Research led by Professor Withawat Withayachumnankul, University of Adelaide
Aug 30, 2024
SUITA, Japan — The road to 6G wireless networks just got a little smoother. Scientists have made a significant leap forward in terahertz technology, potentially revolutionizing how we communicate in the future. An international team has developed a tiny silicon device that could double the capacity of wireless networks, bringing us closer to the promise of 6G and beyond.
Imagine a world where you could download an entire season of your favorite show in seconds or where virtual reality feels as real as, well, reality. This is what scientists believe terahertz technology can potentially bring to the world. Their work is published in the journal Laser & Photonics Review.
This tiny marvel, a silicon chip smaller than a grain of rice, operates in a part of the electromagnetic spectrum that most of us have never heard of: the terahertz range. Think of the electromagnetic spectrum as a vast highway of information.
We’re currently cruising along in the relatively slow lanes of 4G and 5G. Terahertz technology? That’s the express lane, promising speeds that make our current networks look like horse-drawn carriages in comparison.
Terahertz waves occupy a sweet spot in the electromagnetic spectrum between microwaves and infrared light. They’ve long been seen as a promising frontier for wireless communication because they can carry vast amounts of data. However, harnessing this potential has been challenging due to technical limitations.
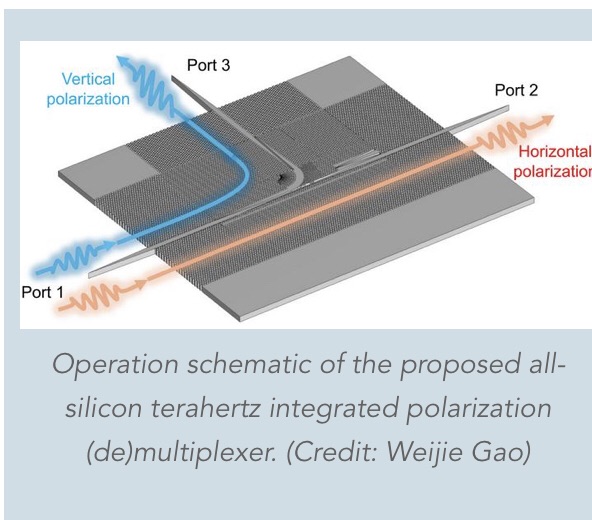
The researchers’ new device, called a “polarization multiplexer,” tackles one of the key hurdles in terahertz communication: efficiently managing different polarizations of terahertz waves. Polarization refers to the orientation of the wave’s oscillation. By cleverly manipulating these polarizations, the team has essentially created a traffic control system for terahertz waves, allowing more data to be transmitted simultaneously.
If that sounds like technobabble, think of it as a traffic cop for data, able to direct twice as much information down the same road without causing a jam.
“Our proposed polarization multiplexer will allow multiple data streams to be transmitted simultaneously over the same frequency band, effectively doubling the data capacity,” explains lead researcher Professor Withawat Withayachumnankul from the University of Adelaide, in a statement.
At the heart of this innovation is a compact silicon chip measuring just a few millimeters across. Despite its small size, this chip can separate and combine terahertz waves with different polarizations with remarkable efficiency. It’s like having a tiny, incredibly precise sorting machine for light waves.
To create this device, the researchers used a 250-micrometer-thick silicon wafer with very high electrical resistance. They employed a technique called deep reactive-ion etching to carve intricate patterns into the silicon. These patterns, consisting of carefully designed holes and structures, form what’s known as an “effective medium” – a material that interacts with terahertz waves in specific ways.
The team then subjected their device to a battery of tests using specialized equipment. They used a vector network analyzer with extension modules capable of generating and detecting terahertz waves in the 220-330 GHz range with minimal signal loss. This allowed them to measure how well the device could handle different polarizations of terahertz waves across a wide range of frequencies.
“This large relative bandwidth is a record for any integrated multiplexers found in any frequency range. If it were to be scaled to the center frequency of the optical communications bands, such a bandwidth could cover all the optical communications bands.”
In their experiments, the researchers demonstrated that their device could effectively separate and combine two different polarizations of terahertz waves with high efficiency. The device showed an average signal loss of only about 1 decibel – a remarkably low figure that indicates very little energy is wasted in the process. Even more impressively, the device maintained a polarization extinction ratio (a measure of how well it can distinguish between different polarizations) of over 20 decibels across its operating range. This is crucial for ensuring that data transmitted on different polarizations doesn’t interfere with each other.
To put the potential of this technology into perspective, the researchers conducted several real-world tests. In one demonstration, they used their device to transmit two separate high-definition video streams simultaneously over a terahertz link. This showcases the technology’s ability to handle multiple data streams at once, effectively doubling the amount of information that can be sent over a single channel.
But the team didn’t stop there. In more advanced tests, they pushed the limits of data transmission speed. Using a technique called on-off keying, they achieved error-free data rates of up to 64 gigabits per second. When they employed a more complex modulation scheme (16-QAM), they reached staggering data rates of up to 190 gigabits per second. That’s roughly equivalent to downloading 24 gigabytes – or about six high-definition movies – in a single second. It’s a staggering leap from current wireless technologies.
Still, the researchers say it’s not just about speed. This device is also incredibly versatile.
“This innovation not only enhances the efficiency of terahertz communication systems but also paves the way for more robust and reliable high-speed wireless networks,” adds Dr. Weijie Gao, a postdoctoral researcher at Osaka University and co-author of the study
The implications of this technology stretch far beyond faster Netflix downloads. We’re talking about advancements that could revolutionize augmented reality, enable seamless remote surgery, or create virtual worlds so immersive you might forget they’re not real. The best part? This isn’t some far-off dream.
“We anticipate that within the next one to two years, researchers will begin to explore new applications and refine the technology,” says Professor Masayuki Fujita of Osaka University.
So, while you might not find a terahertz chip in your next smartphone upgrade, don’t be surprised if, in the not-too-distant future, you’re streaming holographic video calls or controlling smart devices with your mind. The terahertz revolution is coming, and it’s bringing a future that’s faster, more connected, and more exciting than we ever imagined.
