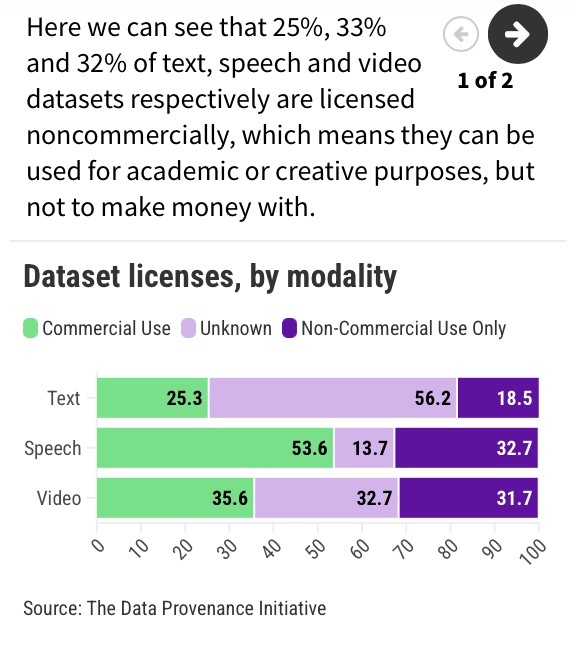
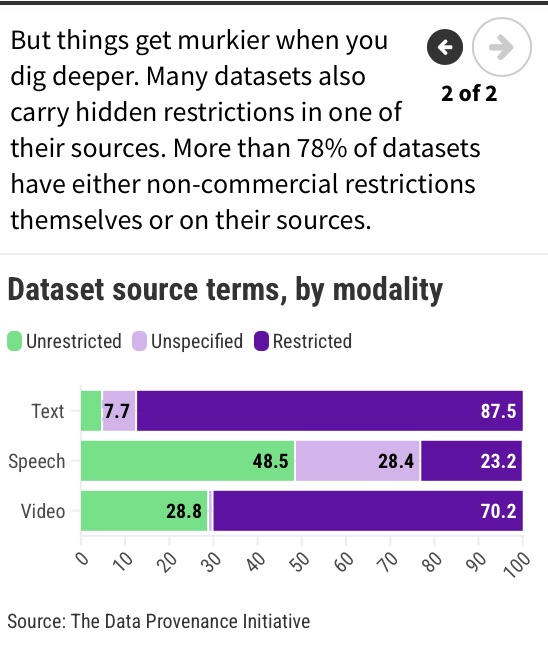
The Federal Electronic Health Record Modernization (FEHRM) office, along with Department of Defense (DOD), Department of Veterans Affairs (VA), Department of Homeland Security’s U.S. Coast Guard (USCG), Department of Commerce’s National Oceanic and Atmospheric Administration (NOAA), and other partners, hit many milestones in 2024 on our journey to implement a single, common Federal Electronic Health Record (EHR) to enhance patient care and provider effectiveness. Below are just a few of our successes from the past year:
Deployed the Federal EHR at the Captain James A. Lovell Federal Health Care Center (Lovell FHCC): In March 2024, the FEHRM, DOD, and VA worked together to complete the award-winning Federal EHR deployment at Lovell FHCC. This historic deployment reflected cross-agency accomplishments that can be leveraged by other health care organizations looking to integrate and streamline care, transforming health care on an even broader scale. We converged and standardized different processes, workflows, and more to enable the Departments to deploy the same EHR together. Together, we integrated efforts, overcame joint challenges, and delivered solutions to complex problems—including bridging communications differences and gaps and creating 60+ joint communications materials for the deployment, some of which are available on the FEHRM website. • Shared New Lessons Learned to Enhance Deployments: We collected and shared nearly 182 successes and lessons learned, most of which related to the Federal EHR deployment at Lovell FHCC. Check out our Lovell FHCC Successes and Lessons Learned Executive Summary to learn more about successes and lessons learned regarding partner coordination, resources, communication, training and peer support, and user role provisioning. These will be leveraged for remaining joint sharing sites and beyond. • Hosted a Record-Breaking Federal EHR Annual Summit to Engage with End Users: We hosted a record-breaking fourth Federal EHR Annual Summit in October, where more than 1,700 Federal EHR clinical staff and other participants shared invaluable feedback on their end-user experiences in more than 35 interactive sessions. They provided insight into change management, best practices for using the Federal EHR, and a deeper understanding of decision-making processes that shape end-user workflows─enhancing the Federal EHR to help providers achieve better health care experiences and outcomes. We look forward to hosting a modified version of this event at the Military Health System Conference in April 2025 as a Federal EHR track. • Released Federal EHR Updates to Continuously Improve the System: We continued delivering Federal EHR updates in response to end-user feedback. We enhanced existing capabilities, introduced new interfaces, and remained current on software code. Read our Capability Block 11 informational placemat for more details on the latest improvements. • Expanded Immunization Data Exchange to Benefit Providers and Patients: We expanded the number of Federal EHR sites that can exchange immunization data through the Centers for Disease Control and Prevention’s Immunization Gateway to DOD sites in the District of Columbia, Maryland, Texas, and Virginia. They join the initial DOD sites in California, Florida, North Carolina, Oklahoma, and Washington, and VA sites using the Federal EHR that are also live with this capability in Idaho, Illinois, Montana, Ohio, Oregon, Washington, and Wisconsin. Read more details on LinkedIn and in the FEHRM Activities section of the FEHRM Frontline newsletter’s fall issue. • Increased Federal Registries to Drive Data Availability and Usability. We enabled 27 federal registries with 299 measures in 2024. These registries help drive availability and usability of data to improve patient outcomes through integrated workflow recommendations called Health Maintenance Reminders. • Added New Toxic Exposure Clinical Terms to Enhance Exposure-Related Care: The FEHRM identified significant gaps in data availability related to the health consequences of military service-related toxic exposures and the lack of standardized coding for these exposures. The office added 27 new related terms to the National Library of Medicine’s Systematized Nomenclature for Medicine Clinical Terms—a comprehensive standardized clinical library used worldwide and the primary coding repository for clinical terms related to toxic exposures—for clinicians to use worldwide, enhancing exposure-related care and research. Read more about this effort on the FEHRM LinkedIn page. • Drove Federal EHR Configuration Changes: The FEHRM continued to drive joint decision making through the Joint Sustainment and Adoption Board (JSaAB), adjudicating 1,249 Federal EHR changes that impacted multiple sites and the enterprise configuration and improved the user experience. Learn more about how the JSaAB ensures Federal EHR changes benefit all.
As these accomplishments show, we are better when we all work together to provide the best health care experience for our providers and patients. We continue to collaborate in the new year to transform the landscape and continue to deliver top-quality health care to all Americans.
Agents are the hottest thing in tech right now. Top firms from Google DeepMind to OpenAI to Anthropic are racing to augment large language models with the ability to carry out tasks by themselves. Known as agentic AI in industry jargon, such systems have fast become the new target of Silicon Valley buzz. Everyone from Nvidiato Salesforce is talking about how they are going to upend the industry.
“We believe that, in 2025, we may see the first AI agents ‘join the workforce’ and materially change the output of companies,” Sam Altman claimed in a blog post last week.
In the broadest sense, an agent is a software system that goes off and does something, often with minimal to zero supervision. The more complex that thing is, the smarter the agent needs to be. For many, large language models are now smart enough to power agents that can do a whole range of useful tasks for us, such as filling out forms, looking up a recipe and adding the ingredients to an online grocery basket, or using a search engine to do last-minute research before a meeting and producing a quick bullet-point summary.
In October, Anthropic showed off one of the most advanced agents yet: an extension of its Claude large language model called computer use. As the name suggests, it lets you direct Claude to use a computer much as a person would, by moving a cursor, clicking buttons, and typing text. Instead of simply having a conversation with Claude, you can now ask it to carry out on-screen tasks for you.
Anthropic notes that the feature is still cumbersome and error-prone. But it is already available to a handful of testers, including third-party developers at companies such as DoorDash, Canva, and Asana.
Computer use is a glimpse of what’s to come for agents. To learn what’s coming next, MIT Technology Review talked to Anthropic’s cofounder and chief scientist Jared Kaplan. Here are four ways that agents are going to get even better in 2025.
(Kaplan’s answers have been lightly edited for length and clarity.)
1/ Agents will get better at using tools
“I think there are two axes for thinking about what AI is capable of. One is a question of how complex the task is that a system can do. And as AI systems get smarter, they’re getting better in that direction. But another direction that’s very relevant is what kinds of environments or tools the AI can use.
“So, like, if you go back almost 10 years now to [DeepMind’s Go-playing model] AlphaGo, we had AI systems that were superhuman in terms of how well they could play board games. But if all you can work with is a board game, then that’s a very restrictive environment. It’s not actually useful, even if it’s very smart. With text models, and then multimodal models, and now computer use—and perhaps in the future with robotics—you’re moving toward bringing AI into different situations and tasks, and making it useful.
“We were excited about computer use basically for that reason. Until recently, with large language models, it’s been necessary to give them a very specific prompt, give them very specific tools, and then they’re restricted to a specific kind of environment. What I see is that computer use will probably improve quickly in terms of how well models can do different tasks and more complex tasks. And also to realize when they’ve made mistakes, or realize when there’s a high-stakes question and it needs to ask the user for feedback.”
2/ Agents will understand context
“Claude needs to learn enough about your particular situation and the constraints that you operate under to be useful. Things like what particular role you’re in, what styles of writing or what needs you and your organization have.
ANTHROPIC
“I think that we’ll see improvements there where Claude will be able to search through things like your documents, your Slack, etc., and really learn what’s useful for you. That’s underemphasized a bit with agents. It’s necessary for systems to be not only useful but also safe, doing what you expected.
