The current challenge for data science and technology (DST) in healthcare is moving beyond the “dancing bear” stage, where “the wonder is not how well the bear dances, but that he dances at all.” It’s time for DST to evolve past the novelty publications and the click bait, and demonstrate its ability to materially impact health and disease.
It’s easy to be misled by the deafening buzz. The conference circuit is now exploding with “AI and pharma” conferences (I’m speaking at several), consultants excitedly discuss pharma’s digital transformation (and convince each pharma they’re distinctly behind), and exuberant stories about the power of data and AI resound almost daily across social media.
Yet when you dive beneath the froth, a very different scenario is revealed. In an achingly perceptive 2017essay, Dr. Sachin Jain, former CMIO at Merck and now CEO of CareMore Health, candidly laments the unexpected gap between discussions of tech innovation in healthcare and actual tech innovation in healthcare, describing our present state as an “innovation bubble.”
“There is a disconnect between the conferences I attend, the journals and blogs I read, and the reality of medical practice on the frontlines of healthcare delivery. There is a ‘change layer’ – the cloud in which visionary ideas about transforming health care resides. But there is also a ‘reality layer’ – the place where most care is delivered. Both are necessary, but there is little mixing between them. So while there is a booming innovation industry – a new startup being created every day, a new app being launched every minute – the actual experience of delivering or receiving care is changing scarcely.”
While Jain touches briefly on pharma (he shares my observation that the eternal dream of creating a “service beyond the pill” has struggled), his focus is on healthcare delivery. Enter Vas Narasimhan.
Pharma, Powered By Data & Digital (?)
Narasimhan is the 42 year old physician and former McKinsey consultant who joined Novartis in 2005 and took the reigns as CEO last year, drawing attention with his focus on technology. “We need to become a focused medicines company that’s powered by data science and digital technologies,” hetoldtheWall Street Journalin Feburary 2018.
Now, a year into this new role, he’s had a chance to reflect on his company’s “digital journey” (as his McKinsey colleagues might say), which he’s graciously done in an absolutely captivating podcastinterviewwith several members of the silicon valley tech VC firm Andreessen Horowitz (best known for its slogan, “software is eating the world”). General Partners Jorge Conde and Vijay Pande, and Editorial Partner Sonal Chokshi, sat down with Narasimhan during the recent JP Morgan conference in San Francisco.
It’s hard to imagine a better window into how a forward-thinking large pharma, led by a relatively young, innovative physician leader, is actively wrestling with the issues and many challenges of incorporating DST approaches into their R&D efforts. The entire episode is a must-listen; I’ve extracted several key highlights, below, which reinforced in my mind both the difficulty and the urgency of leveraging DST approaches in pharma R&D.
Narasimhan sets the stage by pointing out the industry’s miserable attrition rate: of the twenty drugs that enter clinical studies, only one makes it. Worse, this rate apparently hasn’t moved in the last fifteen years, while costs have continued to increase). This is the fundamental problem (as I’ve alsoemphasized) for which the industry is trying to solve.
Narasimhan suggests increase costs reflect the increased complexity of clinical trials (essentially due to an increased amount of work each trial is being asked to do, gather information for regulators, of course, but also data that address scientific as well as market access questions). He reports that tech may be able to excise up to 20% of this cost (which sounds like a classic consultant SWAG).
Responding to a question, he said he saw a role for engineering especially in improving their processes around the manufacture of new categories of medicines, such as cell therapies and gene therapies, where he says the field is still at the “learning to crawl” stage. He also suggested engineers could contribute to chemical biology, helping to design more effective molecules rather than rely on empiricism to discover them.
AI – But First, Data
When asked about AI and ML, he began by level-setting: “As we’ve gotten quite scaled and working on digital health and data science, we’ve learned there’s a lot of talk and very little in terms of actual delivery of impact.”
Wow – “very little in terms of actual delivery of impact.”
“We’ve learned a lot,” he continued.
“The first thing we’ve learned is the importance of having outstanding data to actually base your ML on. In our own shop, we’ve been working on a few big projects, and we’ve had to spend most of the time just cleaning the data sets before you can even run the algorithm. That’s taken us years just to clean the datasets. I think people underestimate how little clean data there is out there, and how hard it is to clean and link the data.”
He did call out several areas of promise for AI. The first involved imaging – Novartis has embarked on a massive project to digitize all of their pathology images, he said, partnering with a startup called PathAI, as a prelude to machine learning. He can envision repeating this process for other categories of images as well. At the moment, this feels like a work in progress – lots of images being digitized, value of the effort TBD.
“Sounds like a gold mine,” Chokshi observed.
“It should be,” Narasimhan cautiously replied.
There are two areas where AI approaches are apparently already delivering actionable results: clinical trial operations and finance. In operations, Novartis has set up a control center that monitors all of their clinical trials. As Narasimhan describes it,
“A team sitting centrally in our headquarters can look at all our clinical trials in the world, and AI is predicting which of our trials are going to enroll on time or not enroll on time, and which ones are going to have quality issues or not have quality issues, and the reasons we could do this because we had ten years of history to train the algorithms, and we run about 400-500 clinical trials a year, so we had a lot of data on which we could train the algorithms.”
He notes that they’re not looking at patient-level data, but are, deliberately, a level up from that.
He also says that AI is proving quite useful in finance. “AI does a great job predicting our free cash flow,” he says, “predicting a lot of our sales for key products. It does better than our internal people because it doesn’t have the biases, and the data are really clean, and we have a lot of long-term data.
In short: one ambitious but unproven AI effort in science, two apparently successful efforts in non-science (operations and finance). Even there, I wonder if the role of “AI” is perhaps overstated, and means something different and less profound than when used in theDeepMind/AlphaZero context, but that’s just my hunch.
Similarly, look what Merck R&D head Roger PerlmuttertoldMatthew Herper (then at FORBES) in 2013:
“…if we’re discovering drugs, the problem is that we just don’t know enough. We really understand very little about human physiology. We don’t know how the machine works, so it’s not a surprise that when it’s broken, we don’t know how to fix it. The fact that we ever make a drug that gives favorable effects is a bloody miracle because it’s very difficult to understand what went wrong.”
And now, this month, look what Narashahim went out of his way to emphasize at the end of his podcast interview:
“What’s often lost on people is how incredible it is that we find any human medicines at all. Every human being is 40 trillion cells, working together. We understand a fraction of the proteins, what they do. 1200 drugable proteins, there’s only a fraction of those we can actually drug. We don’t know what most of RNA does, non-coding RNA, we don’t know most of what the genome is even talking about. Since the creation of FDA there’s only been about 1500 new molecular entities ever found, and most of those are overlapping in similar therapeutic areas. If you account for double counts, my guess is it’s in the hundreds of medicines that we’ve actually found.
It’s worth reflecting on how hard it is to do what we do. I tell our people, you have to think every medicine we find is a miracle that fits in the palm of your hand. We’ve unlocked, in a sense, a billion years of evolution of the eukaryotic cell and human biology and somehow we found something able to move the needle in this incredible complex system. I think that’s easy to forget when we overly simplify what we do.”
While humility is not generally the first quality one associates with CEOs, physicians, or McKinsey consultants, our staggering collective biological ignorance, and the enormity of the challenge of drug development, brings even the mighty to their knees.
For technologists hoping to impact disease, it will be critical to move away fromsolutionism, the belief that an app or an algorithm will effortlessly solve the complex and often ill-defined medical problems that plague patients and preoccupy drug developers. DST entrepreneurs need to evince some appreciation of the messy complexity of biology, and to understand just what they’re getting into – and to recognize that even a successful product is likely to solve only a very small (though potentially important) part of the overall problem.
Bottom Line
As Narasimhan emphatically conveyed, our understanding of the human organism, in both health and disease, is exceptionally primitive. It requires a strange combination of audacity and foolhardiness to believe you can create a product that will impact disease in a meaningful way. We need to bring our best technology – biological and digital – and our most creative people together to work on this monumental challenge.
One clear take-away from the Narasimhan interview: pharma is at the very earliest stages of figuring out how to do this.
Healthcare organizations across the country are beginning to cash in on early efforts in artificial intelligence and data visualization.
First reports on initial efforts to use these advanced technologies show tantalizing potential.
At Massachusetts General Hospital researchers have developed an AI algorithm to rapidly diagnose and classify brain hemorrhages from unenhanced computed tomography scans, detecting acute incidents and offering prediction capabilities that eventually could help staff in hospital emergency departments evaluate patients with acute stroke symptoms
Researchers led by Boston Children’s Hospital are using AI in combination with two forecasting methods to produce what they call the most accurate estimates of flu activity to date—a week ahead of traditional healthcare-based reports, at the state level across the United States. That could help providers get ahead of resource demands and better respond to current influenza trends.
HCA Healthcare, a Nashville, Tenn.‐based chain operating hospitals nationwide, estimates it has saved more than 5,500 lives using sepsis algorithms that monitor every patient in every hospital that’s been part of the health system for more than a year. The algorithmic system is getting impressive results in combating this life-threatening condition that is the ninth leading cause of death in U.S. hospitals.