Paper Summary
Methodology
The researchers created their device using a high-purity silicon wafer, carefully etched to create precise microscopic structures. They employed a technique called deep reactive-ion etching, which allowed them to shape the silicon at an incredibly small scale. The key to the device’s performance is its use of an “effective medium” – a material engineered to have specific properties by creating patterns smaller than the wavelength of the terahertz waves being used.
Key Results
The team’s polarization multiplexer demonstrated impressive performance across a wide range of terahertz frequencies (220 to 330 GHz). It effectively separated two polarizations of light with minimal signal loss. In practical demonstrations, they successfully transmitted two separate high-definition video streams simultaneously without interference. The device also achieved data transmission rates of up to 155 gigabits per second, far exceeding current wireless technologies.
Study Limitations
Despite the promising results, challenges remain. Terahertz waves have limited range and struggle to penetrate obstacles, potentially restricting their use to short-range applications. Generating and detecting terahertz waves efficiently is still a technical hurdle. The researchers noted that refining the manufacturing process could further improve the device’s performance by reducing imperfections.
Discussion & Takeaways
This research marks a significant advancement in terahertz communications. The ability to efficiently manipulate terahertz waves in a compact device could be crucial for future wireless technologies. The wide frequency range of operation provides flexibility for various applications. The researchers suggest their approach could potentially be scaled to even higher frequencies, opening up new possibilities in fields like sensing and imaging.
“Within a decade, we foresee widespread adoption and integration of these terahertz technologies across various industries, revolutionizing fields such as telecommunications, imaging, radar, and the Internet of things,” Prof. Withayachumnankul predicts.
Funding & Disclosures
This research was supported by grants from the Australian Research Council and Japan’s National Institute of Information and Communications Technology. The team also received funding from the Core Research for Evolutional Science and Technology program of the Japan Science and Technology Agency. The authors declared no conflicts of interest related to this work.
Among the changes is a new identity proofing option that doesn’t use biometrics like facial recognition.
NIST has a new draft out of a long-awaited update to its digital identity guidelines.
Published Wednesday, the standards contain “foundational process and technical requirements” for digital identity, Ryan Galluzzo, the digital identity program lead for NIST’s Applied Cybersecurity Division, told Nextgov/FCW. That means verifying that someone is who they say they are online.
The new draft features changes to make room for passkeys and mobile drivers licenses, new options for identifying people without using biometrics like facial recognition and a more detailed focus on metrics and continuous evaluation of systems.
The Office of Management and Budget directs agencies to follow these guidelines, meaning that changes may be felt by millions of Americans that log in online to access government benefits and services. The current iteration dates to 2017.
NIST published a draft update in late 2022 and subsequently received about 4,000 line items of feedback, said Galluzzo. NIST is accepting comments on this latest iteration through October 7.
The hope is to get the final version out sometime next year, although that timeline is dependent on the amount of feedback the agency receives, he said.
Among the changes are new details about how to leverage user-controlled digital wallets that store mobile drivers licenses to prove identity online. NIST also added an existing supplement around synchable authenticators, or passkeys, issued earlier this year into the digital identity guidelines.
The latest draft also features more changes around facial recognition and biometrics, which have often been the subject of debate and controversy in government services bound to these guidelines.
Changes meant to offer an identity proofing option that doesn’t involve biometrics for low-risk situations comprised a big focus of the 2022 draft update.
NIST tinkered with that baseline further in the latest draft after it got feedback that the standard still had “a lot of friction for lower- to moderate-risk applications,” said Galluzzo.
NIST also added a new way to reach identity assurance level 2 — an identity proofing baseline that is currently met commonly online using tools like facial recognition — without those biometrics.
Instead, organizations could now send an enrollment code to a physical postal address that can be verified with an authoritative source, said Galluzzo, who added that the authors also tried to streamline the section to make it clear what the options are, with and without biometrics.
The latest draft also has an updated section explaining four ways to do identity proofing, including remote and in-person options with or without supervision or help from an employee.
Other changes in the latest draft include specific recommended metrics for agencies to use for the continuous evaluation of their systems.
That focus aligns with the addition of performance requirements for biometrics added in the 2022 draft, as well as a push for agencies to look at the potential impact of their identity systems on the communities and individuals using them, as well as their agencies’ mission delivery.
“Our assurance levels are baselines, and you should be… focusing on the effectiveness of the controls you have in place because you might need to modify things to support your risk threats profile or to support your user groups,” he said.
The latest draft also features new redress requirements for when things go wrong.
“You can’t simply say, ‘Look, that’s a problem with our third-party vendor,’” said Galluzzo.
Big-picture, weighing the views of stakeholders that prioritize security and others focused on accessibility is difficult, he said.
“Being able to take those two points of view and balance those into something that is viable, realistic and implementable is where the biggest challenge is with identity across the board,” said Galluzzo.
That tension came into the forefront during the pandemic, when many government services were pushed online.
In the unemployment insurance system, for example, many states installed identity proofing reliant on facial recognition when they faced schemes from fraudsters.
The existing NIST guidance doesn’t offer many alternatives to biometrics for digital identity proofing, but facial recognition has increasingly come under scrutiny in regards to equity, privacy and other concerns.
The Labor Department’s own Inspector General warned of “urgent equity and security concerns” around the use of facial recognition in a 2023 memo, pointing to testing done by NIST in 2019 that found “nearly all” algorithms have performance disparities based on demographics like race and gender, as a NIST official told lawmakers last year. That varies depending on the algorithm, and the technology has also generally improved since 2019.
Jason Miller, deputy director for management at the Office of Management and Budget, said in a statement that “NIST has developed strong and fair draft guidelines that, when finalized, will help federal agencies better defend against evolving threats while providing critical benefits and services to the American people, particularly those that need them most.”
The White House itself has also been handling these tensions as it’s been crafting a long-awaited executive ordermeant to address fraud in public benefits.
“Everyone should be able to lawfully access government services, regardless of their chosen methods of identification,” said NIST Director Laurie Locascio in a statement. “These improved guidelines are intended to help organizations of all kinds manage risk and prevent fraud while ensuring that digital services are lawfully accessible to all.”
One of the aspects of artificial intelligence (AI) that makes it difficult to regulate is algorithmic opacity, or the potential lack of understanding of exactly how an algorithm may use, collect, or alter data or make decisions based on those data.
