiety in adolescents. “Once young people began carrying the entire internet in their pockets, available to them day and night, it altered their daily experiences and developmental pathways across the board,” he writes.
Today’s newsletter brings you stories about how smartphones have changed children’s lives.
• “End the Phone-Based Childhood Now,” by Jonathan Haidt. The environment in which kids grow up today is hostile to human development.
• “The Overprotected Kid,” by Hanna Rosin. A preoccupation with safety has stripped childhood of independence, risk-taking, and discovery—without making it safer. A new kind of playground points to a better solution. (From 2014)
• “I Won’t Buy My Teenagers Smartphones,” by Sarah P. Weeldreyer. Denying a teen a smartphone is a tough decision, and one that requires an organized and impenetrable defense. (From 2019)
• “Have Smartphones Destroyed a Generation?” by Jean M. Twenge. More comfortable online than out partying, post-Millennials are safer, physically, than adolescents have ever been. But they’re on the brink of a mental-health crisis. (From 2017)
• “The Dangerous Experiment on Teen Girls,” by Jonathan Haidt. The preponderance of the evidence suggests that social media is causing real damage to adolescents. (From 2021)
I’ve been experimenting with using AI assistants in my day-to-day work. The biggest obstacle to their being useful is they often get things blatantly wrong. In one case, I used an AI transcription platform while interviewing someone about a physical disability, only for the AI summary to insist the conversation was about autism. It’s an example of AI’s “hallucination” problem, where large language models simply make things up.
Recently we’ve seen some AI failures on a far bigger scale. In the latest (hilarious) gaffe, Google’s Gemini refused to generate images of white people, especially white men. Instead, users were able to generate images of Black popes and female Nazi soldiers. Google had been trying to get the outputs of its model to be less biased, but this backfired, and the tech company soon found itself in the middle of the US culture wars, with conservative critics and Elon Musk accusing it of having a “woke” bias and not representing history accurately. Google apologized and paused the feature.
In another now-famous incident, Microsoft’s Bing chat told a New York Times reporter to leave his wife. And customer service chatbots keep getting their companies in all sorts of trouble. For example, Air Canada was recently forced to give a customer a refund in compliance with a policy its customer service chatbot had made up. The list goes on.
Tech companies are rushing AI-powered products to launch, despite extensive evidence that they are hard to control and often behave in unpredictable ways. This weird behavior happens because nobody knows exactly how—or why—deep learning, the fundamental technology behind today’s AI boom, works. It’s one of the biggest puzzles in AI. My colleague Will Douglas Heaven just published a piece where he dives into it.
The biggest mystery is how large language models such as Gemini and OpenAI’s GPT-4 can learn to do something they were not taught to do. You can train a language model on math problems in English and then show it French literature, and from that, it can learn to solve math problems in French. These abilities fly in the face of classical statistics, which provide our best set of explanations for how predictive models should behave, Will writes. Read more here.
It’s easy to mistake perceptions stemming from our ignorance for magic. Even the name of the technology, artificial intelligence, is tragically misleading. Language models appear smart because they generate humanlike prose by predicting the next word in a sentence. The technology is not truly intelligent, and calling it that subtly shifts our expectations so we treat the technology as more capable than it really is.
Don’t fall into the tech sector’s marketing trap by believing that these models are omniscient or factual, or even near ready for the jobs we are expecting them to do. Because of their unpredictability, out-of-control biases, security vulnerabilities, and propensity to make things up, their usefulness is extremely limited. They can help humans brainstorm, and they can entertain us. But, knowing how glitchy and prone to failure these models are, it’s probably not a good idea to trust them with your credit card details, your sensitive information, or any critical use cases.
As the scientists in Will’s piece say, it’s still early days in the field of AI research. According to Boaz Barak, a computer scientist at Harvard University who is currently on secondment to OpenAI’s superalignment team, many people in the field compare it to physics at the beginning of the 20th century, when Einstein came up with the theory of relativity.
The focus of the field today is how the models produce the things they do, but more research is needed into why they do so. Until we gain a better understanding of AI’s insides, expect more weird mistakes and a whole lot of hype that the technology will inevitably fail to live up to.
Today, the FDA published its new paper, “Artificial Intelligence and Medical Products: How CBER, CDER, CDRH, and OCP are Working Together,” which outlines specific focus areas regarding the development and use of AI across the medical product lifecycle: https://lnkd.in/gPi8CcuX
The paper will help further align and streamline the agency’s work in AI. Read more about the agency’s AI initiatives on our website: https://lnkd.in/gUHD8-gZ
What is Artificial Intelligence?
Artificial Intelligence (AI) is a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments. AI systems use machine- and human-based inputs to perceive real and virtual environments; abstract such perceptions into models through analysis in an automated manner; and use model inference to formulate options for information or action. AI includes machine learning, which is a set of techniques that can be used to train AI algorithms to improve performance of a task based on data.