Indeed, these clinical applications of AI and data visualization are where most healthcare organizations are concentrating early efforts in using this advanced assistive and predictive technology, according to results of a recent poll of Health Data Management readers.
More than half (53 percent) of respondents to the survey say their organizations are using these advanced analytic technologies to improve clinical decision making. That’s far and away the leading use of this information technology, but a range of other applications are being implemented, respondents say.
The study was conducted by Health Data Management and SourceMedia Research, the research arm of HDM’s parent company. A total of 160 responses, primarily from provider organizations, were received in late 2018.
More than a third of respondents—36 percent—say their organizations are using AI and data visualization to reduce the burdens that electronic health records systems pose to clinicians. Such efforts include initiatives to aid documentation, or to use data compiled in the EHR system to aid in making predictions to support patient care or organize preventive care efforts.
Another 34 percent of respondents are using AI and data visualization to turn the EHR into a reliable risk predictor. That’s exemplified by the work at HCA and many other provider organizations that are looking to be able to divine potential risks and make predictions on patients from the information in the clinical record.
In addition, respondents to the HDM survey say their organizations are using AI and data visualization to monitor health through wearables and personal devices (26 percent); to bring intelligence to medical devices and machines (24 percent); and to bring more precise analytics for pathology images.
Of all respondents, one in five (21 percent) say their organizations are not currently using AI and data visualization.
Despite all the budding efforts in using AI and predictive technologies, most respondents to the HDM survey believe their organizations still have work ahead to become more effective in the use of this IT.
In fact, only 7 percent say their organizations are extremely effective in using AI and data visualization, and only another 19 percent say they are very effective. More than a third—36 percent—say they are only somewhat effective, while a total of 27 percent of respondents say their organizations are either not at all effective or not very effective.
Those results make sense, because most of the work being done to integrate AI and other predictive technologies is happening at large academic medical organizations or hospital chains, which can bring sufficient economies of scale and research resources to investigating uses.
Beyond that, many organizations are still in the beginning phases of studying individual algorithms in specific use cases. Beyond identifying practical AI/data visualization uses, organizations still must determine how best to deploy multiple algorithms widely, having them work with minimal human intervention in the background of patient care.
But nearly half of respondents say figuring out how to deploy a wide range of AI and visualization tools will be crucial for their organizations. A total of 48 percent of respondents say that AI and data visualization will be either very important or extremely important to their organizations, while another 26 percent believe it will be somewhat important.
Keystone meetings are, by design, off the record, in effort to stimulate the free exchange of pre-publication information among participants; however, I’m going to talk about one of the presentations, by UCSF professor Dr. Aenor Sawyer, with her explicit permission.
Aenor Sawyer’s mission – bringing healthtech innovation into the healthcare system — and vision (pragmatic, inclusionary, optimistic) have always captivated me (she was actually one of our very first Tech Tonics guests, when Lisa Suennen and I started in Jauary 2015); perhaps the consummate example of the reflective practitioner, Aenor trained as an orthopedic surgeon, and is on faculty at UCSF. She has led and participated in multiple efforts focused on cultivating healthtech innovation at UCSF, and was recently named Chief Health Innovation Officer of NASA’s Translational Institute for Space Health (an organization helmed by another captivatingTech Tonics guest, Dr. Dorit Donoviel); Sawyer’s new role enables her to remain at UCSF continuing her commitments as well.
Sawyer’s presentation covered a range of topics, but I want to focus on several highlights: the primacy of “frontline innovation,” and her advice to would-be health tech entrepreneurs.
Frontline Innovators
In Sawyer’s view, successful innovation within healthcare system requires the early involvement of “frontline innovators” – who can be doctors, patients, other care providers, who are defined, in Sawyer’s view, by active engagement with a problem – problem solvers who are intensely frustrated by a specific aspect of the healthcare system that they touch, and are passionately interested in identifying a better approach.
Sawyer says frontline innovators bring unique value to developing successful solutions in that they understand the complexity of the problems, conceptualize solutions in context of the workflow (or identify where the workflow needs to be disrupted), and are dedicated to proving the effectiveness of solutions, as they will be using them for their patients. Frontline innovators are also eager to partner with external health tech developers or startups, and benefit from their complimentary skill sets in technology, design, product development, and commercialization.
Sawyer’s focus on frontline innovation turns out to reflect an important lesson of technology innovation (a point I also highlighted in a strikingly similar talk I presented on healthtech innovation within biopharma, and also wrote abouthere): implementation isn’t instantaneous, and it takes a long time to figure out how to use a powerful invention – this is the rule, not the exception.
In his essential treatiseLearning By Doing, technologist (and now Boston University professor)James Bessennotes that “major new technologies typically go through long periods of sequential innovation.” Similarly, in the context of transportation innovation, Northwestern economistRobert Gordonwrites (inThe Rise And Fall of American Growth), “Most of the benefits to individuals came not within a decade of the initial innovation, but over subsequent decades as subsidiary and complementary sub-inventions and incremental improvements became manifest.”
Finally, and perhaps most relevant, MIT innovation professorEric von Hippel(who I’ve frequently cited –here,here,here,here) has emphasized the importance of “field discovery,” and the criticality of “lead users” — practitioners keen to apply a promising approach to a pressing problem with which they’re actively wrestling; Hippel’s approach has generated so much traction he’s even created a “Lead User Project Handbook” to teach some of the associated methodology – he generously makes it available for free download at his website,here.
Lead users, as Hippel and colleaguesdescribe them, are “sophisticated product/service consumers who are facing and dealing with needs that are ahead of the bulk of the marketplace.” Lead usersprecede“early adopters,” who are among the first to adopt a new product or service; in contrast, lead users “are facing needs for products and services thatdon’t yet existon the market” (emphasis in original).
Data Overload And The “VNR”
Sawyer is captivated by the potential of technology and data to improve healthcare, entranced by the promise, but notes that in reality, there are “oceans of underutilized fragmented data, with much redundancy, instead of actionable insights.” This information overload tends to overwhelm everyone, she notes, contributing to provider burnout, and leaving patients frustrated with what to do with a lot of disconnected data; not surprisingly, she points out, nearly half of wearables wind up in the drawer by six months.
Sawyer coined a concept I really liked, the “VNR” (a play on the “INR” ratio used to modulate warfarin dosing), which stands for “Value to Nuisance Ratio.” Essentially, a VNR > 1 is good, it means a device or approach is likely to be used; a value < 1 is bad, likely a technology that seemed clever or helpful in theory but in practice turned out to be more trouble than it was worth.
In her role at UCSF, Sawyer encounters many startup entrepreneurs, who she jokes are so plentiful in the hospital corridors that they “may be the new drug reps.” (I suspect this may be less of an issue at hospitals outside the Bay Area, though I’d love to be mistaken). In her discussions with these startups, Sawyer’s observed several common problems, areas of disconnect between what the entrepreneurs think they’re offering and what the healthcare system needs.
An incomplete understanding of the problem being addressed.
Technologies without clear evidence (i.e. effectiveness in care and cost): hospitals can’t tell value of new solutions due to a paucity of evidence, unclear, for example, when the proposed innovation will pay for itself.
Point solutions that haven’t thought through the requisite integration. An effective solution ultimately needs to be part of an end-to-end solution, and demonstrable compatibility with adjacent processes already in place. Startups proposing novel solutions must consider not only such interoperability, but also develop an implementation plan (beyond the ubiquitous assertion Sawyer says is made by all startups, “we integrate with Epic”) and account for the associated cost. This evokes themes recently highlightedby Venrock VCs Bryan Roberts and Bob Kocher, though they seemed to emphasize the need to build a “full stack” platform (a la Venrock portfolio companyVirta– see CEO Sami Inkinen description of the concepthere), while Sawyer’s focus was on the need for well-thought-out health tech integration within hospital systems and provider workflow. (As a side-note: another company that seems to have pivoted or evolved towards the “full stack” model, in this case for the treatment of serious mental health disorders, isMindstrong.)
Misaligned business models: entrepreneurs need to understand and be able to articulate who is the payor, who is the user, and what’s a meaningful return on investment (ROI) or improved outcome.
Need to move beyond pilots to appropriate engagements with healthcare systems. This echoes an increasingly common theme – that entrepreneurs are embarking on “pilots to nowhere” – seethis2016 Lisa Suennen, for example.
Unrealistic investor expectations. This was one of the most interesting points – the argument that tech VCs funding some of the health tech companies are bringing with them metrics and a set of expectations that might be appropriate for other industries, but are arguably less relevant in healthcare. Instead of pushing to get paying customers, Sawyer argues, smart healthtech startups should focus on evidence generation, which in her view is what ultimately drives adoption and yields success.