Potential regulatory solutions include (1) minimizing the data that companies can collect and use and (2) mandating audits and disclosures of the use of AI.
A key issue is finding the right balance of regulation and innovation. Focusing on the data used in AI, the purposes of the use of AI, and the outcomes of the use of the AI can potentially alleviate this concern.
The European Union (EU)’s Artificial Intelligence (AI) Act is a landmark piece of legislation that lays out a detailed and wide-ranging framework for the comprehensive regulation of AI deployment in the European Union covering the development, testing, and use of AI.[1]This is one of several reports intended to serve as succinct snapshots of a variety of interconnected subjects that are central to AI governance discussions in the United States, in the European Union, and globally. This report, which focuses on AI impacts on privacy law, is not intended to provide a comprehensive analysis but rather to spark dialogue among stakeholders on specific facets of AI governance, especially as AI applications proliferate worldwide and complex governance debates persist. Although we refrain from offering definitive recommendations, we explore a set of priority options that the United States could consider in relation to different aspects of AI governance in light of the EU AI Act.
AI promises to usher in an era of rapid technological evolution that could affect virtually every aspect of society in both positive and negative manners. The beneficial features of AI require the collection, processing, and interpretation of large amounts of data—including personal and sensitive data. As a result, questions surrounding data protection and privacy rights have surfaced in the public discourse.
Privacy protection plays a pivotal role in individuals maintaining control over their personal information and in agencies safeguarding individuals’ sensitive information and preventing the fraudulent use and unauthorized access of individuals’ data. Despite this, the United States lacks a comprehensive federal statutory or regulatory framework governing data rights, privacy, and protection. Currently, the only consumer protections that exist are state-specific privacy laws and federal laws that offer limited protection in specific contexts, such as health information. The fragmented nature of a state-by-state data rights regime can make compliance unduly difficult and can stifle innovation.[2] For this reason, President Joe Biden called on Congress to pass bipartisan legislation “to better protect Americans’ privacy, including from the risks posed by AI.”[3]
There have been several attempts at comprehensive federal privacy legislation, including the American Privacy Rights Act (APRA), which aims to protect the collection, transfer and use of Americans’ data in most circumstances.[4] Although some data privacy issues could be addressed in legislation, there would still be gaps in data protection because of AI’s unique attributes. In this report, we identify those gaps and highlight possible options to address them.
Nature of the Problem: Privacy Concerns Specific to AI
From a data privacy perspective, one of AI’s most concerning aspects is the potential lack of understanding of exactly how an algorithm may use, collect, or alter data or make decisions based on those data.[5] This potential lack of understanding is referred to as algorithmic opacity, and it can result from the inherent complexity of the algorithm, the purposeful concealment of a company using trade secrets law to protect its algorithm, or the use of machine learning to build the algorithm—in which case, even the algorithm’s creators may not be able predict how it will perform.[6] Algorithmic opacity can make it difficult or impossible to see how data inputs are being transformed into data or decision outputs, limiting the ability to inspect or regulate the AI in question.[7]
There are other general privacy concerns that take on unique aspects related to AI or that are further exaggerated by the unique characteristics of AI:[8]
Data repurposing refers to data being used beyond their intended and stated purpose and without the data subject’s knowledge or consent. In a general privacy context, an example would be when contact information collected for a purchase receipt is later used for marketing purposes for a different product. In an AI context, data repurposing can occur when biographical data collected from one person are fed into an algorithm that then learns from the patterns associated with that person’s data. For example, the stimulus package in the wake of the 2008 financial crisis included funding for digitization of health care records for the purpose of easily transferring health care data between health care providers, a benefit for the individual patient.[9]However, hospitals and insurers might use medical algorithms to determine individual health risks and eligibility to receive medical treatment, a purpose not originally intended.[10] A particular problem with data privacy in AI use is that existing data sets collected over the past decade may be used and recombined in ways that could not be reasonably foreseen and incorporated into decisionmaking at the time of collection.[11]
Data spillovers occur when data are collected on individuals who were not intended to be included when the data were collected. An example would be the use of AI to analyze a photograph taken of a consenting individual that also includes others who have not consented. Another example may be the relatives of a person who uploads their genetic data profile to a genetic data aggregator, such as 23andMe.
Data persistence refers to data existing longer than reasonably anticipated at the time of collection and possibly beyond the lifespan of the human subjects who created the data or consented to their use. This issue is caused by the fact that once digital data are created, they are difficult to delete completely, especially if the data are incorporated into an AI algorithm and repackaged or repurposed.[12] As the costs of storing and maintaining data have plummeted over the past decade, even the smallest organizations have the ability to indefinitely store data, adding to the occurrence of data persistence issues.[13] This is concerning from a privacy point of view because privacy preferences typically change over time. For example, individuals tend to become more conservative with their privacy preferences as they grow older.[14]With the issue of data persistence, consent given in early adulthood may lead to data being used over and after the course of the individual’s lifetime.
Possible Options to Address AI’s Unique Privacy Risks
In most comprehensive data privacy proposals, the foundation is typically set by providing individuals with fundamental rights over their data and privacy, from which the remaining system unfolds. The EU General Data Protection Regulation (GDPR) and the California Consumer Privacy Act—two notable comprehensive data privacy regimes—both begin with a general guarantee of fundamental rights protection, including rights to privacy, personal data protection, and nondiscrimination.[15] Specifically, the data protection rights include the right to know what data have been collected, the right to know what data have been shared with third parties and with whom, the right to have data deleted, and the right to have incorrect data corrected.
Prior to the proliferation of AI, good data management systems and procedures could make compliance with these rights attainable. However, the AI privacy concerns listed above render full compliance more difficult. Specifically, algorithmic opacity makes it difficult to know how data are being used, so it becomes more difficult to know when data have been shared or whether they have been completely deleted. Data repurposing makes it difficult to know how data have been used and with whom they have been shared. Data spillover makes it difficult to know exactly what data have been collected on a particular individual. These issues, along with the plummeting cost of data storage, exacerbate data persistence, or the maintenance of data beyond their intended use or purpose.
The unique problems associated with AI give rise to several options for resolving or mitigating these issues. Here, we provide summaries of these options and examples of how they have been enacted within other regulatory regimes.