How does AI intersect with Medical Products?
AI has emerged as a transformative force. The Food and Drug Administration is responsible for protecting the public health by ensuring the safety, efficacy, and security of human and veterinary drugs, biological products, and medical devices; and by ensuring the safety of our nation’s food supply, cosmetics, and products that emit radiation. This landing page serves as your gateway to a wealth of information, resources, and insights into the intersection of AI and medical products. Learn more about how the FDA is shaping the future of health care through the responsible and innovative integration of AI.
How Center for Biologics Evaluation and Research (CBER), Center for Drug Evaluation and Research (CDER), Center for Devices and Radiological Health (CDRH), and Office of Combination Products (OCP) are working together?
The former Alphabet chair talked about the challenge of defining what society wants from artificial intelligence, and called for a balance between regulation and investing in innovation.
Artificial intelligence was a thing, but not the thing, when Eric Schmidt became CEO of Google in 2001. Sixteen years later, when he stepped down from his post as executive chairman of Google’s parent company, Alphabet, the world had changed. Speaking at Princeton University that year, Schmidt declared that we are in “the AI century.”
Their conversation came at a moment when AI is ascendant in both public and private imaginations.
Headlines are touting its accomplishments both small — winning an art contest at the Colorado State Fair — and large, such as predicting the shape of nearly every protein known to science. And the White House just released a blueprint for an AI Bill of Rights to “protect the American public in the age of artificial intelligence.”
Companies are investing billions of dollars in the technology and the talent necessary for its development (this includes Schmidt, who attracted attention last month for not publicly disclosing his investments in several AI startups while chairing the NSC commission).
Schmidt talked about the core challenge of defining what our society wants to gain from AI, and called for a balance between regulating AI and investing in innovation.
A pragmatic approach to development
Schmidt said a naive utopianism often accompanies technological innovation. “This … goes back to the way tech works: A bunch of people have similar backgrounds, build tools that make sense to them without understanding that these tools will be used for other people in other ways,” he said.
We should learn from these mistakes, Schmidt said. The tremendous potential of AI must not blind developers and regulators to the ways in which it can be abused. He cited the potential challenges of information manipulation, bioterrorism, and cyber threats, among many others. To the extent possible, guardrails must be in place from the beginning to prevent criminal or destructive applications, he said.
Schmidt also criticized the degree to which people working in AI have focused on the problem of bias. “We’ve all become obsessed with bias,” he said. It is an important challenge rooted in the data used to train AI systems, he acknowledged, but he said he was confident this would be fixed by using smaller data sets and zero-shot learning. “We’ll figure out a way to address bias,” he said. “Academics wrote all sorts of stuff about bias because that’s the thing that they could frame. But that’s not the real issue. The real issue is that when you start to manipulate the information space, you manipulate human behavior.”
Starting a productive discussion on regulation
One of the core challenges right now, according to Schmidt, is that we don’t have a clear definition of what we, as a society, want from AI. What role should it fill? What applications are appropriate? “If you can’t define what you want, it’s very hard to say how you’d regulate it,” he said.
To begin this process, one of Schmidt’s suggestions was a relatively small working group of 10 to 20 people who build a list of proposed regulations. These might include: making certain content, like hate speech, illegal; rules should be in place to distinguish humans from bots; all algorithms must be openly published.
This list, of course, is only a starting point. “Let’s assume that we got such a list — which we don’t have right now … How are you going to get the CEOs of the companies who are, independent of what they say, driven by revenue … to agree on anything?” Schmidt asked.
Government should do more than regulate
The role of government is not simply to regulate AI, Schmidt said. It must simultaneously promote the technology. Alongside a regulatory plan, Schmidt suggested every country should have a “how-do-we-win-AI” plan.
Looking to Europe, he described the admirable model of deep and long-term investment in big physics challenges. The CERN particle accelerator is one of many examples. But Schmidt does not see commensurate levels of investment in AI. “That’s a huge mistake, and it’s going to hurt them,” he said.
Investing productively in novel technologies while also devising regulation for those new technologies is difficult, Schmidt admitted, but he believes the tendency is to over-regulate and under-promote. As an example, he pointed to the European Union’s stringent online data privacy aims, embodied in the General Data Protection Regulation. While these efforts appear to do a good job protecting consumer data, high compliance costs have the unintended consequence of stifling innovation, Schmidt contended.
“You have to have an attitude of innovation and regulation at the same time,” he said. “If you don’t have both, you’re not going to lead.”
The particular case of social media
Social media presents specific challenges, Schmidt said. He pointed to problems with present-day platforms, which often started as basic information feeds and developed into recommendation engines. And the rules by which these engines operate may not be the rules we care about as citizens.