“Another thing is that a lot of tasks won’t require Claude to do much reasoning. You don’t need to sit and think for hours before opening Google Docs or something. And so I think that a lot of what we’ll see is not just more reasoning but the application of reasoning when it’s really useful and important, but also not wasting time when it’s not necessary.”
3/ Agents will make coding assistants better
“We wanted to get a very initial beta of computer use out to developers to get feedback while the system was relatively primitive. But as these systems get better, they might be more widely used and really collaborate with you on different activities.
“I think DoorDash, the Browser Company, and Canva are all experimenting with, like, different kinds of browser interactions and designing them with the help of AI.
“My expectation is that we’ll also see further improvements to coding assistants. That’s something that’s been very exciting for developers. There’s just a ton of interest in using Claude 3.5 for coding, where it’s not just autocomplete like it was a couple of years ago. It’s really understanding what’s wrong with code, debugging it—running the code, seeing what happens, and fixing it.”
4/ Agents will need to be made safe
“We founded Anthropic because we expected AI to progress very quickly and [thought] that, inevitably, safety concerns were going to be relevant. And I think that’s just going to become more and more visceral this year, because I think these agents are going to become more and more integrated into the work we do. We need to be ready for the challenges, like prompt injection.
[Prompt injection is an attack in which a malicious prompt is passed to a large language model in ways that its developers did not foresee or intend. One way to do this is to add the prompt to websites that models might visit.]
“Prompt injection is probably one of the No.1 things we’re thinking about in terms of, like, broader usage of agents. I think it’s especially important for computer use, and it’s something we’re working on very actively, because if computer use is deployed at large scale, then there could be, like, pernicious websites or something that try to convince Claude to do something that it shouldn’t do.
“And with more advanced models, there’s just more risk. We have a robust scaling policy where, as AI systems become sufficiently capable, we feel like we need to be able to really prevent them from being misused. For example, if they could help terrorists—that kind of thing.
“So I’m really excited about how AI will be useful—it’s actually also accelerating us a lot internally at Anthropic, with people using Claude in all kinds of ways, especially with coding. But, yeah, there’ll be a lot of challenges as well. It’ll be an interesting year.”
In a speech to the General Assembly last week, UN Secretary-General António Guterres stressed that as Artificial Intelligence reshapes our world, every nation must help ensure technology has protective guardrails in place and that advances are used for the good of all.
“Together, let’s ensure Artificial Intelligence serves its highest purpose: advancing human progress, equality and dignity.”
The Federal electronic health record (EHR) is shared by VA, the Department of Defense (DOD), the Department of Homeland Security’s U.S. Coast Guard (USCG), and the Department of Commerce’s National Oceanic and Atmospheric Administration (NOAA). To meet the needs of the different sizes and “shapes” of health care organizations and keep pace with advances in medical care, the Federal EHR was developed to be highly configurable. However, sharing a single, common medical record means the system must be governed in a joint manner. When configuration changes are requested that will affect all users across all sites, the Joint Sustainment and Adoption Board (JSaAB) is the final governance body that ensures the change will benefit end users and avoid any negative impact to the partner organizations.
The JSaAB operates within the Federal Electronic Health Record Modernization (FEHRM) office. The FEHRM’s charter states that its primary mission is to implement a common Federal EHR to enhance patient care and provider effectiveness wherever care is provided. This positions the FEHRM as the functional leader and collaborator of choice for all Federal EHR partners in the drive toward an optimized user experience and enterprise convergence. The FEHRM facilitates joint concurrence and ensures the baseline of the Federal EHR is as stable as possible—the JSaAB is just one of many vital governance forums within the FEHRM that helps VA, DOD, and other federal partners make decisions pertaining to functional content and configuration of the system.
The JSaAB makes sure change requests are evaluated to determine their impact on the health care operations of each Federal EHR partner organization. Changes can be requested by end users and leadership at VA or DOD facilities or by DOD and Veterans Health Administration clinical and business communities.
The JSaAB is co-chaired by one programmatic and one functional representative from DOD and VA (four co-chairs in total, with USCG and NOAA represented by the DOD co-chairs). The group meets every Wednesday and approves approximately 30 to 40 changes in each meeting. When a new facility goes live with the Federal EHR, the JSaAB convenes daily during deployment to review any changes that may be unique to that site. The JSaAB also has processes in place for emergency review and approval of changes when a potential patient safety risk is identified.
Change requests are received from various areas within VA and DOD, both at facilities currently using the Federal EHR and from informatics staff within each organization’s centralized program management offices. The FEHRM’s JSaAB governance is set up such that, regardless of how an individual department processes a change request, they filter up to a solution team within the Defense Health Agency Health Informatics group or the VA Electronic Health Record Modernization Integration Office. Once the solution team determines that a change is needed, there is a robust, department-agnostic process to review, test, approve, communicate, and release the change at the enterprise level.
Once a request enters the JSaAB process, it first goes to one or more clinical and functional specialists within VA and DOD for review and concurrence. Federal working groups (FWGs) are chartered under the JSaAB and provide advisory, process, and operational support to drive convergence of EHR configuration across the federal partners and maintain the Federal EHR baseline. There are currently 15 FWGs that provide VA/DOD subject matter expert consultation on change requests.
FWGs offer several advantages, especially in the context of managing and configuring the Federal EHR:
Expertise and specialization: FWGs bring together subject matter experts from various fields within VA and DOD. This ensures that decisions are informed by the latest knowledge and best practices in health care and technology.
Collaboration and coordination: These groups facilitate collaboration between different federal agencies, ensuring that changes to the Federal EHR are coordinated well and meet the needs of all stakeholders. This helps in maintaining a unified approach and avoiding duplication of efforts.
Efficiency in decision making: By having dedicated groups focused on specific areas, FWGs can streamline the decision-making process. This allows for quicker responses to change requests and more efficient implementation of updates.
Consistency and standardization: FWGs help maintain a consistent and standardized approach to Federal EHR configuration across all federal partners. This is crucial for ensuring that the system works seamlessly across different sites and for different users.
Enhanced problem solving: With diverse expertise and perspectives, FWGs are better equipped to identify and solve complex problems. This collaborative approach can lead to more innovative and effective solutions.
Support for change management: FWGs provide advisory, process, and operational support, which is essential for managing the lifecycle of change requests. This support helps in ensuring that changes are implemented smoothly and effectively.
Focus on user needs: By involving end users in the process, FWGs ensure that Federal EHR configurations meet the actual needs of health care providers. This user-centric approach enhances the usability and effectiveness of the system.
In addition to FWGs, most change requests are also evaluated by various clinical councils and/or clinical communities within VA and DOD to obtain guidance and direction from subject matter experts within any potentially affected clinical specialty
When a change is ready for the JSaAB, the FEHRM conducts a quality control analysis to ensure that process requirements are met and all documentation is present. Before the weekly JSaAB meeting, the co-chairs review each proposed change and evaluate the functional or programmatic impact from both the VA and DOD perspective. Change approval notifications are then sent to the implementer, and VA and DOD each hold a User Impact Series meeting the following day to ensure end users are prepared for the upcoming change. Changes are typically implemented the following Tuesday after JSaAB approval, with limited exceptions for expedited releases or situations where additional time is needed for review by the Federal Change Control Board or the distribution of related communications.
For the last couple of years we’ve tried to predict what’s coming next in AI. It’s a bit of a fool’s game given how fast this industry moves… But we’re on a roll, so we’re doing it again. In this edition of What’s Next in Tech, discover what’s next for AI in 2025.
What’s coming next in the fast-paced world of AI? Join MIT Technology Review’s editors on January 16 for 5 AI Predictions for 2025, a special LinkedIn Live event exploring transformative trends and insights shaping the next twelve months of AI and business. Register for free today.
So what’s coming in 2025? We’re going to ignore the obvious here: You can bet that agents and smaller, more efficient, language models will continue to shape the industry. Instead, here are some alternative picks from our AI team
1. Generative virtual playgrounds: If 2023 was the year of generative images and 2024 was the year of generative video—what comes next? If you guessed generative virtual worlds (a.k.a. video games), high fives all round. We got a tiny glimpse of this technology in February, when Google DeepMind revealed a generative model called Genie that could take a still image and turn it into a side-scrolling 2D platform game that players could interact with. In December, the firm revealed Genie 2, a model that can spin a starter image into an entire virtual world. Other companies are building similar tech.
2. Large language models that “reason”: The buzz was justified. When OpenAI revealed o1 in September, it introduced a new paradigm in how large language models work. Two months later, the firm pushed that paradigm forward in almost every way with o3—a model that just might reshape this technology for good. Most models, including OpenAI’s flagship GPT-4, spit out the first response they come up with. Sometimes it’s correct; sometimes it’s not. But the firm’s new models are trained to work through their answers step by step, breaking down tricky problems into a series of simpler ones. When one approach isn’t working, they try another. This technique, known as “reasoning” (yes—we know exactly how loaded that term is), can make this technology more accurate, especially for math, physics, and logic problems. It’s also crucial for agents.
3. It’s boom time for AI in science: One of the most exciting uses for AI is speeding up discovery in the natural sciences. Perhaps the greatest vindication of AI’s potential on this front came last October, when the Royal Swedish Academy of Sciences awarded the Nobel Prize for chemistry to Demis Hassabis and John M. Jumper from Google DeepMind for building the AlphaFold tool, which can solve protein folding, and to David Baker for building tools to help design new proteins. Expect this trend to continue next year, and to see more data sets and models that are aimed specifically at scientific discovery. Proteins were the perfect target for AI, because the field had excellent existing data sets that AI models could be trained on. The hunt is on to find the next big thing.
Read the full story for more on these three predictions, as well as two additional things our team anticipates will happen this year in the world of AI.
MIT Technology Review’s What’s Next series looks across industries, trends, and technologies to give you a first look at the future. You can read the rest of them here.