Data Minimization and Limitation
Data minimization refers to the practice of limiting the collection of personal information to that which is directly relevant and necessary to accomplish specific and narrowly identified goals.[16]This stands in contrast to the approach used by many companies today, which is to collect as much information as possible. Under the tenets of data minimization, the use of any data would be legally limited only to the use identified at the time of collection.[17] Data minimization is also a key privacy principle in reducing the risks associated with privacy breaches.
Several privacy frameworks incorporate the concept of data minimization. The proposed APRA includes data minimization standards that prevent collection, processing, retention, or transfer of data “beyond what is necessary, proportionate, or limited to provide or maintain” a product or service.[18]The EU GDPR notes that “[p]ersonal data should be adequate, relevant and limited to what is necessary for the purposes for which they are processed.”[19]The EU AI Act also reaffirms that the principles of data minimization and data protection apply to AI systems throughout their entire life cycles whenever personal data are processed.[20] The EU AI Act also imposes strict rules on collecting and using biometric data. For example, it prohibits AI systems that “create or expand facial recognition databases through the untargeted scraping of facial images from the internet or CCTV [closed-circuit television] footage.”[21]
As another example of a way to incorporate data minimization, APRA would establish a duty of loyalty, which prohibits covered entities from collecting, using, or transferring covered data beyond what is reasonably necessary to provide the service requested by the individual, unless the use is one of the explicitly permissible purposes listed in the bill.[22] Among other things, the bill would require covered entities to get a consumer’s affirmative, express consent before transferring their sensitive covered data to a third party, unless a specific exception applies.
Algorithmic Impact Assessments for Public Use
Algorithmic impact assessments (AIAs) are intended to require accountability for organizations that deploy automated decisionmaking systems.[23] AIAs counter the problem of algorithmic opacity by surfacing potential harms caused by the use of AI in decisionmaking and call for organizations to take practical steps to mitigate any identifiable harms.[24] An AIA would mandate disclosure of proposed and existing AI-based decision systems, including their purpose, reach, and potential impacts on communities, before such algorithms were deployed.[25] When applied to public organizations, AIAs shed light on the use of the algorithm and help avoid political backlash regarding systems that the public does not trust.[26]
APRA includes a requirement that large data holders conduct AIAs that weigh the benefits of their privacy practices against any adverse consequences.[27] These assessments would describe the entity’s steps to mitigate potential harms resulting from its algorithms, among other requirements. The bill requires large data holders to submit these AIAs to the Federal Trade Commission and make them available to Congress on request. Similarly, the EU GDPR mandates data protection impact assessments (PIAs) to highlight the risks of automated systems used to evaluate people based on their personal data.[28] The AIAs and the PIAs are similar, but they differ substantially in their scope: While PIAs focus on rights and freedoms of data subjects affected by the processing of their personal data, AIAs address risks posed by the use of nonpersonal data.[29] The EU AI Act further expands the notion of impact assessment to encompass broader risks to fundamental rights not covered under the GDPR. Specifically, the EU AI Act mandates that bodies governed by public law, private providers of public services (such as education, health care, social services, housing, and administration of justice), and banking and insurance service providers using AI systems must conduct fundamental rights impact assessments before deploying high-risk AI systems.[30]
Algorithmic Audits
Whereas the AIA assesses impact, an algorithmic audit is “a structured assessment of an AI system to ensure it aligns with predefined objectives, standards, and legal requirements.”[31] In such an audit, the system’s design, inputs, outputs, use cases, and overall performance are examined thoroughly to identify any gaps, flaws, or risks.[32] A proper algorithmic audit includes definite and clear audit objectives, such as verifying performance and accuracy, as well as standardized metrics and benchmarks to evaluate a system’s performance.[33] In the context of privacy, an audit can confirm that data are being used within the context of the subjects’ consent and the tenets of applicable regulations.[34]
During the initial stage of an audit, the system is documented, and processes are designated as low, medium, or high risk depending on such factors as the context in which the system is used and the type of data it relies on.[35] After documentation, the system is assessed on its efficacy, bias, transparency, and privacy protection.[36]Then, the outcomes of the assessment are used to identify actions that can lower any identified risks. Such actions may be technical or nontechnical in nature.[37]
This notion of algorithmic audit is embedded in the conformity assessment foreseen by the EU AI Act.[38] The conformity assessment is a formal process in which a provider of a high-risk AI system has to demonstrate compliance with requirements for such systems, including those concerning data and data governance. Specifically, the EU AI Act requires that training, validation, and testing datasets are subject to data governance and management practices appropriate for the system’s intended purpose. In the case of personal data, those practices should concern the original purpose and origin as well as data collection processes.[39] Upon completion of the assessment, the entity is required to draft written EU Declarations of Conformity for each relevant system, and these must be maintained for ten years.[40]
Mandatory Disclosures
Mandatory AI disclosures are another option to address privacy concerns, such as by requiring that uses of AI should be disclosed to the public by the organization employing the technology.[41] For example, the EU AI Act mandates AI-generated content labeling. Furthermore, the EU AI Act requires disclosure when people are exposed to AI systems that can assign them to groups or infer their emotions or intentions based on biometric data (unless the system is intended for law enforcement purposes).[42] Legislation introduced in the United States called the AI Labeling Act of 2023 would require that companies properly label and disclose when they use an AI-generated product, such as a chatbot.[43] The proposed legislation also calls for generative AI system developers to implement reasonable procedures to prevent downstream use of those systems without proper disclosure.[44]
Considerations for Policymakers
As noted in the previous section, some of these options have been proposed in the United States. Others have been applied in other countries. A key issue is finding the right balance of regulation and innovation. Industry and wider stakeholder input into regulation may help alleviate concerns that regulations could throttle the development and implementation of the benefits offered by AI. Seemingly, the EU AI Act takes this approach for drafting the codes of practice for general-purpose AI models: The EU AI Office is expected to invite stakeholders—especially developers of models—to participate in drafting the codes, which will operationalize many EU AI Act requirements.[45] The EU AI Act also has explicit provisions for supporting innovation, especially among small and medium-sized enterprises, including start-ups.[46] For example, the law introduces regulatory sandboxes: controlled testing and experimentation environments under strict regulatory oversight. The specific purpose of these sandboxes is to foster AI innovation by providing frameworks to develop, train, validate, and test AI systems in a way that ensures compliance with the EU AI Act, thus alleviating legal uncertainty for providers.[47]
AI technology is an umbrella term used for various types of technology, from generative AI used to power chatbots to neural networks that spot potential fraud on credit cards.[48] Moreover, AI technology is advancing rapidly and will continue to change dramatically over the coming years. For this reason, rather than focusing on the details of the underlying technology, legislators might consider regulating the outcomes of the algorithms. Such regulatory resiliency may be accomplished by applying the rules to the data that go into the algorithms, the purposes for which those data are used, and the outcomes that are generated.[49]
Tifani Sedek is a professor at the University of Michigan Law School. From RAND, Karlyn D. Stanley is a senior policy researcher, Gregory Smith is a policy analyst, Krystyna Marcinek is an associate policy researcher, Paul Cormarie is a policy analyst, and Salil Gunashekar is an associate director at RAND Europe.