In Sawyer’s view, many startups are soliciting pilots when in fact they really should be getting frontline innovator input on their proposed solution, and thinking a lot more about evidence generation; she notes she’s spoken with over 300 startups in the last several years, and the vast majority (over 80%) really aren’t ready for a meaningful pilot, and need to refine their proposed offering first.
From Mega Data To Matta Data
Sawyer also emphasizes the importance of going “from mega data to ‘matta’ data” – data that matters. The ultimate goal of data generation and analysis in healthcare, she points out, is to lead to well-informed actions.
Solution builders, Sawyer says, would do well to:
“Recognize that healthcare is complicated. Don’t oversimplify it.
Ensure your conceptualization of a solution includes personnel, process and technology – and it’s critical to address culture and workflow.
Don’t duck the hard stuff: security, privacy, regulatory, and cultural resistance.
Realize that evidence is a good business model.
Include frontline innovators on team from day 1”
The point about evidence seems especially salient in light of a recentpaperby Ioannidis and colleagues noting that, as TechCrunch succinctlysummarized, “Most of the highest-valued startups in healthcare have not published any significant scientific literature.”
As Ioannidis et al write, “[I]n contrast to the tech sector, in healthcare published peer‐reviewed research is essential to ensure a minimum threshold of transparency, accountability, and credibility for the underlying work in the scientific community.”
Sawyer’s message isn’t only for startups. Healthcare organizations, for their part, says Sawyer, need to support internal and external innovation and the bridge between them. She argues they need to provide mechanisms and funding for frontline innovators and need to improve how the healthcare system engages with external entrepreneurs, providing more open and efficient partnering models for collaboration, validation, and even co-development.
Taking a step back here, you can see how difficult innovation within healthcare systems is, leaving would-be innovators with two unpalatable choices, at least in the extreme: innovate entirely outside of the existing system, and compete with entrenched incumbents who are experts at working the established processes; or develop a solution for use by incumbents, which involves integrating with byzantine systems and stultifying (if familiar) workflows.
You can also see why “full stack” approaches focusing on outcomes offer so much appeal, offering a potential way to break free; you can largely work outside the existing system, but connect with it in what might be a value-add fashion (assuming you can find someone willing to pay for the value…).
As I understand it, this is what Virta does (reminder:I’m a non-diabetic, paying customer, not an investor). They basically offer to manage the type two diabetes care for patients on the program – their licensed physicians adjust doses, track labs, advise patients, and remain in contact with the patient’s primary care physicians. In some ways, this might be described as type two diabetology-as-a-service. If you believe Virta generates good outcomes, you can see how it might make sense in a value-based care world, but also how it might run into difficulties in fee-for-service health settings, where there is enormous pressure on physicians to keep as many referrals as possible within the system. (If you ever want to depress yourself, Google “referral leakage,” and you’ll discover there’s a whole industry devoted to reducing this “problem.”)
Bottom Line
Innovation within the healthcare system can be exceptionally challenging, as UCSF professor Aenor Sawyer helpfully summarizes. Tech entrepreneurs should work closely with front-line innovators to ensure their company is focused on a relevant problem and is developing an implementable solution; innovators must also recognize that robust evidence of impact (not just clicks or eyeballs) is essential for adoption by most established players.
There was a time when the world’s two great superpowers were obsessed with nuclear weapons technology. Today the flashpoint is between the US and China, and it involves the wireless technology that promises to connect your toaster to the web.
The two countries are embroiled in a political war over the Chinese telecommunications company Huawei. The Americans have recently stepped up long-standing criticisms, claiming the tech giant hasstolen trade secretsandcommitted fraud, and that it hasties to the Chinese governmentand its military.
The company denies the charges and has sought todefend its recordon privacy and security. Meanwhile, US allies including Great Britain, New Zealand, Australia, Canada, Germany, and Japan have all either imposed restrictions on Huawei’s equipment or are considering doing so, citing national security concerns.
Behind the headlines, though, the spat is also about the coming wave of networking technology known as 5G, and who owns it.
Here are five things you need to know about the technology and its role in the tensions.
1. WHAT IS 5G?
Rather than a protocol or device, 5G refers to an array of networking technologies meant to work in concert to connect everything from self-driving cars to home appliances over the air. It’s expected to provide bandwidth of up to 20 gigabits per second—enough to download high-definition movies instantly and use virtual and augmented reality. On your smartphone.
The first 5G smartphones and infrastructure arrive this year, but a full transition will take many more years.
2. WHY IS IT BETTER?
5G networks operate on two different frequency ranges. In one mode, they will exploit the same frequencies as existing 4G and Wi-Fi networks, while using a more efficient coding scheme and larger channel sizes to achieve a 25% to 50% speed boost. In a second mode, 5G networks will use much higher, millimeter-wave frequencies that can transmit data at higher speeds, albeit over shorter ranges.
Since millimeter waves drop off over short distances, 5G will require more transmitters. A lot of them, sometimes just a few dozen meters apart. Connected devices will hop seamlessly between these transmitters as well as older hardware.
To increase bandwidth, 5G cells also make use of a technology known as massive MIMO (multiple input, multiple output). This allows hundreds of antennas to work in parallel, which increases speeds and will help lower latency to around a millisecond (from about 30 milliseconds in 4G) while letting more devices connect.
Finally, a technology called full duplex will increase data capacity further still by allowing transmitters and devices to send and receive data on the same frequency. This is done using specialized circuits capable of ensuring that incoming and outgoing signals do not interfere with one another.
3. WHAT ARE THE SECURITY RISKS?
One of 5G’s biggest security issues is simply how widely it will be used.
5G stands to replace wired connections and open the door for many more devices to be connected and updated via the internet, including home appliances and industrial machines. Even self-driving cars, industrial robots, and hospital devices that rely on 5G’s ever-present, never-lagging bandwidth will be able to run without a hiccup.
As with any brand-new technology, security vulnerabilities are sure to emerge early on. Researchers in Europe have alreadyidentified weak spotsin the way cryptographic keys will be exchanged in 5G networks, for example. With so many more connected devices, the risk for data theft and sabotage—what cybersecurity folks call the attack surface—will be that much higher.
Since 5G is meant to be compatible with existing 4G, 3G, and Wi-Fi networks—in some cases using mesh networking that cuts out central control of a network entirely—existing security issueswill also carry over to the new networks. Britain’s GCHQis expectedto highlight security issues with Huawei’s technology, perhaps involving 4G systems, in coming weeks.
With 5G, a layer of control software will help ensure seamless connectivity, create virtual networks, and offer new network features. A network operator might create a private 5G network for a bank, for instance, and the bank could use features of the network to verify the identities of app users.
This software layer will, however, offer new ways for a malicious network operator to snoop on and manipulate data. It may also open up new vectors for attack, whilehardware bugscould make it possible for users to hop between virtual networks, eavesdropping or stealing data as they do.
4. CAN 5G BE MADE SECURE?
These security worries paint a bleak picture—but there are technical solutions to all of them.
Careful use of cryptography can help secure communications in a way that protects data as it flows across different systems and through virtual networks—even guarding it from the companies that own and run the hardware. Such coding schemes can help guard against jamming, snooping, and hacking.
As the world’s biggest supplier of networking equipment and second largest smartphone maker, Huawei is in a prime position to snatch the lion’s share of a 5G market that,by some estimates, could be worth $123 billion in five years’ time.
Stalling the company’s expansion into Western markets could have the convenient side effect of letting competitors catch up. But there are also legitimate security concerns surrounding 5G—and reasons to think it could be problematic for one company to dominate the space.
The US government appears to have decided that it’s simply too risky for a Chinese company to control too much 5G infrastructure.
The focus on Huawei makes sense given the importance of 5G, the new complexity and security challenges, and the fact that the Chinese company is poised to be such a huge player. And given the way Chinese companies are answerable to the government, Huawei’s apparent connections with the Chinese military and its cyber operations, and thetightening ties between private industry and the state, this seems a legitimate consideration.
But the ongoing fight with Huawei also goes to show how vital new technology is to the future of global competition, economic might, and even international security.
Will Knight isMIT Technology Review’s Senior Editor for Artificial Intelligence. He covers the latest advances in AI and related fields, including machine learning, automated driving, and robotics. Will joinedMIT Technology Reviewin…More
The Department of Defense and the Department of Veterans Affairs may be considering merging parts of their two health care programs in a move that could alter how about 19 million military personnel, retirees, dependents and veterans receive care.
In an announcement released Jan. 31, the Defense Health Agency said that an initiative known as DOD VA Health Care Staffing Services has reached the “strategy development stage.” The effort is designed to merge the delivery of health care using facilities run by both agencies to serve the two populations of beneficiaries in a combined fashion, according to veterans’ advocates.
“The idea in itself makes sense,” said Pat Murray, Deputy Director of the National Legislative Service for Veterans of Foreign Wars. “But it’s going to be a lot harder than I think they understand.”
“I think you have the possibility to save,” said Kathy Beasley, Director of Health Affairs for the Military Officers Association of America. “Where there might be excess capacity in one area it may be utilized by beneficiaries in the other,” Beasley said.