For the last couple of years we’ve had a go at predicting what’s coming next in AI. A fool’s game given how fast this industry moves. But we’re ona roll, and we’re doing it again.
How did we score last time round? Our four hot trends to watch out for in 2024 included what we called customized chatbots—interactive helper apps powered by multimodal large language models (check: we didn’t know it yet, but we were talking about what everyone now calls agents, the hottest thing in AI right now); generative video (check: few technologies have improved so fast in the last 12 months, with OpenAI and Google DeepMind releasing their flagship video generation models, Soraand Veo, within a week of each other this December); and more general-purpose robots that can do a wider range of tasks (check: the payoffs from large language models continue to trickle down to other parts of the tech industry, and robotics is top of the list).
We also said that AI-generated election disinformation would be everywhere, but here—happily—we got it wrong. There were many things to wring our hands over this year, but political deepfakes were thin on the ground.
So what’s coming in 2025? We’re going to ignore the obvious here: You can bet that agents and smaller, more efficient, language models will continue to shape the industry. Instead, here are five alternative picks from our AI team.
1. Generative virtual playgrounds
If 2023 was the year of generative images and 2024 was the year of generative video—what comes next? If you guessed generative virtual worlds (a.k.a. video games), high fives all round.
We got a tiny glimpse of this technology in February, when Google DeepMind revealed a generative model called Genie that could take a still image and turn it into a side-scrolling 2D platform game that players could interact with. In December, the firm revealed Genie 2, a model that can spin a starter image into an entire virtual world.
Other companies are building similar tech. In October, the AI startups Decart and Etched revealed an unofficial Minecraft hack in which every frame of the game gets generated on the fly as you play. And World Labs, a startup cofounded by Fei-Fei Li—creator of ImageNet, the vast data set of photos that kick-started the deep-learning boom—is building what it calls large world models, or LWMs.
One obvious application is video games. There’s a playful tone to these early experiments, and generative 3D simulations could be used to explore design concepts for new games, turning a sketch into a playable environment on the fly. This could lead to entirely new types of games.
But they could also be used to train robots. World Labs wants to develop so-called spatial intelligence—the ability for machines to interpret and interact with the everyday world. But robotics researchers lack good data about real-world scenarios with which to train such technology. Spinning up countless virtual worlds and dropping virtual robots into them to learn by trial and error could help make up for that.
2. Large language models that “reason”
The buzz was justified. When OpenAI revealed o1 in September, it introduced a new paradigm in how large language models work. Two months later, the firm pushed that paradigm forward in almost every way with o3—a model that just might reshape this technology for good.
Most models, including OpenAI’s flagship GPT-4, spit out the first response they come up with. Sometimes it’s correct; sometimes it’s not. But the firm’s new models are trained to work through their answers step by step, breaking down tricky problems into a series of simpler ones. When one approach isn’t working, they try another. This technique, known as “reasoning” (yes—we know exactly how loaded that term is), can make this technology more accurate, especially for math, physics, and logic problems.
The next big thing is AI tools that can do more complex tasks. Here’s how they will work.
It’s also crucial for agents.
In December, Google DeepMind revealed an experimental new web-browsing agent called Mariner. In the middle of a preview demo that the company gave to MIT Technology Review, Mariner seemed to get stuck. Megha Goel, a product manager at the company, had asked the agent to find her a recipe for Christmas cookies that looked like the ones in a photo she’d given it. Mariner found a recipe on the web and started adding the ingredients to Goel’s online grocery basket.
Then it stalled; it couldn’t figure out what type of flour to pick. Goel watched as Mariner explained its steps in a chat window: “It says, ‘I will use the browser’s Back button to return to the recipe.’”
It was a remarkable moment. Instead of hitting a wall, the agent had broken the task down into separate actions and picked one that might resolve the problem. Figuring out you need to click the Back button may sound basic, but for a mindless bot it’s akin to rocket science. And it worked: Mariner went back to the recipe, confirmed the type of flour, and carried on filling Goel’s basket.
Google DeepMind is also building an experimental version of Gemini 2.0, its latest large language model, that uses this step-by-step approach to problem solving, called Gemini 2.0 Flash Thinking.
But OpenAI and Google are just the tip of the iceberg. Many companies are building large language models that use similar techniques, making them better at a whole range of tasks, from cooking to coding. Expect a lot more buzz about reasoning (we know, we know) this year.
—Will Douglas Heaven
3. It’s boom time for AI in science
One of the most exciting uses for AI is speeding up discovery in the natural sciences. Perhaps the greatest vindication of AI’s potential on this front came last October, when the Royal Swedish Academy of Sciences awarded the Nobel Prize for chemistryto Demis Hassabis and John M. Jumper from Google DeepMind for building the AlphaFold tool, which can solve protein folding, and to David Baker for building tools to help design new proteins.
Expect this trend to continue next year, and to see more data sets and models that are aimed specifically at scientific discovery. Proteins were the perfect target for AI, because the field had excellent existing data sets that AI models could be trained on.
The hunt is on to find the next big thing. One potential area is materials science. Meta has released massive data sets and models that could help scientists use AI to discover new materials much faster, and in December, Hugging Face, together with the startup Entalpic, launched LeMaterial, an open-source project that aims to simplify and accelerate materials research. Their first project is a data set that unifies, cleans, and standardizes the most prominent material data sets.
AI model makers are also keen to pitch their generative products as research tools for scientists. OpenAI let scientists test its latest o1 model and see how it might support them in research. The results were encouraging.
Having an AI tool that can operate in a similar way to a scientist is one of the fantasies of the tech sector. In a manifesto published in October last year, Anthropic founder Dario Amodei highlighted science, especially biology, as one of the key areas where powerful AI could help. Amodei speculates that in the future, AI could be not only a method of data analysis but a “virtual biologist who performs all the tasks biologists do.” We’re still a long way away from this scenario. But next year, we might see important steps toward it.
—Melissa Heikkilä
4. AI companies get cozier with national security
There is a lot of money to be made by AI companies willing to lend their tools to border surveillance, intelligence gathering, and other national security tasks.
The US military has launched a number of initiatives that show it’s eager to adopt AI, from the Replicator program—which, inspired by the war in Ukraine, promises to spend $1 billion on small drones—to the Artificial Intelligence Rapid Capabilities Cell, a unit bringing AI into everything from battlefield decision-making to logistics. European militaries are under pressure to up their tech investment, triggered by concerns that Donald Trump’s administration will cut spending to Ukraine. Rising tensions between Taiwan and China weigh heavily on the minds of military planners, too.
The US still has no federal privacy law. But recent enforcement actions against data brokers may offer some new protections for Americans’ personal information.
In 2025, these trends will continue to be a boon for defense-tech companies like Palantir, Anduril, and others, which are now capitalizing on classified military datato train AI models.
The defense industry’s deep pockets will tempt mainstream AI companies into the fold too. OpenAI in December announced it is partnering with Anduril on a program to take down drones, completing a year-long pivotaway from its policy of not working with the military. It joins the ranks of Microsoft, Amazon, and Google, which have worked with the Pentagon for years.
Other AI competitors, which are spending billions to train and develop new models, will face more pressure in 2025 to think seriously about revenue. It’s possible that they’ll find enough non-defense customers who will pay handsomely for AI agents that can handle complex tasks, or creative industries willing to spend on image and video generators.
But they’ll also be increasingly tempted to throw their hats in the ring for lucrative Pentagon contracts. Expect to see companies wrestle with whether working on defense projects will be seen as a contradiction to their values. OpenAI’s rationale for changing its stance was that “democracies should continue to take the lead in AI development,” the company wrote, reasoning that lending its models to the military would advance that goal. In 2025, we’ll be watching others follow its lead.
—James O’Donnell
5. Nvidia sees legitimate competition
For much of the current AI boom, if you were a tech startup looking to try your hand at making an AI model, Jensen Huang was your man. As CEO of Nvidia, the world’s most valuable corporation, Huang helped the company become the undisputed leader of chips used both to train AI models and to ping a model when anyone uses it, called “inferencing.”
A number of forces could change that in 2025. For one, behemoth competitors like Amazon, Broadcom, AMD, and others have been investing heavily in new chips, and there are early indications that these could compete closely with Nvidia’s—particularly for inference, where Nvidia’s lead is less solid.
A growing number of startups are also attacking Nvidia from a different angle. Rather than trying to marginally improve on Nvidia’s designs, startups like Groq are making riskier bets on entirely new chip architectures that, with enough time, promise to provide more efficient or effective training. In 2025 these experiments will still be in their early stages, but it’s possible that a standout competitor will change the assumption that top AI models rely exclusively on Nvidia chips.
Underpinning this competition, the geopolitical chip war will continue. That war thus far has relied on two strategies. On one hand, the West seeks to limit exports to China of top chips and the technologies to make them. On the other, efforts like the US CHIPS Act aim to boost domestic production of semiconductors.
Donald Trump may escalate those export controls and has promised massive tariffs on any goods imported from China. In 2025, such tariffs would put Taiwan—on which the US relies heavily because of the chip manufacturer TSMC—at the center of the trade wars. That’s because Taiwan has said it will help Chinese firms relocate to the island to help them avoid the proposed tariffs. That could draw further criticism from Trump, who has expressed frustration with US spending to defend Taiwan from China.
It’s unclear how these forces will play out, but it will only further incentivize chipmakers to reduce reliance on Taiwan, which is the entire purpose of the CHIPS Act. As spending from the bill begins to circulate, next year could bring the first evidence of whether it’s materially boosting domestic chip production.
The profit incentive in U.S. health care, high costs for the insured and uninsured alike, and wide disparities remain challenges for the U.S
Moving forward, the Commonwealth Fund is committed to envisioning and building an equitable health system that works for everyone.