Notes
[1] European Union, “Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence and amending Regulations (EC) No 300/2008, (EU) No 167/2013, (EU) No 168/2013, (EU) 2018/858, (EU) 2018/1139 and (EU) 2019/2144 and Directives 2014/90/EU, (EU) 2016/797 and (EU) 2020/1828 (Artificial Intelligence Act) Text with EEA relevance,” June 13, 2024. Hereafter cited as the EU AI Act, this legislation was adopted by the European Parliament in March 2024 and approved by the European Council in June 2024. As of July 16, 2024, all text cited in this report related to the EU AI Act can be found at https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJ:L_202401689#d1e5435-1-1
[2] Brenna Goth, “Varied Data Privacy Laws Across States Raise Compliance Stakes,” Bloomberg Law, October 11, 2023.
[3] White House, “FACT SHEET: President Biden Issues Executive Order on Safe, Secure, and Trustworthy Artificial Intelligence,” October 30, 2023.
[5] Jenna Burrell, “How the Machine Thinks: Understanding Opacity in Machine Learning Algorithms,” Big Data & Society, Vol. 3, No. 1, June 2016.
[6] Sylvia Lu, “Data Privacy, Human Rights, and Algorithmic Opacity,” California Law Review, Vol. 110, 2022.
[7] Markus Langer, “Introducing a Multi-Stakeholder Perspective on Opacity, Transparency and Strategies to Reduce Opacity in Algorithm-Based Human Resource Management,” Human Resource Management Review, Vol. 33, No. 1, March 2023.
[8] Catherine Tucker, “Privacy, Algorithms, and Artificial Intelligence,” in Ajay Agrawal, Joshua Gans, and Avi Goldfarb, eds., The Economics of Artificial Intelligence: An Agenda, University of Chicago Press, May 2019, p. 423.
[9] Public Law 110-185, Economic Stimulus Act of 2008, February 13, 2008; Sara Green, Line Hillersdal, Jette Holt, Klaus Hoeyer, and Sarah Wadmann, “The Practical Ethics of Repurposing Health Data: How to Acknowledge Invisible Data Work and the Need for Prioritization,” Medicine, Health Care and Philosophy, Vol. 26, No. 1, 2023.
[10] Starre Vartan, “Racial Bias Found in a Major Health Care Risk Algorithm,” Scientific American, October 24, 2019.
[13] Stephen Pastis, “A.I.’s Un-Learning Problem: Researchers Say It’s Virtually Impossible to Make an A.I. Model ‘Forget’ the Things It Learns from Private User Data,” Forbes, August 30, 2023.
[15] European Union, General Data Protection Regulation, May 25, 2018 (hereafter, GDPR, 2018); California Civil Code, Division 3, Obligations; Part 4, Obligations Arising from Particular Transactions; Title 1.81.5, California Consumer Privacy Act of 2018. Fabienne Ufert, “AI Regulation Through the Lens of Fundamental Rights: How Well Does the GDPR Address the Challenges Posed by AI?” European Papers, September 20, 2020.
[16] White House, Blueprint for an AI Bill of Rights: Making Automated Systems Work for the American People, October 2022, p. 33.
[23] Jacob Metcalf, Emanuel Moss, Elizabeth Anne Watkins, Ranjit Singh, and Madeleine Clare Elish, “Algorithmic Impact Assessments and Accountability: The Co-Construction of Impacts,” paper presented at the ACM Conference on Fairness, Accountability, and Transparency, virtual event, March 3–10, 2021.
[25] Dillon Reisman, Jason Schultz, Kate Crawford, and Meredith Whittaker, Algorithmic Impact Assessments: A Practical Framework for Public Agency Accountability, AI Now Institute, April 2018.
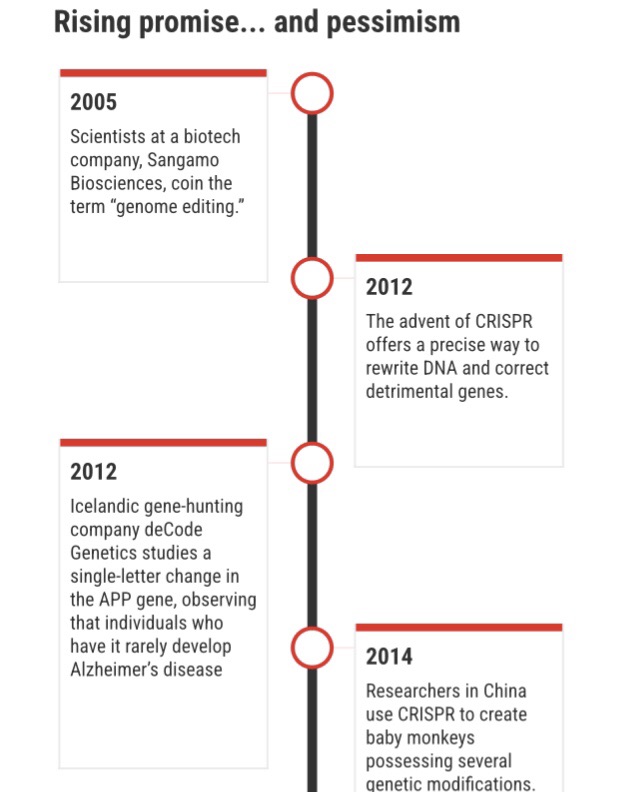
In 2016, I attended a large meeting of journalists in Washington, DC. The keynote speaker was Jennifer Doudna, who just a few years before had co-invented CRISPR, a revolutionary method of changing genes that was sweeping across biology labs because it was so easy to use. With its discovery, Doudna explained, humanity had achieved the ability to change its own fundamental molecular nature. And that capability came with both possibility and danger. One of her biggest fears, she said, was “waking up one morning and reading about the first CRISPR baby”—a child with deliberately altered genes baked in from the start.