In October, the DHA, which oversees the health care system for the 9.4 million participants in the military, sought health-care company feedback on the private industry’s ability to supplement clinical operations in Pentagon and VA facilities. That request also said DHA had “partnered with the VA to determine the feasibility of a joint strategic solution for the delivery of integrated, high-quality health care services to 19 million beneficiaries.”
Although the two health care systems serve populations of roughly similar numbers, they deliver care differently and serve a different clientele: The VA on average treats an older population, while DOD deals more with younger individuals and families.
The move would offload some of the VA’s burden onto the military health care system, according to Murray. VA has struggled in recent years to provide timely care to veterans within its internal systems. Congress overhauled a community care program in 2018 that expands opportunities for veterans to receive government-subsidized care from private providers.
In December, the VA announced the award of the first three of six contracts for its community care program, which will greatly expand the use of civilian providers. Bloomberg Government has estimated that health spending through the private health care program could reach as much as $21 billion annually.
Political Resistance
A merger of the two health care systems is likely to be a complex undertaking compounded by political resistance. Both veterans’ service organizations and those that represent military personnel are always concerned that drastic changes to their members’ health systems will have a negative impact on care.
The Trump administration and officials from both departments came under fire in 2017 for secretly considering merging parts of the two health care systems. Lawmakers said any attempt to combine the two would require congressional oversight and significant input from stakeholders.
Political infighting over community care also led to the ouster of then-VA Secretary David Shulkin in 2018. Democrats have promised to stop any further health care privatization attempts at the agency and are already gearing up for a fight over the implementation of the community care overhaul.
Not every stakeholder will resist the idea, however: The proposal could present enormous opportunities for federal contracts both in resolving the technical and logistical barriers to the merger and in the further expansion of the Tricare and community care programs into the private sector.
To contact the reporters on this story: Robert Levinson in Washington, D.C. at rlevinson@bgov.com; Megan Howard in Washington at mhoward@bgov.com
Google is committed to using its machine learning technology in health care. Just one of a handful of projects underway at Google Brain, its research group, involves figuring out potential medical events based on a massive store of clinical data provided by local Bay Area hospitals. Its computers might soon determine whether patients are at a higher risk of a potentially life-threatening disease like sepsis, or are more likely to be readmitted to the hospital after discharge.
Google is building tools to predict when you’ll get sick.
The company is applying its machine learning expertise, which it originally developed for consumer products like Translate and Image Search, to health care. To get there, it worked with hospitals, including Stanford Medicine, UC San Francisco and The University of Chicago Medicine, which stripped millions of patient medical records of personally identifying data and shared them with Google’s research team,Google Brain.
“We can improve predictions for medical events that might happen to you,” said Katherine Chou, the head of product at Google Brain, in an interview with CNBC. “We have validated the data and seen promising results.” Those results will not be released until a formal review process.
Hospitals are increasingly under the gun to keep patients healthy and out of the emergency room. Increasingly, health systems are shifting away from “fee for service” models, in which they get paid for pricey tests and procedures, to “value-based care,” where they’re rewarded for improving health outcomes. That shift is a big opportunity for Silicon Valley’s technology companies and startups, which are working with existing data to help hospitals take proactive steps to keep their patients healthy.
So, for instance, a computer might soon determine the likelihood that certain patients will acquire a potentially life-threatening disease like sepsis, or end up being readmitted after being discharged from the hospital.
The advance also addresses a big problem in medical specialties like radiology and pathology, where clinicians are saddled with a massive amount of information and too little time. Even a well-trained human eye can occasionally miss something.
Many of the top hospitals have their own technology teams, but they pale in comparison to the computing talent at Google. For Atul Butte, director of the Institute of Computational Health Sciences at UCSF, the draw was Google’s amazing in-house machine learning expertise.
Butte said the project “bubbled up” because UCSF has a wealth of medical data, including admissions reports, medical records, diagnoses, lab results and so on, but it has not yet mined this information to make predictions about patient outcomes.
“This isn’t a research project,” he said. “It’s more of a scientific collaboration around improving the quality of care for patients.”
For telcos to keep and grow market share, the network division needs a makeover that lets it shed its cost-center past to become a leading function that influences the digital and analytics metamorphosis of the core.
You move to a new city for work and decide to switch to the well-regarded local leader in mobile services. You go to its website and port your number over, and, in seconds, your new service is working.
Soon, however, you experience some dropped calls and sluggish data in your apartment. The problem clears up quickly, though, after your provider’s analytics identify you as a new customer in a key demographic who is experiencing service issues in a location where you frequently use your mobile phone. The provider’s automated remediation confirms your apartment is in a strategic region with spare spectrum available and promptly provisions additional capacity.
That level of seamless customer service may seem like a distant dream. But if telcos are going not just to survive but also to thrive amid today’s competitive disruption, it needs to become a reality in the not-too-distant future. Critical to that happening is the network, which must enable such superior customer experience.
But to do so, the network itself must undergo a radical transformation, shifting from a black-box cost center to a genuine change agent. It needs to leverage its unique position as the owner of the company’s largest asset and the richest source of the data that generate key customer insights.
A makeover for the network
Despite (or perhaps because) the network accounts for such a large share of both operating and capital budgets (typically 30 to 40 percent), it has traditionally been relegated to the back of the organization, asked to help with cost cutting, while real change is led by commercial units (such as product and customer care) or the IT team (through system and software). This status goes hand in hand with the network and the network organization’s long-standing image as monolithic and mired in complexity. The work done is still rooted in the technological limitations of the past: basic functions require long lead times, standard feature sets offer little customization, capacity can’t be scaled dynamically, and processes are complex and rigid.
However, technologies have evolved to a point that networks can now be more digital and, as a result, more dynamic, flexible, and customizable. The use of analytics and artificial-intelligence (AI) techniques, like machine learning, can make the systems intelligent and more automated, enabling predictive and near-real-time actions. These solutions, coupled with an agile organizational model, can catapult the network team to become the driver of any telco’s digital agenda.
Before telcos get there and fully realize the potential of the network of the future, they must make sure it is defined by five key characteristics (Exhibit 1). And once it is, the payoff could be substantial.
Modular
Today’s network architectures are made up of multiple hardware boxes interconnected through the core. Network functions are loosely tied to customer-facing functions. The network of the future, however, will be more software based and modular—otherwise known as network as a service (NaaS)—allowing it to adapt to changing customer needs much more quickly and efficiently and to scale capacity dynamically based on user or application when needed (Exhibit 2).
Bringing modularity to the network involves three key considerations:
End-to-end process changes and simplification. Deploying the latest technologies, such as network-functions virtualization (NFV) and software-defined networking (SDN), should be accompanied by changes in the associated processes. One European operator had to rethink the B2B service-provisioning process completely by leveraging the virtual customer-premises equipment (vCPE) to provision services remotely based on demand. In doing so, it was able to reduce the service-provisioning time from two weeks to just a few minutes.
Jointly defined use cases. Typically, these initiatives led by the network team are viewed as technology solutions. However, deploying them also offers business use cases. For that reason, the network and business teams need to work together to craft the use cases and road map for building them. A European operator’s network organization worked with the commercial teams to define and prioritize Internet of Things (IoT) use cases that would be supported in the network through application programming interfaces (APIs) for provisioning the service and to provide additional capacity.
Capability enhancements. Moving toward a NaaS model requires new capabilities within the network team. Previously, network teams were more engineering and operations focused; they now need to develop service-management and software-development capabilities.
Agile
The way network teams organize themselves is a critical determinant of how effective telcos are in leveraging the new network paradigm. Such organizations today are typically centered around major functions, such as planning, engineering, and operations, which has served them well.
Yet, as telcos go digital, the overall organization design is being revamped. Agile structures centered around digital tribes are taking root, mainly driven by the need to respond immediately to customer demands. This requires rapid iterations and decision making enabled by simplified processes and governance (Exhibit 3).
Exhibit 3
This is a complex transition that requires telcos to ask themselves two important questions:
What should be the scope of agile transformation within the network team? There are two potential models to choose from:
Based on the nature of activities. Functions that have shorter lead times and are closer to the customer, such as provisioning and configuration changes, move to an agile model, while infrastructure changes that require longer lead times remain traditionally managed.
Full agile. In this model, all functions are moved into agile tribes. A leading Asian telco, for instance, revamped its network organization into two tribes from a previous state of six subdepartments.
What should be the agile organizational design? Multiple agile design choices, such as flow to work, self-managing teams, end-to-end cross-functional teams, and agile overlay, could be evaluated. The choice of the design should be based on factors such as the scope of the functions going agile, the interface with the rest of the organization, and ease of implementation.