The celebration of a new year marks an opportunity to reflect on the past and look forward to the future. At the Commonwealth Fund, we take stock of what we observed, what we learned, and how we impacted health policy, practice, and leadership development. In 2024, as always, we worked to fulfill our mission of promoting a high-performing, equitable health care system for everyone.
It is clear that 2024 provided much to reflect on, and three themes really rose to the surface. A common thread among these themes is the need for courage — courage to implement commonsense and well-known solutions to pressing and longstanding problems; courage to challenge the deeply entrenched interests that preference the status quo to change; and courage to hold ourselves accountable to produce better health outcomes.
First, health care in this country is increasingly prioritizing revenue and profits over patients —and people are angry. Most notably, the UnitedHealthcare tragedy led to a tirade of public outrage and frustration about the business-as-usual practices of health insurers that can result in delayed or denied care, with financial and, sometimes, life-and-death consequences.
But we saw the profit motive play out in other ways: there was the collapse of Steward Health Care, the nation’s largest for-profit hospital system. This event — a quintessential case study of private equity’s extraction of financial value at the expense of quality, safety, and patient care — destabilized the care of patients in multiple states and drew the ire of state leaders, and even a bipartisan coalition of congressional leaders.
Furthermore, evidence continues to mount that consolidation of large health systems doesn’t yield improvements in quality, safety, or control of costs. At the same time, health care providers, in unprecedented fashion, are organizing and unionizing as a counterweight to what they feel has been a move to prioritize the business of health care over the importance of patient care. Given the power of these forces, it will take courage, from many stakeholders, to turn this tide.
Second, people — even many people who have health insurance — can’t get the care they need because of costs or because they simply do not have access to the providers they need in their communities. Despite more people having health care coverage than ever before, our research found that nearly a quarter of working-age adults had insurance but were underinsured — that is, enrolled in health plans with high out-of-pocket costs that make it difficult to afford care. We see people skipping needed care, avoiding specialist visits, not filling their prescribed medications, and making heartbreaking choices between needed treatments and necessities like food or rent. At the end of this chain reaction are poorer health outcomes that are completely preventable.
Strengthening the Affordable Care Act will be critical going forward, and a real reckoning and repair of employer-sponsored insurance — which provides coverage to 172 million Americans — is necessary. Our National Task Force on the Future Role of Employers in the U.S. Health System, an expert group that has been meeting for more than a year, will soon weigh in with recommendations. But again, courage will be required if we are to see real change.
And third, here in the United States we spend the most — far more than other developed countries — but somehow have the least to show for it. We have lower life expectancy, higher infant mortality, more chronic disease and health disparities than counterpart nations across the globe. In addition, we have wide disparities across states in the U.S., in terms of health outcomes, access to care, quality, and equity. Our Mirror, Mirror 2024 report, which compares the performance of the health care systems of 10 countries, demonstrates yet again that the U.S. continues to be in a class by itself — trailing other countries in almost every measure of quality.
Public policy and health policy matter when it comes to health outcomes. This is true not only in our global comparisons but also bears out when we look at our Scorecard on State Health System Performance and our State Health Disparities Report. Commitments to a strong safety net, universal coverage, and quality and equity separate the top from the low performers across the states — in outcomes, access, quality, and equity. Another key differentiator is investment in primary care. Other nations devote 15 percent of their health care spending to primary care, but we commit a paltry 4 percent. It’s little wonder we have poorer health outcomes and a crisis in primary care. These lessons have been in front of our eyes for years, and there is a clear formula for how we can do better as a nation, but we seem to be stuck, needing real courage to change it.
As we look to 2025, we acknowledge these are big problems. Changing course will require following the evidence, looking at other proven models, and ultimately courage from all stakeholders in the health care system: leaders, providers, patients. In the meanwhile, many wonder what the new administration’s health care priorities will be. Will Medicaid remain the program we know today, protecting our most disadvantaged neighbors? How will the growth of Medicare Advantage affect seniors’ access to care? Will there be fundamental changes to — or a dismantling of — the Affordable Care Act?
And then, there are forces at work bigger than the U.S. political system. For one, technological advances, including AI, remote patient monitoring, wearable health technology, and genomics are rapidly changing health care — and hold promise make it more efficient and effective. But we must address the financing and implementation of these tools — and ensure they are not solely benefiting one group or population at the expense of everyone else. Public health, climate change, behavioral health, and maternal health remain fundamental challenges that will also require our resolute attention.
As the Commonwealth Fund moves into its 107th year, we will be supported by our newly launched values: to be bold and impactful, to center community and common humanity, to anchor equity and integrity in all we do, and to work in a collaborative and joyful environment. And we are strengthened by our Board of Directors. Dr. Margaret Hamburg, an internationally recognized authority in medicine and public health, finished her first year as board chair. We welcome her insights and expertise as we move forward. After 10 years, we bid farewell to board member Dr. Mark Smith. We benefitted greatly from Mark’s knowledge and experience in medicine and philanthropy.
So we say farewell to 2024, and welcome 2025. We’ve had an incredible year of accomplishments to build from, and I remain humbled, honored, and privileged to lead the Fund at this important time. Bolstered by our history, our values, our board, and our incredible team, we are ready to meet this moment, with bold investments, evidence, hard work, heart, and courage. We hope you will stay engaged with us as we remain committed to making the health care system work for everyone.
We all know what it means, colloquially, to google something. You pop a few relevant words in a search box and in return get a list of blue links to the most relevant results. Maybe some quick explanations up top. Maybe some maps or sports scores or a video. But fundamentally, it’s just fetching information that’s already out there on the internet and showing it to you, in some sort of structured way.
But all that is up for grabs. We are at a new inflection point.
The biggest change to the way search engines have delivered information to us since the 1990s is happening right now. No more keyword searching. No more sorting through links to click. Instead, we’re entering an era of conversational search. Which means instead of keywords, you use real questions, expressed in natural language. And instead of links, you’ll increasingly be met with answers, written by generative AI and based on live information from all across the internet, delivered the same way.
Of course, Google—the company that has defined search for the past 25 years—is trying to be out front on this. In May of 2023, it began testing AI-generated responses to search queries, using its large language model (LLM) to deliver the kinds of answers you might expect from an expert source or trusted friend. It calls these AI Overviews. Google CEO Sundar Pichai described this to MIT Technology Review as “one of the most positive changes we’ve done to search in a long, long time.”
AI Overviews fundamentally change the kinds of queries Google can address. You can now ask it things like “I’m going to Japan for one week next month. I’ll be staying in Tokyo but would like to take some day trips. Are there any festivals happening nearby? How will the surfing be in Kamakura? Are there any good bands playing?” And you’ll get an answer—not just a link to Reddit, but a built-out answer with current results.
More to the point, you can attempt searches that were once pretty much impossible, and get the right answer. You don’t have to be able to articulate what, precisely, you are looking for. You can describe what the bird in your yard looks like, or what the issue seems to be with your refrigerator, or that weird noise your car is making, and get an almost human explanation put together from sources previously siloed across the internet. It’s amazing, and once you start searching that way, it’s addictive.
And it’s not just Google. OpenAI’s ChatGPT now has access to the web, making it far better at finding up-to-date answers to your queries. Microsoft released generative search results for Bing in September. Meta has its own version. The startup Perplexity was doing the same, but with a “move fast, break things” ethos. Literal trillions of dollars are at stake in the outcome as these players jockey to become the next go-to source for information retrieval—the next Google.
Search firm Exa wants to use the tech behind large language models to tame the wildness of the web.
Not everyone is excited for the change. Publishers are completely freaked out. The shift has heightened fears of a “zero-click” future, where search referral traffic—a mainstay of the web since before Google existed—vanishes from the scene.
I got a vision of that future last June, when I got a push alert from the Perplexity app on my phone. Perplexity is a startup trying to reinvent web search. But in addition to delivering deep answers to queries, it will create entire articles about the news of the day, cobbled together by AI from different sources.
On that day, it pushed me a story about a new drone company from Eric Schmidt. I recognized the story. Forbeshad reported it exclusively, earlier in the week, but it had been locked behind a paywall. The image on Perplexity’s story looked identical to one from Forbes. The language and structure were quite similar. It was effectively the same story, but freely available to anyone on the internet. I texted a friend who had edited the original story to ask if Forbes had a deal with the startup to republish its content. But there was no deal. He was shocked and furious and, well, perplexed. He wasn’t alone. Forbes, the New York Times, and Condé Nast have now all sent the company cease-and-desist orders. News Corp is suing for damages.
People are worried about what these new LLM-powered results will mean for our fundamental shared reality. It could spell the end of the canonical answer.
It was precisely the nightmare scenario publishers have been so afraid of: The AI was hoovering up their premium content, repackaging it, and promoting it to its audience in a way that didn’t really leave any reason to click through to the original. In fact, on Perplexity’s About page, the first reason it lists to choose the search engine is “Skip the links.”
But this isn’t just about publishers (or my own self-interest).
People are also worried about what these new LLM-powered results will mean for our fundamental shared reality. Language models have a tendency to make stuff up—they can hallucinate nonsense. Moreover, generative AI can serve up an entirely new answer to the same question every time, or provide different answers to different people on the basis of what it knows about them. It could spell the end of the canonical answer.
But make no mistake: This is the future of search. Try it for a bit yourself, and you’ll see.
Sure, we will always want to use search engines to navigate the web and to discover new and interesting sources of information. But the links out are taking a back seat. The way AI can put together a well-reasoned answer to just about any kind of question, drawing on real-time data from across the web, just offers a better experience. That is especially true compared with what web search has become in recent years. If it’s not exactly broken (data shows more people are searching with Google more often than ever before), it’s at the very least increasingly cluttered and daunting to navigate.
Who wants to have to speak the language of search engines to find what you need? Who wants to navigate links when you can have straight answers? And maybe: Who wants to have to learn when you can just know?