As a journalist specializing in genetic engineering—the weirder the better—I had a different fear. A CRISPR baby would be a story of the century, and I worried some other journalist would get the scoop. Gene editing had become the biggest subject on the biotech beat, and once a team in China had altered the DNA of a monkey to introduce customized mutations, it seemed obvious that further envelope-pushing wasn’t far off.
If anyone did create an edited baby, it would raise moral and ethical issues, among the profoundest of which, Doudna had told me, was that doing so would be “changing human evolution.” Any gene alterations made to an embryo that successfully developed into a baby would get passed on to any children of its own, via what’s known as the germline. What kind of scientist would be bold enough to try that?
Two years and nearly 8,000 miles in an airplane seat later, I found the answer. At a hotel in Guangzhou, China, I joined a documentary film crew for a meeting with a biophysicist named He Jiankui, who appeared with a retinue of advisors. During the meeting, He was immensely gregarious and spoke excitedly about his research on embryos of mice, monkeys, and humans, and about his eventual plans to improve human health by adding beneficial genes to people’s bodies from birth. Still imagining that such a step must lie at least some way off, I asked if the technology was truly ready for such an undertaking.
“Ready,” He said. Then, after a laden pause: “Almost ready.”
Why wait 100,000 years for natural selection to do its job? For a few hundred dollars in chemicals, you could try to install these changes in an embryo in 10 minutes.
Four weeks later, I learned that he’d already done it, when I found data that He had placed online describing the genetic profiles of two gene-edited human fetuses—that is, ”CRISPR babies” in gestation—as well an explanation of his plan, which was to create humans immune to HIV. He had targeted a gene called CCR5, which in some people has a variation known to protect against HIV infection. It’s rare for numbers in a spreadsheet to make the hair on your arms stand up, although maybe some climatologists feel the same way seeing the latest Arctic temperatures. It appeared that something historic—and frightening—had already happened. In our storybreaking the news that same day, I ventured that the birth of genetically tailored humans would be something between a medical breakthrough and the start of a slippery slope of human enhancement.
For his actions, He was later sentenced to three years in prison, and his scientific practices were roundly excoriated. The edits he made, on what proved to be twin girls (and a third baby, revealed later), had in fact been carelessly imposed, almost in an out-of-control fashion, according to his own data. And I was among a flock of critics—in the media and academia—who would subject He and his circle of advisors to Promethean-level torment via a daily stream of articles and exposés. Just this spring, Fyodor Urnov, a gene-editing specialist at the University of California, Berkeley, lashed out on X, calling He a scientific “pyromaniac” and comparing him to a Balrog, a demon from J.R.R. Tolkien’s TheLord of the Rings. It could seem as if He’s crime wasn’t just medical wrongdoing but daring to take the wheel of the very processes that brought you, me, and him into being.
He Jiankui’s manuscript shows how he ignored ethical and scientific norms in creating the gene-edited twins Lulu and Nana.
Futurists who write about the destiny of humankind have imagined all sorts of changes. We’ll all be given auxiliary chromosomes loaded with genetic goodies, or maybe we’ll march through life as a member of a pod of identical clones. Perhaps sex will become outdated as we reproduce exclusively through our stem cells. Or human colonists on another planet will be isolated so long that they become their own species. The thing about He’s idea, though, is that he drew it from scientific realities close at hand. Just as some gene mutations cause awful, rare diseases, others are being discovered that lend a few people the ability to resist common ones, like diabetes, heart disease, Alzheimer’s—and HIV. Such beneficial, superpower-like traits might spread to the rest of humanity, given enough time. But why wait 100,000 years for natural selection to do its job? For a few hundred dollars in chemicals, you could try to install these changes in an embryo in 10 minutes. That is, in theory, the easiest way to go about making such changes—it’s just one cell to start with.
Editing human embryos is restricted in much of the world—and making an edited baby is flatly illegal in most countries surveyed by legal scholars. But advancing technology could render the embryo issue moot. New ways of adding CRISPR to the bodies of people already born—children and adults—could let them easily receive changes as well. Indeed, if you are curious what the human genome could look like in 125 years, it’s possible that many people will be the beneficiaries of multiple rare, but useful, gene mutations currently found in only small segments of the population. These could protect us against common diseases and infections, but eventually they could also yield frank improvements in other traits, such as height, metabolism, or even cognition. These changes would not be passed on genetically to people’s offspring, but if they were widely distributed, they too would become a form of human-directed self-evolution—easily as big a deal as the emergence of computer intelligence or the engineering of the physical world around us.
I was surprised to learn that even as He’s critics take issue with his methods, they see the basic stratagem as inevitable. When I asked Urnov, who helped coin the term “genome editing” in 2005, what the human genome could be like in, say, a century, he readily agreed that improvements using superpower genes will probably be widely introduced into adults—and embryos—as the technology to do so improves. But he warned that he doesn’t necessarily trust humanity to do things the right way. Some groups will probably obtain the health benefits before others. And commercial interests could eventually take the trend in unhelpful directions—much as algorithms keep his students’ noses pasted, unnaturally, to the screens of their mobile phones. “I would say my enthusiasm for what the human genome is going to be in 100 years is tempered by our history of a lack of moderation and wisdom,” he said. “You don’t need to be Aldous Huxley to start writing dystopias.”