Automated
Adoption of analytics and automation is increasing, and many telcos have started building use cases and setting up centers of excellence. As network teams evaluate the next steps in their automation journeys, leaders need to assess three considerations:
Look beyond telecom. Inspiration for the automation journey should come from the best places and organizations, not just from within the industry. Telcos need to step outside of their peer set to look for inspiration on leading practices. For example, in transforming the customer-care journey, one telco took inspiration from various sources: a healthtech provider for building an AI engine to diagnose CPE issues and a heavy-machinery manufacturer for deploying augmented reality within its field-installation guides. Going outside the industry helped the telco capture an additional 5 to 7 percent productivity spike.
End-to-end automation. Ensuring end-to-end digitization across the network life cycle, as opposed to tactical automation of a single process, is essential. Consider the entire deployment journey, starting with the design of the network and continuing all the way to implementation and optimization. One telco used a zero-based-design approach to reimagine the entire deployment journey, weaving together disparate legacy tools, tactical process robotics, and machine-learning use cases to reduce end-to-end deployment time by 30 percent.
Architecture that supports scale. Driving impact at scale would be challenging if the digital architecture that supports network deployment and operations tools is neglected. Network teams should consider how they can build a modern, future-proof digital architecture that allows them to reduce their technical debt, adapt rapidly to new technologies, and capture and build on a wealth of data about the network (Exhibit 4).
Personalized
With the advent of NaaS, there will be increasing demand to offer customized bandwidth for different types of services. Network slicing enables operators to configure multiple logical networks to run on top of a shared physical infrastructure. Deploying network slicing involves two important considerations for operators:
‘Hyperpersonalized’ business models. Network slicing allows for operators to provide personalization at various levels. At the highest level, operators can distinguish between B2B and B2C services. Within B2B, for example, they can offer different classes of services (such as for IoT and vehicular communications). In B2C, operators can differentiate among the bandwidths being offered to various customer segments. This enables operators to move toward new business models centered around hyperpersonalization that require close coordination with business teams.
Trade-offs between multiple virtual layers and multiple physical layers. As the list of possible next-generation services keeps growing, implementing multiple virtual-network slices for each type of service may be very inefficient in terms of resources. Alternatively, deploying separate physical subnetworks with their own physical and functional layers may be a more viable option, but it requires more investment. The right balance between these two options needs to be studied based on the overall company strategy and outlook.
Insight generating
Given that all customer services have to pass through the network in one form or another, the network collects a trove of valuable information on the customers. This can include mobility patterns, call-usage records, and credit information, for example. Moreover, since network nodes and sites are distributed across a given country in which coverage is being provided, the network data can be localized to particular microlocations. (Such solutions would, of course, require careful consideration of matters around regulation, privacy, and customer consent.)
The building blocks telcos need to create their digital-and-analytics DNA
By leveraging advanced-analytics techniques on these data, operators are starting to tap into rich insights to which they previously didn’t have access. However, chief technology officers (CTOs) should look to three key areas to take full advantage of these insights:
Going beyond the network. While telcos are already making progress in leveraging advanced analytics on network data to drive operational insights (such as predictive-maintenance models), network teams can potentially increase impact from these data significantly by combining them with customer insights. For example, can propensity to churn models improve precision by incorporating recent network key performance indicators (KPIs) as inputs? Similarly, can KPIs go beyond network focus into measuring customer experience by combining data from devices, service touchpoints, and network operations?
Cross-functional engagement. Getting the most value from analytics use cases would require engaging cross-functionally with other relevant teams to ensure there is a holistic view of value and there are robust approaches to execute. CTOs should consider whether the current engagement model (including forums, frequency, and ways of working) among their own network teams and others (including marketing and finance teams) are enabling or hindering such cross-team collaboration and what might be needed to knock down organizational silos.
Data architecture. Bringing data from multiple sources (network elements or organizational data, for example) requires scalable, cohesive data strategy and architecture to enable use-case deployment at scale. In an environment dominated by budget constraints, network teams should critically evaluate their data strategies to ensure that they optimize value from existing investments, that additions are backed by specific use cases, and that there is a clear link between the architectural road map and business value.
In this vision of network transformation, it’s not just the network stature that is transformed. The role of the CTO is enhanced, going from playing a supporting role to leading the charge on digital transformation. As 5G deployments weigh heavily on already stretched capital budgets, such a transformation could also enable CTOs to achieve significantly lower costs with operating-budget benefits of 20 to 30 percent per year and capital-budget improvements of 15 to 20 percent per year (on a like-for-like basis).
The vision for this network is long term, but without concrete steps now, network teams might face an increasingly uphill task, and offering the best network to subscribers might come at a heavy price. To get started, network teams should define a holistic end-state idea for networks based on the five elements of the network of the future, their own guiding principles, and the operating models required to achieve them. Network teams should also consider conducting proofs of concept in selected areas (for example, agile B2B provisioning or analytics-driven field dispatch) to start making the vision a reality.
Transformation, after all, is about changing mind-sets and how we do things—and, ultimately, about perceived positioning in the company and external world. The question for CTOs and network leaders is: Do you want to play defense and keep explaining and justifying capital expenditures to the board, or do you want to shape the whole company’s agenda?
About the author(s)
Kim Baroudy is a senior partner in McKinsey’s Copenhagen office, where Halldor Sigurdsson is a partner; Sunil Kishore is a partner in the Atlanta office; Nitin Mahajan is a partner in the Singapore office; Sumesh Nair is an associate partner in the London office; and Kabil Sukumar is an associate partner in the Kuala Lumpur office.
GOOGLE HAS ITS OWN EHR PLAN: The U.S. Patent Office last Thursday published a40-page applicationthat Google submitted in July 2017 for what’s essentially a new type of EHR consisting of three pieces. It would include a computer memory storing aggregated EHR data from millions of patients; a computer executing deep learning on those records in a standardized data structure format, and an interface for clinicians displaying salient facts from the patient’s past and predicted future clinical events.
The application, whose inventors include 21 Google employees including Google.ai leader Jeffrey Dean, notes the “need for systems and methods to assist health care providers to allocate their attention efficiently among the overabundance of information from diverse sources, as well as to provide predictions of future clinical events and highlighting of relevant underlying medical events contributing to these predictions.” The invention “addresses a pressing question facing the physician in the hospital, namely, which patients have the highest need for my attention now, and … what information in the patient’s chart should I attend to.”
It includes a hypothetical case of an alcoholic’s withdrawal symptoms being mistaken for septic shock (the computer, natch, would have made the right call).
A Google spokesperson had no comment but pointed to the article Google scientists published with colleagues from Stanford, UCSF and the University of Chicagolast May, in which they used FHIR resources to create a data format that enabled them to crank through thousands of records and come up with accurate retrospective outcome predictions.
AI is not a silver bullet, but it could help tackle some of the world’s most challenging social problems.
Artificial intelligence (AI) has the potential to help tackle some of the world’s most challenging social problems. To analyze potential applications for social good, we compiled a library of about 160 AI social-impact use cases. They suggest that existing capabilities could contribute to tackling cases across all 17 of the UN’s sustainable-development goals, potentially helping hundreds of millions of people in both advanced and emerging countries.
Real-life examples of AI are already being applied in about one-third of these use cases, albeit in relatively small tests. They range from diagnosing cancer to helping blind people navigate their surroundings, identifying victims of online sexual exploitation, and aiding disaster-relief efforts (such as the flooding that followed Hurricane Harvey in 2017). AI is only part of a much broader tool kit of measures that can be used to tackle societal issues, however. For now, issues such as data accessibility and shortages of AI talent constrain its application for social good.
This article is a condensed version of our discussion paper, Notes from the AI frontier: Applying AI for social good (PDF–3MB). It looks at domains of social good where AI could be applied, and the most pertinent types of AI capabilities, as well as the bottlenecks and risks that must be overcome and mitigated if AI is to scale up and realize its full potential for social impact. The article is divided into five sections:
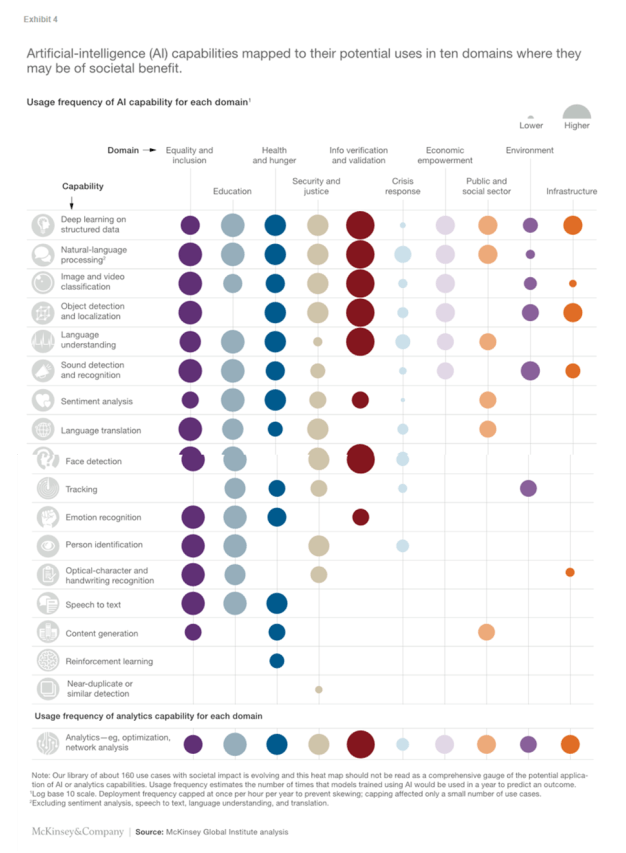
For the purposes of this research, we defined AI as deep learning. We grouped use cases into ten social-impact domains based on taxonomies in use among social-sector organizations, such as the AI for Good Foundation and the World Bank. Each use case highlights a type of meaningful problem that can be solved by one or more AI capability. The cost of human suffering, and the value of alleviating it, are impossible to gauge and compare. Nonetheless, employing usage frequency as a proxy, we measure the potential impact of different AI capabilities.