In the beginning there was Archie. It was the first real internet search engine, and it crawled files previously hidden in the darkness of remote servers. It didn’t tell you what was in those files—just their names. It didn’t preview images; it didn’t have a hierarchy of results, or even much of an interface. But it was a start. And it was pretty good.
Then Tim Berners-Lee created the World Wide Web, and all manner of web pages sprang forth. The Mosaic home page and the Internet Movie Database and Geocities and the Hampster Dance and web rings and Salon and eBay and CNN and federal government sites and some guy’s home page in Turkey.
Until finally, there was too much web to even know where to start. We really needed a better way to navigate our way around, to actually find the things we needed.
AI advances are rapidly speeding up the process of training robots, and helping them do new tasks almost instantly.
And so in 1994 Jerry Yang created Yahoo, a hierarchical directory of websites. It quickly became the home page for millions of people. And it was … well, it was okay. TBH, and with the benefit of hindsight, I think we all thought it was much better back then than it actually was.
But the web continued to grow and sprawl and expand, every day bringing more information online. Rather than just a list of sites by category, we needed something that actually looked at all that content and indexed it. By the late ’90s that meant choosing from a variety of search engines: AltaVista and AlltheWeb and WebCrawler and HotBot. And they were good—a huge improvement. At least at first.
But alongside the rise of search engines came the first attempts to exploit their ability to deliver traffic. Precious, valuable traffic, which web publishers rely on to sell ads and retailers use to get eyeballs on their goods. Sometimes this meant stuffing pages with keywords or nonsense text designed purely to push pages higher up in search results. It got pretty bad.
And then came Google. It’s hard to overstate how revolutionary Google was when it launched in 1998. Rather than just scanning the content, it also looked at the sources linking to a website, which helped evaluate its relevance. To oversimplify: The more something was cited elsewhere, the more reliable Google considered it, and the higher it would appear in results. This breakthrough made Google radically better at retrieving relevant results than anything that had come before. It was amazing.
For 25 years, Google dominated search. Google was search, for most people. (The extent of that domination is currently the subject of multiple legal probes in the United States and the European Union.)
But Google has long been moving away from simply serving up a series of blue links, notes Pandu Nayak, Google’s chief scientist for search.
“It’s not just so-called web results, but there are images and videos, and special things for news. There have been direct answers, dictionary answers, sports, answers that come with Knowledge Graph, things like featured snippets,” he says, rattling off a litany of Google’s steps over the years to answer questions more directly.
It’s true: Google has evolved over time, becoming more and more of an answer portal. It has added tools that allow people to just get an answer—the live score to a game, the hours a café is open, or a snippet from the FDA’s website—rather than being pointed to a website where the answer may be.
But once you’ve used AI Overviews a bit, you realize they are different.
Take featured snippets, the passages Google sometimes chooses to highlight and show atop the results themselves. Those words are quoted directly from an original source. The same is true of knowledge panels, which are generated from information stored in a range of public databases and Google’s Knowledge Graph, its database of trillions of facts about the world.
While these can be inaccurate, the information source is knowable (and fixable). It’s in a database. You can look it up. Not anymore: AI Overviews can be entirely new every time, generated on the fly by a language model’s predictive text combined with an index of the web.
“I think it’s an exciting moment where we have obviously indexed the world. We built deep understanding on top of it with Knowledge Graph. We’ve been using LLMs and generative AI to improve our understanding of all that,” Pichai told MIT Technology Review. “But now we are able to generate and compose with that.”
The result feels less like a querying a database than like asking a very smart, well-read friend. (With the caveat that the friend will sometimes make things up if she does not know the answer.)
“[The company’s] mission is organizing the world’s information,” Liz Reid, Google’s head of search, tells me from its headquarters in Mountain View, California. “But actually, for a while what we did was organize web pages. Which is not really the same thing as organizing the world’s information or making it truly useful and accessible to you.”
That second concept—accessibility—is what Google is really keying in on with AI Overviews. It’s a sentiment I hear echoed repeatedly while talking to Google execs: They can address more complicated types of queries more efficiently by bringing in a language model to help supply the answers. And they can do it in natural language.
That will become even more important for a future where search goes beyond text queries. For example, Google Lens, which lets people take a picture or upload an image to find out more about something, uses AI-generated answers to tell you what you may be looking at. Google has even showed off the ability to query live video.
When it doesn’t have an answer, an AI model can confidently spew back a response anyway. For Google, this could be a real problem. For the rest of us, it could actually be dangerous.
“We are definitely at the start of a journey where people are going to be able to ask, and get answered, much more complex questions than where we’ve been in the past decade,” says Pichai.
There are some real hazards here. First and foremost: Large language models will lie to you. They hallucinate. They get shit wrong. When it doesn’t have an answer, an AI model can blithely and confidently spew back a response anyway. For Google, which has built its reputation over the past 20 years on reliability, this could be a real problem. For the rest of us, it could actually be dangerous.
In May 2024, AI Overviews were rolled out to everyone in the US. Things didn’t go well. Google, long the world’s reference desk, told people to eat rocks and to put glue on their pizza. These answers were mostly in response to what the company calls adversarial queries—those designed to trip it up. But still. It didn’t look good. The company quickly went to work fixing the problems—for example, by deprecating so-called user-generated content from sites like Reddit, where some of the weirder answers had come from.
Yet while its errors telling people to eat rocks got all the attention, the more pernicious danger might arise when it gets something less obviously wrong. For example, in doing research for this article, I asked Google when MIT Technology Review went online. It helpfully responded that “MIT Technology Review launched its online presence in late 2022.” This was clearly wrong to me, but for someone completely unfamiliar with the publication, would the error leap out?
I came across several examples like this, both in Google and in OpenAI’s ChatGPT search. Stuff that’s just far enough off the mark not to be immediately seen as wrong. Google is banking that it can continue to improve these results over time by relying on what it knows about quality sources.
“When we produce AI Overviews,” says Nayak, “we look for corroborating information from the search results, and the search results themselves are designed to be from these reliable sources whenever possible. These are some of the mechanisms we have in place that assure that if you just consume the AI Overview, and you don’t want to look further … we hope that you will still get a reliable, trustworthy answer.”
In the case above, the 2022 answer seemingly came from a reliable source—a story about MIT Technology Review’s email newsletters, which launched in 2022. But the machine fundamentally misunderstood. This is one of the reasons Google uses human beings—raters—to evaluate the results it delivers for accuracy. Ratings don’t correct or control individual AI Overviews; rather, they help train the model to build better answers. But human raters can be fallible. Google is working on that too.
“Raters who look at your experiments may not notice the hallucination because it feels sort of natural,” says Nayak. “And so you have to really work at the evaluation setup to make sure that when there is a hallucination, someone’s able to point out and say, That’s a problem.”
The new search
Google has rolled out its AI Overviews to upwards of a billion people in more than 100 countries, but it is facing upstarts with new ideas about how search should work.
Search Engine
Google The search giant has added AI Overviews to search results. These overviews take information from around the web and Google’s Knowledge Graph and use the company’s Gemini language model to create answers to search queries.
What it’s good at
Google’s AI Overviews are great at giving an easily digestible summary in response to even the most complex queries, with sourcing boxes adjacent to the answers. Among the major options, its deep web index feels the most “internety.” But web publishers fear its summaries will give people little reason to click through to the source material.
Perplexity Perplexity is a conversational search engine that uses third-party large language models from OpenAI and Anthropic to answer queries.
Perplexity is fantastic at putting together deeper dives in response to user queries, producing answers that are like mini white papers on complex topics. It’s also excellent at summing up current events. But it has gotten a bad rep with publishers, who say it plays fast and loose with their content.
ChatGPT While Google brought AI to search, OpenAI brought search to ChatGPT. Queries that the model determines will benefit from a web search automatically trigger one, or users can manually select the option to add a web search.
Thanks to its ability to preserve context across a conversation, ChatGPT works well for performing searches that benefit from follow-up questions—like planning a vacation through multiple search sessions. OpenAI says users sometimes go “20 turns deep” in researching queries. Of these three, it makes links out to publishers least prominent.
When I talked to Pichai about this, he expressed optimism about the company’s ability to maintain accuracy even with the LLM generating responses. That’s because AI Overviews is based on Google’s flagship large language model, Gemini, but also draws from Knowledge Graph and what it considers reputable sources around the web.
“You’re always dealing in percentages. What we have done is deliver it at, like, what I would call a few nines of trust and factuality and quality. I’d say 99-point-few-nines. I think that’s the bar we operate at, and it is true with AI Overviews too,” he says. “And so the question is, are we able to do this again at scale? And I think we are.”
There’s another hazard as well, though, which is that people ask Google all sorts of weird things. If you want to know someone’s darkest secrets, look at their search history. Sometimes the things people ask Google about are extremely dark. Sometimes they are illegal. Google doesn’t just have to be able to deploy its AI Overviews when an answer can be helpful; it has to be extremely careful not to deploy them when an answer may be harmful.
“If you go and say ‘How do I build a bomb?’ it’s fine that there are web results. It’s the open web. You can access anything,” Reid says. “But we do not need to have an AI Overview that tells you how to build a bomb, right? We just don’t think that’s worth it.”
But perhaps the greatest hazard—or biggest unknown—is for anyone downstream of a Google search. Take publishers, who for decades now have relied on search queries to send people their way. What reason will people have to click through to the original source, if all the information they seek is right there in the search result?
Plus: The original startup behind Stable Diffusion has launched a generative AI for video.
Rand Fishkin, cofounder of the market research firm SparkToro, publishes research on so-called zero-click searches. As Google has moved increasingly into the answer business, the proportion of searches that end without a click has gone up and up. His sense is that AI Overviews are going to explode this trend.
“If you are reliant on Google for traffic, and that traffic is what drove your business forward, you are in long- and short-term trouble,” he says.