Editing early
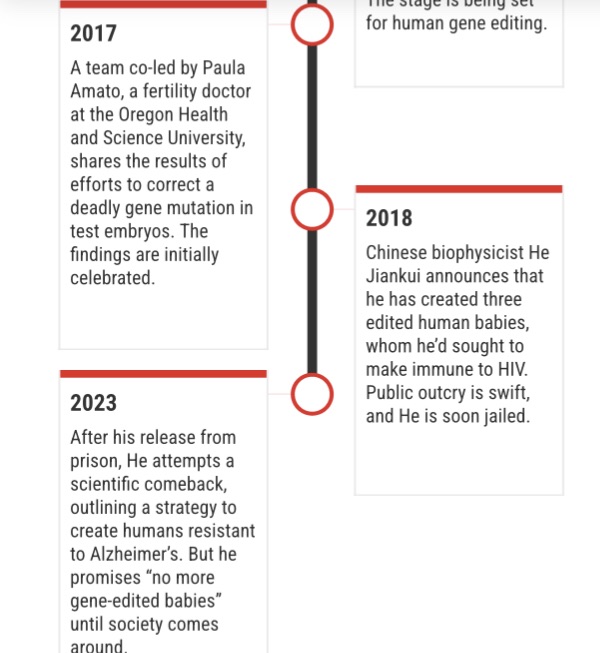
At around 10 p.m. Beijing time, He’s face flicked into view over the Tencent videoconferencing app. It was May 2024, nearly six years after I had first interviewed him, and he appeared in a loftlike space with a soaring ceiling and a wide-screen TV on a wall. Urnov had warned me not to speak with He, since it would be like asking “Bernie Madoff to opine about ethical investing.” But I wanted to speak to him, because he’s still one of the few scientists willing to promote the idea of broad improvements to humanity’s genes.
Of course, it’s his fault everyone is so down on the idea. After his experiment, China formally made “implantation” of gene-edited human embryos into the uterus a crime. Funding sources evaporated. “He created this blowback, and it brought to a halt many people’s research. And there were not many to begin with,” says Paula Amato, a fertility doctor at Oregon Health and Science University who co-leads one of only two US teams that have ever reported editing human embryos in a lab. “And the publicity—nobody wants to be associated with something that is considered scandalous or eugenic.”
The US government just hired a researcher who thinks we can beat aging with fresh cloned bodies and brain updates.
After leaving prison in 2022, the Chinese biophysicist surprised nearly everyone by seeking to make a scientific comeback. At first, he floated ideas for DNA-based data storage and “affordable” cures for children who have muscular dystrophy. But then, in summer 2023, he posted to social media that he intended to return to research on how to change embryos with gene editing, with the caveat that “no human embryo will be implanted for pregnancy.” His new interest was a gene called APP, or amyloid precursor protein. It’s known that people who possess a very rare version, or “allele,” of this gene almost never develop Alzheimer’s disease.
In our video call, He said the APP gene is the main focus of his research now and that he is determining how to change it. The work, he says, is not being conducted on human embryos, but rather on mice and on kidney cells, using an updated form of CRISPR called base editing, which can flip individual letters of DNA without breaking the molecule.
“We just want to expand the protective allele from small amounts of lucky people to maybe most people,” He told me. And if you made the adjustment at the moment an egg is fertilized, you would only have to change one cell in order for the change to take hold in the embryo and, eventually, everywhere in a person’s brain. Trying to edit an individual’s brain after birth “is as hard a delivering a person to the moon,” He said. “But if you deliver gene editing to an embryo, it’s as easy as driving home.”
In the future, He said, human embryos will “obviously” be corrected for all severe genetic diseases. But they will also receive “a panel” of “perhaps 20 or 30” edits to improve health. (If you’ve seen the sci-fi film Gattaca, it takes place in a world where such touch-ups are routine—leading to stigmatization of the movie’s hero, a would-be space pilot who lacks them.) One of these would be to install the APP variant, which involves changing a single letter of DNA. Others would protect against diabetes, and maybe cancer and heart disease. He calls these proposed edits “genetic vaccines” and believes people in the future “won’t have to worry” about many of the things most likely to kill them today.
Is He the person who will bring about this future? Last year, in what seemed to be a step toward his rehabilitation, he got a job heading a gene center at Wuchang University of Technology, a third-tier institution in Wuhan. But He said during our call that he had already left the position. He didn’t say what had caused the split but mentioned that a flurry of press coverage had “made people feel pressured.” One item, in a French financial paper, Les Echos, was titled “GMO babies: The secrets of a Chinese Frankenstein.” Now he carries out research at his own private lab, he says, with funding from Chinese and American supporters. He has early plans for a startup company. Could he tell me names and locations? “Of course not,” he said with a chuckle.
It could be there is no lab, just a concept. But it’s a concept that is hard to dismiss. Would you give your child a gene tweak—a swap of a single genetic letter among the 3 billion that run the length of the genome—to prevent Alzheimer’s, the mind thief that’s the seventh-leading cause of death in the US? Polls find that the American public is about evenly split on the ethics of adding disease resistance traits to embryos. A sizable minority, though, would go further. A 2023 survey published in Science found that nearly 30% of people would edit an embryo if it enhanced the resulting child’s chance of attending a top-ranked college.
The benefits of the genetic variant He claims to be working with were discovered by the Icelandic gene-hunting company deCode Genetics. Twenty-six years ago, in 1998, its founder, a doctor named Kári Stefánsson, got the green light to obtain medical records and DNA from Iceland’s citizens, allowing deCode to amass one of the first large national gene databases. Several similar large biobanks now operate, including one in the United Kingdom, which recently finished sequencing the genomes of 500,000 volunteers. These biobanks make it possible to do computerized searches to find relationships between people’s genetic makeup and real-life differences like how long they live, what diseases they get, and even how much beer they drink. The result is a statistical index of how strongly every possible difference in human DNA affects every trait that can be measured.
In 2012, deCode’s geneticists used the technique to study a tiny change in the APP gene and determined that the individuals who had it rarely developed Alzheimer’s. They otherwise seemed healthy. In fact, they seemed particularly sharp in old age and appeared to live longer, too. Lab tests confirmed that the change reduces the production of brain plaques, the abnormal clumps of protein that are a hallmark of the disease.
“This is beginning to be about the essence of who we are as a species.”Kári Stefánsson, founder and CEO, deCode genetics
One way evolution works is when a small change or error appears in one baby’s DNA. If the change helps that person survive and reproduce, it will tend to become more common in the species—eventually, over many generations, even universal. This process is slow, but it’s visible to science. In 2018, for example, researchers determined that the Bajau, a group indigenous to Indonesia whose members collect food by diving, possess genetic changes associated with bigger spleens. This allows them to store more oxygenated red blood cells—an advantage in their lives.