For about one-third of the use cases in our library, we identified an actual AI deployment (Exhibit 1). Since many of these solutions are small test cases to determine feasibility, their functionality and scope of deployment often suggest that additional potential could be captured. For three-quarters of our use cases, we have seen solutions deployed that use some level of advanced analytics; most of these use cases, although not all, would further benefit from the use of AI techniques. Our library is not exhaustive and continues to evolve, along with the capabilities of AI.
Crisis response
These are specific crisis-related challenges, such as responses to natural and human-made disasters in search and rescue missions, as well as the outbreak of disease. Examples include using AI on satellite data to map and predict the progression of wildfires and thereby optimize the response of firefighters. Drones with AI capabilities can also be used to find missing persons in wilderness areas. Economic empowerment With an emphasis on currently vulnerable populations, these domains involve opening access to economic resources and opportunities, including jobs, the development of skills, and market information. For example, AI can be used to detect plant damage early through low-altitude sensors, including smartphones and drones, to improve yields for small farms. Educational challenges
These include maximizing student achievement and improving teachers’ productivity. For example, adaptive-learning technology could base recommended content to students on past success and engagement with the material.
Environmental challenges
Sustaining biodiversity and combating the depletion of natural resources, pollution, and climate change are challenges in this domain. (See Exhibit 2 for an illustration on how AI can be used to catch wildlife poachers.) The Rainforest Connection, a Bay Area nonprofit, uses AI tools such as Google’s TensorFlow in conservancy efforts across the world. Its platform can detect illegal logging in vulnerable forest areas by analyzing audio-sensor data.
Equality and inclusion
Addressing challenges to equality, inclusion, and self-determination (such as reducing or eliminating bias based on race, sexual orientation, religion, citizenship, and disabilities) are issues in this domain. One use case, based on work by Affectiva, which was spun out of the MIT Media Lab, and Autism Glass, a Stanford research project, involves using AI to automate the recognition of emotions and to provide social cues to help individuals along the autism spectrum interact in social environments. Health and hunger
This domain addresses health and hunger challenges, including early-stage diagnosis and optimized food distribution. Researchers at the University of Heidelberg and Stanford University have created a disease-detection AI system—using the visual diagnosis of natural images, such as images of skin lesions to determine if they are cancerous—that outperformed professional dermatologists. AI-enabled wearable devices can already detect people with potential early signs of diabetes with 85 percent accuracy by analyzing heart-rate sensor data. These devices, if sufficiently affordable, could help more than 400 million people around the world afflicted by the disease. Information verification and validation
This domain concerns the challenge of facilitating the provision, validation, and recommendation of helpful, valuable, and reliable information to all. It focuses on filtering or counteracting misleading and distorted content, including false and polarizing information disseminated through the relatively new channels of the internet and social media. Such content can have severely negative consequences, including the manipulation of election results or even mob killings, in India and Mexico, triggered by the dissemination of false news via messaging applications. Use cases in this domain include actively presenting opposing views to ideologically isolated pockets in social media.
Infrastructure management
This domain includes infrastructure challenges that could promote the public good in the categories of energy, water and waste management, transportation, real estate, and urban planning. For example, traffic-light networks can be optimized using real-time traffic camera data and Internet of Things (IoT) sensors to maximize vehicle throughput. AI can also be used to schedule predictive maintenance of public transportation systems, such as trains and public infrastructure (including bridges), to identify potentially malfunctioning components. Public and social-sector management
Initiatives related to efficiency and the effective management of public- and social-sector entities, including strong institutions, transparency, and financial management, are included in this domain. For example, AI can be used to identify tax fraud using alternative data such as browsing data, retail data, or payments history. Security and justice
This domain involves challenges in society such as preventing crime and other physical dangers, as well as tracking criminals and mitigating bias in police forces. It focuses on security, policing, and criminal-justice issues as a unique category, rather than as part of public-sector management. An example is using AI and data from IoT devices to create solutions that help firefighters determine safe paths through burning buildings. Our use-case domains cover all 17 of the UN’s Sustainable Development Goals
The United Nations’ Sustainable Development Goals (SDGs) are among the best-known and most frequently cited societal challenges, and our use cases map to all 17 of the goals, supporting some aspect of each one (Exhibit 3). Our use-case library does not rest on the taxonomy of the SDGs, because their goals, unlike ours, are not directly related to AI usage; about 20 cases in our library do not map to the SDGs at all. The chart should not be read as a comprehensive evaluation of AI’s potential for each SDG; if an SDG has a low number of cases, that reflects our library rather than AI’s applicability to that SDG.
AI capabilities that can be used for social good
We identified 18 AI capabilities that could be used to benefit society. Fourteen of them fall into three major categories: computer vision, natural-language processing, and speech and audio processing. The remaining four, which we treated as stand-alone capabilities, include three AI capabilities: reinforcement learning, content generation, and structured deep learning. We also included a category for analytics techniques.
When we subsequently mapped these capabilities to domains (aggregating use cases) in a heat map, we found some clear patterns (Exhibit 4).
Image classification and object detection are powerful computer-vision capabilities
Within computer vision, the specific capabilities of image classification and object detection stand out for their potential applications for social good. These capabilities are often used together—for example, when drones need computer vision to navigate a complex forest environment for search-and-rescue purposes. In this case, image classification may be used to distinguish normal ground cover from footpaths, thereby guiding the drone’s directional navigation, while object detection helps circumvent obstacles such as trees.
Some of these use cases consist of tasks a human being could potentially accomplish on an individual level, but the required number of instances is so large that it exceeds human capacity (for example, finding flooded or unusable roads across a large area after a hurricane). In other cases, an AI system can be more accurate than humans, often by processing more information (for example, the early identification of plant diseases to prevent infection of the entire crop).
Computer-vision capabilities such as the identification of people, face detection, and emotion recognition are relevant only in select domains and use cases, including crisis response, security, equality, and education, but where they are relevant, their impact is great. In these use cases, the common theme is the need to identify individuals, most easily accomplished through the analysis of images. An example of such a use case would be taking advantage of face detection on surveillance footage to detect the presence of intruders in a specific area. (Face detection applications detect the presence of people in an image or video frame and should not be confused with facial recognition, which is used to identify individuals by their features.) Natural-language processing
Some aspects of natural-language processing, including sentiment analysis, language translation, and language understanding, also stand out as applicable to a wide range of domains and use cases. Natural-language processing is most useful in domains where information is commonly stored in unstructured textual form, such as incident reports, health records, newspaper articles, and SMS messages.
As with methods based on computer vision, in some cases a human can probably perform a task with greater accuracy than a trained machine-learning model can. Nonetheless, the speed of “good enough” automated systems can enable meaningful scale efficiencies—for example, providing automated answers to questions that citizens may ask through email. In other cases, especially those that require processing and analyzing vast amounts of information quickly, AI models could outperform humans. An illustrative example could include monitoring the outbreak of disease by analyzing tweets sent in multiple local languages.
Some capabilities, or combination of capabilities, can give the target population opportunities that would not otherwise exist, especially for use cases that involve understanding the natural environment through the interpretation of vision, sound, and speech. An example is the use of AI to help educate children who are on the autism spectrum. Although professional therapists have proved effective in creating behavioral-learning plans for children with autism spectrum disorder (ASD), waitlists for therapy are long. AI tools, primarily using emotion recognition and face detection, can increase access to such educational opportunities by providing cues to help children identify and ultimately learn facial expressions among their family members and friends. Structured deep learning also may have social-benefit applications
A third category of AI capabilities with social-good applications is structured deep learning to analyze traditional tabular data sets. It can help solve problems ranging from tax fraud (using tax-return data) to finding otherwise hard to discover patterns of insights in electronic health records.
Structured deep learning (SDL) has been gaining momentum in the commercial sector in recent years. We expect to see that trend spill over into solutions for social-good use cases, particularly given the abundance of tabular data in the public and social sectors. By automating aspects of basic feature engineering, SDL solutions reduce the need either for domain expertise or an innate understanding of the data and which aspects of the data are important.