Don’t panic, is Pichai’s message. He argues that even in the age of AI Overviews, people will still want to click through and go deeper for many types of searches. “The underlying principle is people are coming looking for information. They’re not looking for Google always to just answer,” he says. “Sometimes yes, but the vast majority of the times, you’re looking at it as a jumping-off point.”
Reid, meanwhile, argues that because AI Overviews allow people to ask more complicated questions and drill down further into what they want, they could even be helpful to some types of publishers and small businesses, especially those operating in the niches: “You essentially reach new audiences, because people can now express what they want more specifically, and so somebody who specializes doesn’t have to rank for the generic query.”
“I’m going to start with something risky,” Nick Turley tells me from the confines of a Zoom window. Turley is the head of product for ChatGPT, and he’s showing off OpenAI’s new web search tool a few weeks before it launches. “I should normally try this beforehand, but I’m just gonna search for you,” he says. “This is always a high-risk demo to do, because people tend to be particular about what is said about them on the internet.”
He types my name into a search field, and the prototype search engine spits back a few sentences, almost like a speaker bio. It correctly identifies me and my current role. It even highlights a particular story I wrote years ago that was probably my best known. In short, it’s the right answer. Phew?
A few weeks after our call, OpenAI incorporated search into ChatGPT, supplementing answers from its language model with information from across the web. If the model thinks a response would benefit from up-to-date information, it will automatically run a web search (OpenAI won’t say who its search partners are) and incorporate those responses into its answer, with links out if you want to learn more. You can also opt to manually force it to search the web if it does not do so on its own. OpenAI won’t reveal how many people are using its web search, but it says some 250 million people use ChatGPT weekly, all of whom are potentially exposed to it.
“There’s an incredible amount of content on the web. There are a lot of things happening in real time. You want ChatGPT to be able to use that to improve its answers and to be a better super-assistant for you.”Kevin Weil, chief product officer, OpenAI
According to Fishkin, these newer forms of AI-assisted search aren’t yet challenging Google’s search dominance. “It does not appear to be cannibalizing classic forms of web search,” he says.
OpenAI insists it’s not really trying to compete on search—although frankly this seems to me like a bit of expectation setting. Rather, it says, web search is mostly a means to get more current information than the data in its training models, which tend to have specific cutoff dates that are often months, or even a year or more, in the past. As a result, while ChatGPT may be great at explaining how a West Coast offense works, it has long been useless at telling you what the latest 49ers score is. No more.
“I come at it from the perspective of ‘How can we make ChatGPT able to answer every question that you have? How can we make it more useful to you on a daily basis?’ And that’s where search comes in for us,” Kevin Weil, the chief product officer with OpenAI, tells me. “There’s an incredible amount of content on the web. There are a lot of things happening in real time. You want ChatGPT to be able to use that to improve its answers and to be able to be a better super-assistant for you.”
Today ChatGPT is able to generate responses for very current news events, as well as near-real-time information on things like stock prices. And while ChatGPT’s interface has long been, well, boring, search results bring in all sorts of multimedia—images, graphs, even video. It’s a very different experience.
Weil also argues that ChatGPT has more freedom to innovate and go its own way than competitors like Google—even more than its partner Microsoft does with Bing. Both of those are ad-dependent businesses. OpenAI is not. (At least not yet.) It earns revenue from the developers, businesses, and individuals who use it directly. It’s mostly setting large amounts of money on fire right now—it’s projected to lose $14 billion in 2026, by some reports. But one thing it doesn’t have to worry about is putting ads in its search results as Google does.
Like Google, ChatGPT is pulling in information from web publishers, summarizing it, and including it in its answers. But it has also struck financial deals with publishers, a payment for providing the information that gets rolled into its results. (MIT Technology Review has been in discussions with OpenAI, Google, Perplexity, and others about publisher deals but has not entered into any agreements. Editorial was neither party to nor informed about the content of those discussions.)
But the thing is, for web search to accomplish what OpenAI wants—to be more current than the language model—it also has to bring in information from all sorts of publishers and sources that it doesn’t have deals with. OpenAI’s head of media partnerships, Varun Shetty, told MIT Technology Review that it won’t give preferential treatment to its publishing partners.
Instead, OpenAI told me, the model itself finds the most trustworthy and useful source for any given question. And that can get weird too. In that very first example it showed me—when Turley ran that name search—it described a story I wrote years ago for Wired about being hacked. That story remains one of the most widely read I’ve ever written. But ChatGPT didn’t link to it. It linked to a short rewrite from The Verge. Admittedly, this was on a prototype version of search, which was, as Turley said, “risky.”
When I asked him about it, he couldn’t really explain why the model chose the sources that it did, because the model itself makes that evaluation. The company helps steer it by identifying—sometimes with the help of users—what it considers better answers, but the model actually selects them.
“And in many cases, it gets it wrong, which is why we have work to do,” said Turley. “Having a model in the loop is a very, very different mechanism than how a search engine worked in the past.”
Indeed!
The model, whether it’s OpenAI’s GPT-4o or Google’s Gemini or Anthropic’s Claude, can be very, very good at explaining things. But the rationale behind its explanations, its reasons for selecting a particular source, and even the language it may use in an answer are all pretty mysterious. Sure, a model can explain very many things, but not when that comes to its own answers.
It was almost a decade ago, in 2016, when Pichai wrote that Google was moving from “mobile first” to “AI first”: “But in the next 10 years, we will shift to a world that is AI-first, a world where computing becomes universally available—be it at home, at work, in the car, or on the go—and interacting with all of these surfaces becomes much more natural and intuitive, and above all, more intelligent.”
We’re there now—sort of. And it’s a weird place to be. It’s going to get weirder. That’s especially true as these things we now think of as distinct—querying a search engine, prompting a model, looking for a photo we’ve taken, deciding what we want to read or watch or hear, asking for a photo we wish we’d taken, and didn’t, but would still like to see—begin to merge.
Google’s new AI search feature is a mess. So why is it telling us to eat rocks and gluey pizza, and can it be fixed?
The search results we see from generative AI are best understood as a waypoint rather than a destination. What’s most important may not be search in itself; rather, it’s that search has given AI model developers a path to incorporating real-time information into their inputs and outputs. And that opens up all sorts of possibilities.
“A ChatGPT that can understand and access the web won’t just be about summarizing results. It might be about doing things for you. And I think there’s a fairly exciting future there,” says OpenAI’s Weil. “You can imagine having the model book you a flight, or order DoorDash, or just accomplish general tasks for you in the future. It’s just once the model understands how to use the internet, the sky’s the limit.”
This is the agentic future we’ve been hearing about for some time now, and the more AI models make use of real-time data from the internet, the closer it gets.
Let’s say you have a trip coming up in a few weeks. An agent that can get data from the internet in real time can book your flights and hotel rooms, make dinner reservations, and more, based on what it knows about you and your upcoming travel—all without your having to guide it. Another agent could, say, monitor the sewage output of your home for certain diseases, and order tests and treatments in response. You won’t have to search for that weird noise your car is making, because the agent in your vehicle will already have done it and made an appointment to get the issue fixed.
“It’s not always going to be just doing search and giving answers,” says Pichai. “Sometimes it’s going to be actions. Sometimes you’ll be interacting within the real world. So there is a notion of universal assistance through it all.”
The model, whether it’s OpenAI’s GPT-4o or Google’s Gemini or Anthropic’s Claude, can be very, very good at explaining things. But the rationale behind its explanations, its reasons for selecting a particular source, and even the language it may use in an answer are all pretty mysterious. Sure, a model can explain very many things, but not when that comes to its own answers.
It was almost a decade ago, in 2016, when Pichai wrote that Google was moving from “mobile first” to “AI first”: “But in the next 10 years, we will shift to a world that is AI-first, a world where computing becomes universally available—be it at home, at work, in the car, or on the go—and interacting with all of these surfaces becomes much more natural and intuitive, and above all, more intelligent.”
We’re there now—sort of. And it’s a weird place to be. It’s going to get weirder. That’s especially true as these things we now think of as distinct—querying a search engine, prompting a model, looking for a photo we’ve taken, deciding what we want to read or watch or hear, asking for a photo we wish we’d taken, and didn’t, but would still like to see—begin to merge.
Google’s new AI search feature is a mess. So why is it telling us to eat rocks and gluey pizza, and can it be fixed?
The search results we see from generative AI are best understood as a waypoint rather than a destination. What’s most important may not be search in itself; rather, it’s that search has given AI model developers a path to incorporating real-time information into their inputs and outputs. And that opens up all sorts of possibilities.
“A ChatGPT that can understand and access the web won’t just be about summarizing results. It might be about doing things for you. And I think there’s a fairly exciting future there,” says OpenAI’s Weil. “You can imagine having the model book you a flight, or order DoorDash, or just accomplish general tasks for you in the future. It’s just once the model understands how to use the internet, the sky’s the limit.”
This is the agentic future we’ve been hearing about for some time now, and the more AI models make use of real-time data from the internet, the closer it gets.
Let’s say you have a trip coming up in a few weeks. An agent that can get data from the internet in real time can book your flights and hotel rooms, make dinner reservations, and more, based on what it knows about you and your upcoming travel—all without your having to guide it. Another agent could, say, monitor the sewage output of your home for certain diseases, and order tests and treatments in response. You won’t have to search for that weird noise your car is making, because the agent in your vehicle will already have done it and made an appointment to get the issue fixed.
“It’s not always going to be just doing search and giving answers,” says Pichai. “Sometimes it’s going to be actions. Sometimes you’ll be interacting within the real world. So there is a notion of universal assistance through it all.”
In the high-stakes and rapidly evolving world of artificial intelligence, a dramatic legal confrontation has emerged between Elon Musk and OpenAI. This case offers a fascinating lens into the intersection of technological ambition, corporate transformation, and personal rivalries, revealing a complex narrative with far-reaching implications.