Advanced analytics can be a more time- and cost-effective solution than AI for some use cases
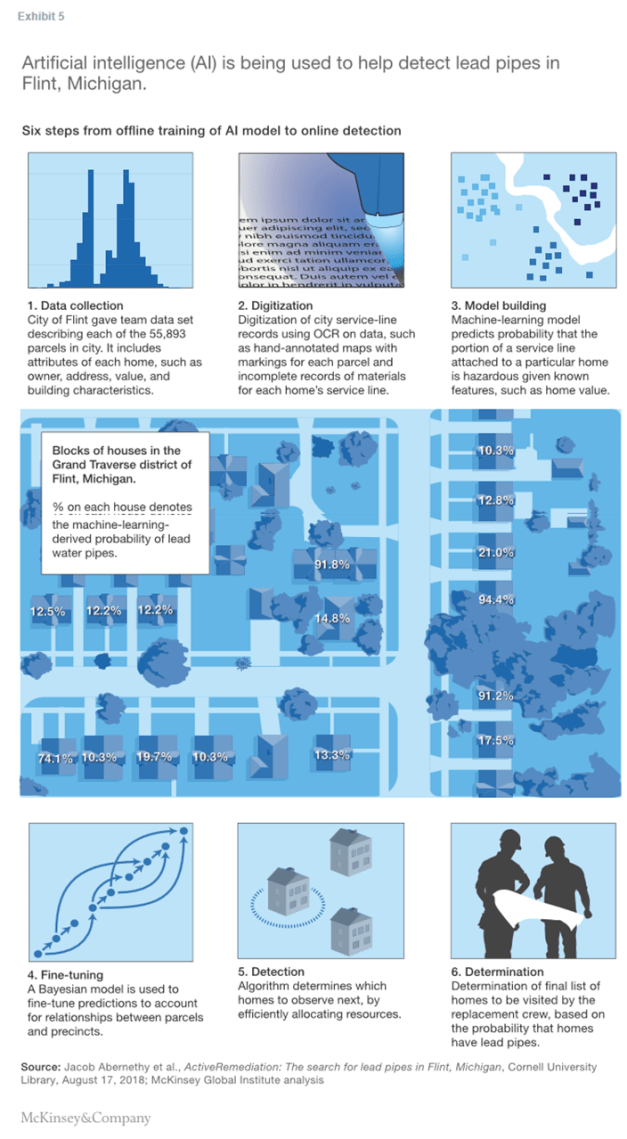
Some of the use cases in our library are better suited to traditional analytics techniques, which are easier to create, than to AI. Moreover, for certain tasks, other analytical techniques can be more suitable than deep learning. For example, in cases where there is a premium on explainability, decision tree-based models can often be more easily understood by humans. In Flint, Michigan, machine learning (sometimes referred to as AI, although for this research we defined AI more narrowly as deep learning) is being used to predict houses that may still have lead water pipes (Exhibit 5).
Overcoming bottlenecks, especially for data and talent
While the social impact of AI is potentially very large, certain bottlenecks must be overcome if even some of that potential is to be realized. In all, we identified 18 potential bottlenecks through interviews with social-domain experts and with AI researchers and practitioners. We grouped these bottlenecks in four categories of importance.
The most significant bottlenecks are data accessibility, a shortage of talent to develop AI solutions, and “last-mile” implementation challenges (Exhibit 6).
Data needed for social-impact uses may not be easily accessible
Data accessibility remains a significant challenge. Resolving it will require a willingness, by both private- and public-sector organizations, to make data available. Much of the data essential or useful for social-good applications are in private hands or in public institutions that might not be willing to share their data. These data owners include telecommunications and satellite companies; social-media platforms; financial institutions (for details such as credit histories); hospitals, doctors, and other health providers (medical information); and governments (including tax information for private individuals). Social entrepreneurs and nongovernmental organizations (NGOs) may have difficulty accessing these data sets because of regulations on data use, privacy concerns, and bureaucratic inertia. The data may also have business value and could be commercially available for purchase. Given the challenges of distinguishing between social use and commercial use, the price may be too high for NGOs and others wanting to deploy the data for societal benefits. The expert AI talent needed to develop and train AI models is in short supply
Just over half of the use cases in our library can leverage solutions created by people with less AI experience. The remaining use cases are more complex as a result of a combination of factors, which vary with the specific case. These need high-level AI expertise—people who may have PhDs or considerable experience with the technologies. Such people are in short supply.
For the first use cases requiring less AI expertise, the needed solution builders are data scientists or software developers with AI experience but not necessarily high-level expertise. Most of these use cases are less complex models that rely on single modes of data input.
The complexity of problems increases significantly when use cases require several AI capabilities to work together cohesively, as well as multiple different data-type inputs. Progress in developing solutions for these cases will thus require high-level talent, for which demand far outstrips supply and competition is fierce. ‘Last-mile’ implementation challenges are also a significant bottleneck for AI deployment for social good
Even when high-level AI expertise is not required, NGOs and other social-sector organizations can face technical problems, over time, deploying and sustaining AI models that require continued access to some level of AI-related skills. The talent required could range from engineers who can maintain or improve the models to data scientists who can extract meaningful output from them. Handoffs fail when providers of solutions implement them and then disappear without ensuring that a sustainable plan is in place.
Organizations may also have difficulty interpreting the results of an AI model. Even if a model achieves a desired level of accuracy on test data, new or unanticipated failure cases often appear in real-life scenarios. An understanding of how the solution works may require a data scientist or “translator.” Without one, the NGO or other implementing organization may trust the model’s results too much: most AI models cannot perform accurately all the time, and many are described as “brittle” (that is, they fail when their inputs stray in specific ways from the data sets on which they were trained).
Risks to be managed
AI tools and techniques can be misused by authorities and others who have access to them, so principles for their use must be established. AI solutions can also unintentionally harm the very people they are supposed to help.
The promise and challenge of artificial intelligence
James Manyika, chairman of the McKinsey Global Institute, shares why AI contains great opportunity and the risk it entails.
An analysis of our use-case library found that four main categories of risk are particularly relevant when AI solutions are leveraged for social good: bias and fairness, privacy, safe use and security, and “explainability” (the ability to identify the feature or data set that leads to a particular decision or prediction).
Bias in AI may perpetuate and aggravate existing prejudices and social inequalities, affecting already-vulnerable populations and amplifying existing cultural prejudices. Bias of this kind may come about through problematic historical data, including unrepresentative or inaccurate sample sizes. For example, AI-based risk scoring for criminal-justice purposes may be trained on historical criminal data that include biases (among other things, African Americans may be unfairly labeled as high risk). As a result, AI risk scores would perpetuate this bias. Some AI applications already show large disparities in accuracy depending on the data used to train algorithms; for example, examination of facial-analysis software shows an error rate of 0.8 percent for light-skinned men; for dark-skinned women, the error rate is 34.7 percent.
One key source of bias can be poor data quality—for example, when data on past employment records are used to identify future candidates. An AI-powered recruiting tool used by one tech company was abandoned recently after several years of trials. It appeared to show systematic bias against women, which resulted from patterns in training data from years of hiring history. To counteract such biases, skilled and diverse data-science teams should take into account potential issues in the training data or sample intelligently from them.
Breaching the privacy of personal information could cause harm
Privacy concerns concerning sensitive personal data are already rife for AI. The ability to assuage these concerns could help speed public acceptance of its widespread use by profit-making and nonprofit organizations alike. The risk is that financial, tax, health, and similar records could become accessible through porous AI systems to people without a legitimate need to access them. That would cause embarrassment and, potentially, harm.
Safe use and security are essential for societal good uses of AI
Ensuring that AI applications are used safely and responsibly is an essential prerequisite for their widespread deployment for societal aims. Seeking to further social good with dangerous technologies would contradict the core mission and could also spark a backlash, given the potentially large number of people involved. For technologies that could affect life and well-being, it will be important to have safety mechanisms in place, including compliance with existing laws and regulations. For example, if AI misdiagnoses patients in hospitals that do not have a safety mechanism in place—particularly if these systems are directly connected to treatment processes—the outcomes could be catastrophic. The framework for accountability and liability for harm done by AI is still evolving.
Decisions made by complex AI models will need to become more readily explainable
Explaining in human terms the results from large, complex AI models remains one of the key challenges to acceptance by users and regulatory authorities. Opening the AI “black box” to show how decisions are made, as well as which factors, features, and data sets are decisive and which are not, will be important for the social use of AI. That will be especially true for stakeholders such as NGOs, which will require a basic level of transparency and will probably want to give clear explanations of the decisions they make. Explainability is especially important for use cases relating to decision making about individuals and, in particular, for cases related to justice and criminal identification, since an accused person must be able to appeal a decision in a meaningful way.
Mitigating risks
Effective mitigation strategies typically involve “human in the loop” interventions: humans are involved in the decision or analysis loop to validate models and double-check results from AI solutions. Such interventions may call for cross-functional teams, including domain experts, engineers, product managers, user-experience researchers, legal professionals, and others, to flag and assess possible unintended consequences.