The Roots of the Conflict
Elon Musk, once a co-founder and major supporter of OpenAI, has filed a lawsuit to challenge the organization’s transformation from a non-profit research lab to a profit-driven enterprise. Musk’s original vision for OpenAI was a safeguard against unchecked AI development—a mission to ensure that artificial intelligence would benefit humanity as a whole. However, OpenAI’s pivot to a “capped-profit” model, and its subsequent collaborations with industry giants like Microsoft, has sparked accusations of betrayal and overreach.
At the heart of Musk’s complaint lies a series of allegations: OpenAI’s deviation from its founding principles, its potential monopolistic behavior, and its partnerships that allegedly block competition, particularly for Musk’s own AI venture, xAI. This battle isn’t just about legal technicalities; it’s a clash of ideologies and business strategies in an industry shaping the future of human civilization.
How Conflict Began
OpenAI was created in 2015 as a non-profit group with a good goal: to create artificial general intelligence (AGI) that will help people. Musk helped to start the company and put $44 million into it early on. But things have gone very badly between them, and now there is a public case that shows how tense things are inside the AI business.
OpenAI’s Explosive Growth
The business has had a lot of amazing financial success:
– Valuation: $157 billion as of January 2024
– Annual Recurring Revenue: $4 billion in September 2024
– Year-over-Year Growth: 248%
– ChatGPT Revenue: $2.9 billion ARR
Musk’s Defence in Court
Elon Musk has filed a legal motion asking the federal court to intervene in OpenAI’s shift from its original non-profit status to a fully for-profit model. Musk’s arguments center on four key allegations:
Antitrust Violations: Musk claims that OpenAI’s transformation into a profit-driven entity has created unfair market conditions, potentially breaching antitrust laws. He argues that OpenAI’s monopolistic behavior could stifle innovation and competition in the AI industry.
Deviation from Charitable Goals: Musk asserts that OpenAI has strayed from its founding mission as a non-profit organization dedicated to the ethical development of artificial intelligence for the benefit of humanity. He argues that this shift undermines the trust and goodwill upon which the organization was initially built.
Improper Data Sharing with Microsoft: OpenAI’s partnership with Microsoft, including the integration of its models into Microsoft’s products, has raised concerns. Musk alleges that OpenAI improperly shared proprietary data and research with Microsoft, giving the tech giant an unfair advantage in the AI race.
Blocking Funds for Competing AI Ventures: Musk contends that OpenAI’s current structure and funding mechanisms effectively block resources for competing AI startups, including his own venture, xAI. He claims this is a deliberate attempt to consolidate power and suppress competition.
OpenAI’s Counterattack
In response to Musk’s claims, OpenAI has presented evidence suggesting that Musk himself played a pivotal role in advocating for the organization’s shift toward a for-profit model. The counterarguments are supported by the following revelations:
2017 Text Messages Supporting For-Profit Conversion: OpenAI has released internal communications, including text messages from 2017, where Musk is shown discussing the advantages of converting OpenAI into a for-profit entity. These messages allegedly include Musk’s rationale that such a move would attract greater investment and accelerate AI development.
Formation of a For-Profit Entity: OpenAI disclosed that Musk was instrumental in creating a new entity named “Open Artificial Intelligence Technologies, Inc.” during his tenure. This for-profit entity was proposed as a potential structure to secure funding and partnerships, aligning with Musk’s vision at the time.
Musk’s Equity Demands: OpenAI claims that Musk sought significant control over the new organization, allegedly requesting 50-60% equity in the for-profit venture. This demand reportedly led to internal conflicts and contributed to Musk’s eventual departure from OpenAI.
The legal battle highlights a clash between two narratives: Musk’s portrayal of OpenAI as having abandoned its altruistic roots versus OpenAI’s depiction of Musk as a key proponent of the very changes he now criticizes. The outcome may hinge on the court’s interpretation of the evidence, including Musk’s historical involvement and the current implications of OpenAI’s operational model.
xAI vs. OpenAI
The rivalry between xAI and OpenAI represents a broader ideological and competitive battle within the artificial intelligence industry. Both organizations aim to advance AI technology, but their approaches, missions, and strategies differ significantly, reflecting the contrasting visions of their leaders and the market forces shaping the industry.
Mission and Vision
OpenAI
Founding Philosophy: OpenAI was established in 2015 as a non-profit organization with the mission to ensure that artificial general intelligence (AGI) benefits all of humanity. Its early focus was on transparency, collaboration, and ethical AI development.
Shift to Profit: Over time, OpenAI transitioned to a “capped-profit” model, allowing it to attract billions in funding from investors like Microsoft. This pivot enabled rapid technological advancements but drew criticism for deviating from its altruistic roots.
Current Focus: OpenAI is focused on scaling large language models like GPT, developing AI tools for widespread adoption, and partnering with corporations to integrate AI into existing ecosystems.
xAI
Founding Philosophy: Founded by Elon Musk in 2023, xAI positions itself as a challenger to existing AI giants, particularly OpenAI. Musk emphasizes the need for AI to be aligned with human values and safe from monopolistic control.
Vision: xAI aims to create “truth-seeking” AI, prioritizing transparency and addressing biases in current AI models. Musk envisions xAI as a counterbalance to what he perceives as the commercialization and ethical compromises of organizations like OpenAI.
Current Focus: xAI’s primary goal is to build AGI while integrating AI systems with real-world applications, including Tesla’s autonomous driving technology and SpaceX’s operations.
Technological Approaches
OpenAI
Large-Scale Models: OpenAI has pioneered the development of large language models (LLMs) like GPT, which are trained on vast datasets and optimized for general-purpose tasks.
Corporate Partnerships: Through its partnership with Microsoft, OpenAI has integrated its models into products like Azure AI and Microsoft Office, focusing on scalability and usability.
Infrastructure: OpenAI leverages massive computational resources and advanced infrastructure to maintain its lead in AI research.
xAI
Interdisciplinary Integration: xAI emphasizes the integration of AI with other domains, such as robotics and space exploration. This approach leverages Musk’s broader ecosystem of companies, including Tesla and SpaceX.
Transparency and Explainability: xAI focuses on creating interpretable AI systems to address concerns about bias and opacity in existing models.
Lean Development: Unlike OpenAI’s reliance on external partnerships, xAI seeks to operate with a leaner, more independent structure, leveraging Musk’s resources and influence.
Business Models
OpenAI
Capped-Profit Model: OpenAI LP operates under a capped-profit structure, allowing investors to earn returns while funneling excess profits back into research.
Revenue Streams: OpenAI generates revenue through API access, licensing agreements, and partnerships with tech giants like Microsoft.
Criticism: The shift to a profit-driven model has raised concerns about ethical compromises and the monopolization of AI.
xAI
Private Funding: xAI is privately funded, with Musk leveraging his wealth and resources from Tesla, SpaceX, and other ventures.
Strategic Synergies: xAI integrates AI into Musk’s existing businesses, creating a symbiotic relationship that reduces dependency on external funding.
Focus on Disruption: xAI aims to disrupt the AI industry by challenging incumbents like OpenAI and offering alternatives aligned with Musk’s vision of ethical AI.
Ethical Stances
OpenAI
Advocates for the safe and ethical development of AGI but has faced criticism for its perceived lack of transparency and partnerships with large corporations.
Balances innovation with corporate interests, which some argue compromises its ability to act in the public good.
xAI
Emphasizes transparency, truth-seeking, and alignment with human values, presenting itself as a more ethical alternative to OpenAI.
Musk’s history of controversial decisions and statements has led to skepticism about xAI’s ability to deliver on these promises.
Market Position
OpenAI: A dominant player with established partnerships, significant market penetration, and a head start in deploying AI technologies at scale.
xAI: A newcomer with the advantage of Musk’s influence, vision, and resources, positioning itself as a disruptive force in the AI landscape.
Conclusion
The Musk-OpenAI courtroom drama is a microcosm of the larger AI industry—a field marked by breathtaking innovation, high-stakes rivalries, and ethical dilemmas. Both parties are vying not only for legal vindication but also for control over the narrative of AI’s future. Whether the court sides with Musk’s critique of OpenAI’s alleged betrayal or OpenAI’s portrayal of Musk as a contradictory figure, the outcome will likely have profound consequences for the governance and development of artificial intelligence.
An electronic stacking technique could exponentially increase the number of transistors on chips, enabling more efficient AI hardware.
Jennifer Chu | MIT News
Publication Date: December 18, 2024
The electronics industry is approaching a limit to the number of transistors that can be packed onto the surface of a computer chip. So, chip manufacturers are looking to build up rather than out.
Instead of squeezing ever-smaller transistors onto a single surface, the industry is aiming to stack multiple surfaces of transistors and semiconducting elements — akin to turning a ranch house into a high-rise. Such multilayered chips could handle exponentially more data and carry out many more complex functions than today’s electronics.
A significant hurdle, however, is the platform on which chips are built. Today, bulky silicon wafers serve as the main scaffold on which high-quality, single-crystalline semiconducting elements are grown. Any stackable chip would have to include thick silicon “flooring” as part of each layer, slowing down any communication between functional semiconducting layers.
Now, MIT engineers have found a way around this hurdle, with a multilayered chip design that doesn’t require any silicon wafer substrates and works at temperatures low enough to preserve the underlying layer’s circuitry.
In a study appearing today in the journal Nature, the team reports using the new method to fabricate a multilayered chip with alternating layers of high-quality semiconducting material grown directly on top of each other.
The method enables engineers to build high-performance transistors and memory and logic elements on any random crystalline surface — not just on the bulky crystal scaffold of silicon wafers. Without these thick silicon substrates, multiple semiconducting layers can be in more direct contact, leading to better and faster communication and computation between layers, the researchers say.
The researchers envision that the method could be used to build AI hardware, in the form of stacked chips for laptops or wearable devices, that would be as fast and powerful as today’s supercomputers and could store huge amounts of data on par with physical data centers.
“This breakthrough opens up enormous potential for the semiconductor industry, allowing chips to be stacked without traditional limitations,” says study author Jeehwan Kim, associate professor of mechanical engineering at MIT. “This could lead to orders-of-magnitude improvements in computing power for applications in AI, logic, and memory.”
The study’s MIT co-authors include first author Ki Seok Kim, Seunghwan Seo, Doyoon Lee, Jung-El Ryu, Jekyung Kim, Jun Min Suh, June-chul Shin, Min-Kyu Song, Jin Feng, and Sangho Lee, along with collaborators from Samsung Advanced Institute of Technology, Sungkyunkwan University in South Korea, and the University of Texas at Dallas.
Seed pockets
In 2023, Kim’s group reported that they developed a method to grow high-quality semiconducting materials on amorphous surfaces, similar to the diverse topography of semiconducting circuitry on finished chips. The material that they grew was a type of 2D material known as transition-metal dichalcogenides, or TMDs, considered a promising successor to silicon for fabricating smaller, high-performance transistors. Such 2D materials can maintain their semiconducting properties even at scales as small as a single atom, whereas silicon’s performance sharply degrades.
In their previous work, the team grew TMDs on silicon wafers with amorphous coatings, as well as over existing TMDs. To encourage atoms to arrange themselves into high-quality single-crystalline form, rather than in random, polycrystalline disorder, Kim and his colleagues first covered a silicon wafer in a very thin film, or “mask” of silicon dioxide, which they patterned with tiny openings, or pockets. They then flowed a gas of atoms over the mask and found that atoms settled into the pockets as “seeds.” The pockets confined the seeds to grow in regular, single-crystalline patterns.
But at the time, the method only worked at around 900 degrees Celsius.
“You have to grow this single-crystalline material below 400 Celsius, otherwise the underlying circuitry is completely cooked and ruined,” Kim says. “So, our homework was, we had to do a similar technique at temperatures lower than 400 Celsius. If we could do that, the impact would be substantial.”
Building up
In their new work, Kim and his colleagues looked to fine-tune their method in order to grow single-crystalline 2D materials at temperatures low enough to preserve any underlying circuitry. They found a surprisingly simple solution in metallurgy — the science and craft of metal production. When metallurgists pour molten metal into a mold, the liquid slowly “nucleates,” or forms grains that grow and merge into a regularly patterned crystal that hardens into solid form. Metallurgists have found that this nucleation occurs most readily at the edges of a mold into which liquid metal is poured.
“It’s known that nucleating at the edges requires less energy — and heat,” Kim says. “So we borrowed this concept from metallurgy to utilize for future AI hardware.”
The team looked to grow single-crystalline TMDs on a silicon wafer that already has been fabricated with transistor circuitry. They first covered the circuitry with a mask of silicon dioxide, just as in their previous work. They then deposited “seeds” of TMD at the edges of each of the mask’s pockets and found that these edge seeds grew into single-crystalline material at temperatures as low as 380 degrees Celsius, compared to seeds that started growing in the center, away from the edges of each pocket, which required higher temperatures to form single-crystalline material.
Going a step further, the researchers used the new method to fabricate a multilayered chip with alternating layers of two different TMDs — molybdenum disulfide, a promising material candidate for fabricating n-type transistors; and tungsten diselenide, a material that has potential for being made into p-type transistors. Both p- and n-type transistors are the electronic building blocks for carrying out any logic operation. The team was able to grow both materials in single-crystalline form, directly on top of each other, without requiring any intermediate silicon wafers. Kim says the method will effectively double the density of a chip’s semiconducting elements, and particularly, metal-oxide semiconductor (CMOS), which is a basic building block of a modern logic circuitry.
“A product realized by our technique is not only a 3D logic chip but also 3D memory and their combinations,” Kim says. “With our growth-based monolithic 3D method, you could grow tens to hundreds of logic and memory layers, right on top of each other, and they would be able to communicate very well.”
“Conventional 3D chips have been fabricated with silicon wafers in-between, by drilling holes through the wafer — a process which limits the number of stacked layers, vertical alignment resolution, and yields,” first author Kiseok Kim adds. “Our growth-based method addresses all of those issues at once.”
To commercialize their stackable chip design further, Kim has recently spun off a company, FS2 (Future Semiconductor 2D materials).
“We so far show a concept at a small-scale device arrays,” he says. “The next step is scaling up to show professional AI chip operation.”
This research is supported, in part, by Samsung Advanced Institute of Technology and the U.S. Air Force Office of Scientific Research.
AI is all about data. Reams and reams of data are needed to train algorithms to do what we want, and what goes into the AI models determines what comes out. But here’s the problem: AI developers and researchers don’t really know much about the sources of the data they are using. AI’s data collection practices are immature compared with the sophistication of AI model development. Massive data sets often lack clear information about what is in them and where it came from.
The Data Provenance Initiative, a group of over 50 researchers from both academia and industry, wanted to fix that. They wanted to know, very simply: Where does the data to build AI come from? They audited nearly 4,000 public data sets spanning over 600 languages, 67 countries, and three decades. The data came from 800 unique sources and nearly 700 organizations.
Their findings, shared exclusively with MIT Technology Review, show a worrying trend: AI’s data practices risk concentrating power overwhelmingly in the hands of a few dominant technology companies.
In the early 2010s, data sets came from a variety of sources, says Shayne Longpre, a researcher at MIT who is part of the project.
It came not just from encyclopedias and the web, but also from sources such as parliamentary transcripts, earning calls, and weather reports. Back then, AI data sets were specifically curated and collected from different sources to suit individual tasks, Longpre says.
Then transformers, the architecture underpinning language models, were invented in 2017, and the AI sector started seeing performance get better the bigger the models and data sets were. Today, most AI data sets are built by indiscriminately hoovering material from the internet. Since 2018, the web has been the dominant source for data sets used in all media, such as audio, images, and video, and a gap between scraped data and more curated data sets has emerged and widened.
“In foundation model development, nothing seems to matter more for the capabilities than the scale and heterogeneity of the data and the web,” says Longpre. The need for scale has also boosted the use of synthetic data massively.
The past few years have also seen the rise of multimodal generative AI models, which can generate videos and images. Like large language models, they need as much data as possible, and the best source for that has become YouTube.
For video models, as you can see in this chart, over 70% of data for both speech and image data sets comes from one source.
This could be a boon for Alphabet, Google’s parent company, which owns YouTube. Whereas text is distributed across the web and controlled by many different websites and platforms, video data is extremely concentrated in one platform.
“It gives a huge concentration of power over a lot of the most important data on the web to one company,” says Longpre.
And because Google is also developing its own AI models, its massive advantage also raises questions about how the company will make this data available for competitors, says Sarah Myers West, the co–executive director at the AI Now Institute.
“It’s important to think about data not as though it’s sort of this naturally occurring resource, but it’s something that is created through particular processes,” says Myers West.
“If the data sets on which most of the AI that we’re interacting with reflect the intentions and the design of big, profit-motivated corporations—that’s reshaping the infrastructures of our world in ways that reflect the interests of those big corporations,” she says.
This monoculture also raises questions about how accurately the human experience is portrayed in the data set and what kinds of models we are building, says Sara Hooker, the vice president of research at the technology company Cohere, who is also part of the Data Provenance Initiative.
People upload videos to YouTube with a particular audience in mind, and the way people act in those videos is often intended for very specific effect. “Does [the data] capture all the nuances of humanity and all the ways that we exist?” says Hooker.
Hidden restrictions
AI companies don’t usually share what data they used to train their models. One reason is that they want to protect their competitive edge. The other is that because of the complicated and opaque way data sets are bundled, packaged, and distributed, they likely don’t even know where all the data came from.
They also probably don’t have complete information about any constraints on how that data is supposed to be used or shared. The researchers at the Data Provenance Initiative found that data sets often have restrictive licenses or terms attached to them, which should limit their use for commercial purposes, for example.
“This lack of consistency across the data lineage makes it very hard for developers to make the right choice about what data to use,” says Hooker.
It also makes it almost impossible to be completely certain you haven’t trained your model on copyrighted data, adds Longpre.
More recently, companies such as OpenAI and Google have struck exclusive data-sharing deals with publishers, major forums such as Reddit, and social media platforms on the web. But this becomes another way for them to concentrate their power.
“These exclusive contracts can partition the internet into various zones of who can get access to it and who can’t,” says Longpre.
The trend benefits the biggest AI players, who can afford such deals, at the expense of researchers, nonprofits, and smaller companies, who will struggle to get access. The largest companies also have the best resources for crawling data sets.
“This is a new wave of asymmetric access that we haven’t seen to this extent on the open web,” Longpre says.
The West vs. the rest
The data that is used to train AI models is also heavily skewed to the Western world. Over 90% of the data sets that the researchers analyzed came from Europe and North America, and fewer than 4% came from Africa.
“These data sets are reflecting one part of our world and our culture, but completely omitting others,” says Hooker.
The dominance of the English language in training data is partly explained by the fact that the internet is still over 90% in English, and there are still a lot of places on Earth where there’s really poor internet connection or none at all, says Giada Pistilli, principal ethicist at Hugging Face, who was not part of the research team. But another reason is convenience, she adds: Putting together data sets in other languages and taking other cultures into account requires conscious intention and a lot of work.
The Western focus of these data sets becomes particularly clear with multimodal models. When an AI model is prompted for the sights and sounds of a wedding, for example, it might only be able to represent Western weddings, because that’s all that it has been trained on, Hooker says.
This reinforces biases and could lead to AI models that push a certain US-centric worldview, erasing other languages and cultures.
“We are using these models all over the world, and there’s a massive discrepancy between the world we’re seeing and what’s invisible to these models,” Hooker says.