Human analysis of the data used to train models may be able to identify issues such as bias and lack of representation. Fairness and security “red teams” could carry out solution tests, and in some cases third parties could be brought in to test solutions by using an adversarial approach. To mitigate this kind of bias, university researchers have demonstrated methods such as sampling the data with an understanding of their inherent bias and creating synthetic data sets based on known statistics.
Guardrails to prevent users from blindly trusting AI can be put in place. In medicine, for example, misdiagnoses can be devastating to patients. The problems include false-positive results that cause distress; wrong or unnecessary treatments or surgeries; or, even worse, false negatives, so that patients do not get the correct diagnosis until a disease has reached the terminal stage.
Technology may find some solutions to these challenges, including explainability. For example, nascent approaches to the transparency of models include local-interpretable-model-agnostic (LIME) explanations, which attempt to identify those parts of input data a trained model relies on most to make predictions.
Scaling up the use of AI for social good
As with any technology deployment for social good, the scaling up and successful application of AI will depend on the willingness of a large group of stakeholders—including collectors and generators of data, as well as governments and NGOs—to engage. These are still the early days of AI’s deployment for social good, and considerable progress will be needed before the vast potential becomes a reality. Public- and private-sector players all have a role to play.
Improving data accessibility for social-impact cases
A wide range of stakeholders owns, controls, collects, or generates the data that could be deployed for AI solutions. Governments are among the most significant collectors of information, which can include tax, health, and education data. Massive volumes of data are also collected by private companies—including satellite operators, telecommunications firms, utilities, and technology companies that run digital platforms, as well as social-media sites and search operations. These data sets may contain highly confidential personal information that cannot be shared without being anonymized. But private operators may also commercialize their data sets, which may therefore be unavailable for pro-bono social-good cases.
Overcoming this accessibility challenge will probably require a global call to action to record data and make it more readily available for well-defined societal initiatives.
Data collectors and generators will need to be encouraged—and possibly mandated—to open access to subsets of their data when that could be in the clear public interest. This is already starting to happen in some areas. For example, many satellite data companies participate in the International Charter on Space and Major Disasters, which commits them to open access to satellite data during emergencies, such as the September 2018 tsunami in Indonesia and Hurricane Michael, which hit the US East Coast in October 2018.
Notes from the AI frontier: Applying AI for social good
Close collaboration between NGOs and data collectors and generators could also help facilitate this push to make data more accessible. Funding will be required from governments and foundations for initiatives to record and store data that could be used for social ends.
Even if the data are accessible, using them presents challenges. Continued investment will be needed to support high-quality data labeling. And multiple stakeholders will have to commit themselves to store data so that they can be accessed in a coordinated way and to use the same data-recording standards where possible to ensure seamless interoperability.
Issues of data quality and of potential bias and fairness will also have to be addressed if the data are to be deployed usefully. Transparency will be a key for bias and fairness. A deep understanding of the data, their provenance, and their characteristics must be captured, so that others using the data set understand the potential flaws.
All this is likely to require collaboration among companies, governments, and NGOs to set up regular data forums, in each industry, to work on the availability and accessibility of data and on connectivity issues. Ideally, these stakeholders would set global industry standards and collaborate closely on use cases to ensure that implementation becomes feasible.
Overcoming AI talent shortages is essential for implementing AI-based solutions for social impact
The long-term solution to the talent challenges we have identified will be to recruit more students to major in computer science and specialize in AI. That could be spurred by significant increases in funding—both grants and scholarships—for tertiary education and for PhDs in AI-related fields. Given the high salaries AI expertise commands today, the market may react with a surge in demand for such an education, although the advanced math skills needed could discourage many people.
Sustaining or even increasing current educational opportunities would be helpful. These opportunities include “AI residencies”—one-year training programs at corporate research labs—and shorter-term AI “boot camps” and academies for midcareer professionals. An advanced degree typically is not required for these programs, which can train participants in the practice of AI research without requiring them to spend years in a PhD program.
Given the shortage of experienced AI professionals in the social sector, companies with AI talent could play a major role in focusing more effort on AI solutions that have a social impact. For example, they could encourage employees to volunteer and support or coach noncommercial organizations that want to adopt, deploy, and sustain high-impact AI solutions. Companies and universities with AI talent could also allocate some of their research capacity to new social-benefit AI capabilities or solutions that cannot otherwise attract people with the requisite skills.
Overcoming the shortage of talent that can manage AI implementations will probably require governments and educational providers to work with companies and social-sector organizations to develop more free or low-cost online training courses. Foundations could provide funding for such initiatives.
Task forces of tech and business translators from governments, corporations, and social organizations, as well as freelancers, could be established to help teach NGOs about AI through relatable case studies. Beyond coaching, these task forces could help NGOs scope potential projects, support deployment, and plan sustainable road maps.
From the modest library of use cases that we have begun to compile, we can already see tremendous potential for using AI to address the world’s most important challenges. While that potential is impressive, turning it into reality on the scale it deserves will require focus, collaboration, goodwill, funding, and a determination among many stakeholders to work for the benefit of society. We are only just setting out on this journey. Reaching the destination will be a step-by-step process of confronting barriers and obstacles. We can see the moon, but getting there will require more work and a solid conviction that the goal is worth all the effort—for the sake of everyone.
About the author(s)
Michael Chui is a partner and James Manyika is chairman and a director of the McKinsey Global Institute. Martin Harrysson and Roger Roberts are partners in McKinsey’s Silicon Valley office, where Rita Chung is a consultant. Pieter Nel is a specialist in the New York office; Ashley van Heteren is an expert associate principal in the Amsterdam office.






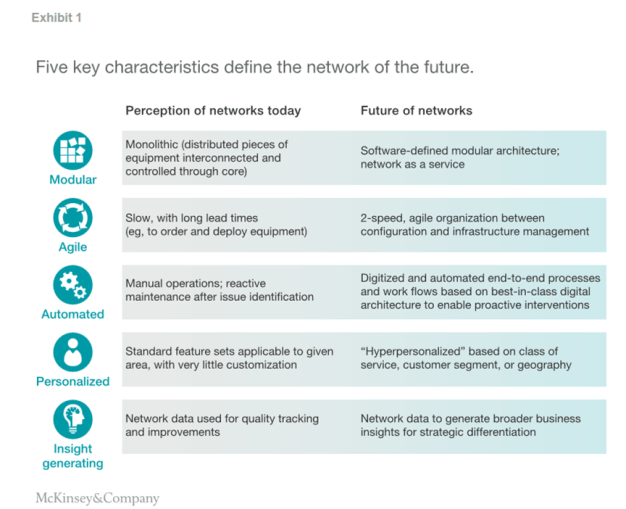



 The building blocks telcos need to create their digital-and-analytics DNA
The building blocks telcos need to create their digital-and-analytics DNA
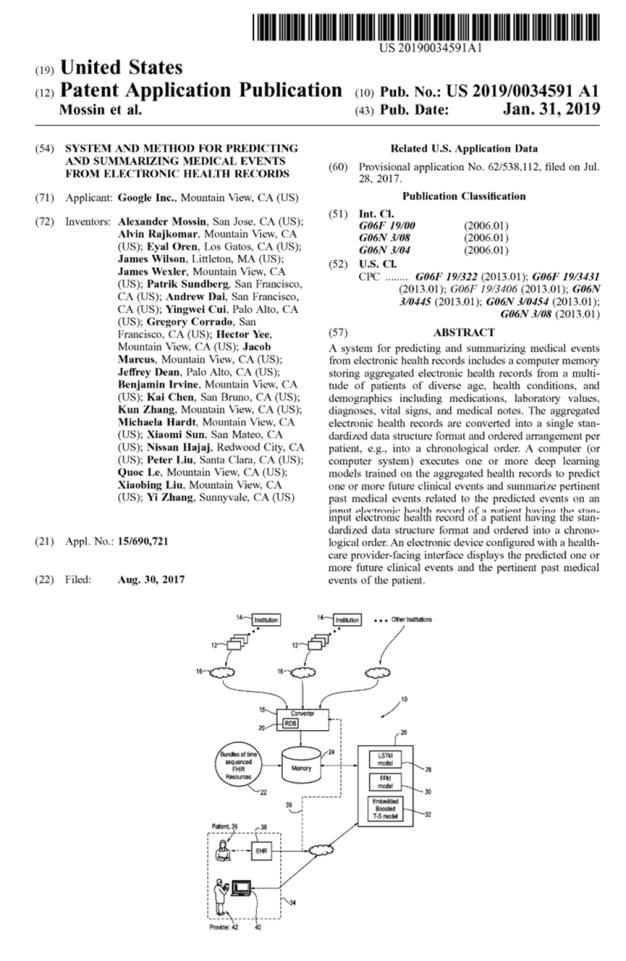






 AI capabilities that can be used for social good
AI capabilities that can be used for social good