Sickle-cell disease is the first illness to be beaten by CRISPR, but the new treatment comes with an expected price tag of $2 to $3 million.
Even though the variation in the APP gene seems hugely beneficial, it’s a change that benefits old people, way past their reproductive years. So it’s not the kind of advantage natural selection can readily act on. But we could act on it. That is what technology-assisted evolution would look like—seizing on a variation we think is useful and spreading it. “The way, probably, that enhancement will be done will be to look at the population, look at people who have enhanced capabilities—whatever those might be,” the Israeli medical geneticist Ephrat Levy-Lahad said during a gene-editing summit last year. “You are going to be using variations that already exist in the population that you already have information on.”
One advantage of zeroing in on advantageous DNA changes that already exist in the population is that their effects are pretested. The people located by deCode were in their 80s and 90s. There didn’t seem to be anything different about them—except their unusually clear minds. Their lives—as seen from the computer screens of deCode’s biobank—served as a kind of long-term natural experiment. Yet scientists could not be fully confident placing this variant into an embryo, since the benefits or downsides might differ depending on what other genetic factors are already present, especially other Alzheimer’s risk genes. And it would be difficult to run a study to see what happens. In the case of APP, it would take 70 years for the final evidence to emerge. By that time, the scientists involved would all be dead.
When I spoke with Stefánsson last year, he made the case both for and against altering genomes with “rare variants of large effect,” like the change in APP. “All of us would like to keep our marbles until we die. There is no question about it. And if you could, by pushing a button, install the kind of protection people with this mutation have, that would be desirable,” he said. But even if the technology to make this edit before birth exists, he says, the risks of doing so seem almost impossible to gauge: “You are not just affecting the person, but all their descendants forever. These are mutations that would allow for further selection and further evolution, so this is beginning to be about the essence of who we are as a species.”
Editing everyone
Some genetic engineers believe that editing embryos, though in theory easy to do, will always be held back by these grave uncertainties. Instead, they say, DNA editing in living adults could become easy enough to be used not only to correct rare diseases but to add enhanced capabilities to those who seek them. If that happens, editing for improvement could spread just as quickly as any consumer technology or medical fad. “I don’t think it’s going to be germline,” says George Church, a Harvard geneticist often sought out for his prognostications. “The 8 billion of us who are alive kind of constitute the marketplace.” For several years, Church has been circulating what he calls “my famous, or infamous, table of enhancements.” It’s a tally of gene variants that lend people superpowers, including APP and another that leads to extra-hard bones, which was found in a family that complained of not being able to stay afloat in swimming pools. The table is infamous because some believe Church’s inclusion of the HIV-protective CCR5 variant inspired He’s effort to edit it into the CRISPR babies.
Research roadblocks and political debates have delayed progress—but scientists are inching closer to delivering a cure.
Church believes novel gene treatments for very serious diseases, once proven, will start leading the way toward enhancements and improvements to people already born. “You’d constantly be tweaking and getting feedback,” he says—something that’s hard to do with the germline, since humans take so long to grow up. Changes to adult bodies would not be passed down, but Church thinks they could easily count as a form of heredity. He notes that railroads, eyeglasses, cell phones—and the knowledge of how to make and use all these technologies—are already all transmitted between generations. “We’re clearly inheriting even things that are inorganic,” he says.
The biotechnology industry is already finding ways to emulate the effects of rare, beneficial variants. A new category of heart drugs, for instance, mimics the effect of a rare variation in a gene, called PCSK9, that helps maintain cholesterol levels. The variation, initially discovered in a few people in the US and Zimbabwe, blocks the gene’s activity and gives them ultra-low cholesterol levels for life. The drugs, taken every few weeks or months, work by blocking the PCSK9 protein. One biotech company, though, has started trying to edit the DNA of people’s liver cells (the site of cholesterol metabolism) to introduce the same effect permanently.
For now, gene editing of adult bodies is still challenging and is held back by the difficulty of “delivering” the CRISPR instructions to thousands, or even billions of cells—often using viruses to carry the payloads. Organs like the brain and muscles are hard to access, and the treatments can be ordeals. Fatalities in studies aren’t unheard-of. But biotech companies are pouring dollars into new, sleeker ways to deliver CRISPR to hard-to-reach places. Some are designing special viruses that can home in on specific types of cells. Others are adopting nanoparticles similar to those used in the covid-19 vaccines, with the idea of introducing editors easily, and cheaply, via a shot in the arm.
At the Innovative Genomics Institute, a center established by Doudna in Berkeley, California, researchers anticipate that as delivery improves, they will be able to create a kind of CRISPR conveyor belt that, with a few clicks of a mouse, allows doctors to design gene-editing treatments for any serious inherited condition that afflicts children, including immune deficiencies so uncommon that no company will take them on. “This is the trend in my field. We can capitalize on human genetics quite quickly, and the scope of the editable human will rapidly expand,” says Urnov, who works at the institute. “We know that already, today—and forget 2124, this is in 2024—we can build enough CRISPR for the entire planet. I really, really think that [this idea of] gene editing in a syringe will grow. And as it does, we’re going to start to face very clearly the question of how we equitably distribute these resources.”
For now, gene-editing interventions are so complex and costly that only people in wealthy countries are receiving them. The first such therapy to get FDA approval, a treatment for sickle-cell disease, is priced at over $2 million and requires a lengthy hospital stay. Because it’s so difficult to administer, it’s not yet being offered in most of Africa, even though that is where sickle-cell disease is most common. Such disparities are now propelling efforts to greatly simplify gene editing, including a project jointly paid for by the Gates Foundation and the National Institutes of Health that aims to design “shot in the arm” CRISPR, potentially making cures scalable and “accessible to all.” A gene editor built along the lines of the covid-19 vaccine might cost only $1,000. The Gates Foundation sees the technology as a way to widely cure both sickle-cell and HIV—an “unmet need” in Africa, it says. To do that, the foundation is considering introducing into people’s bone marrow the exact HIV-defeating genetic change that He tried to install in embryos.
Then there’s the risk that gene terrorists, or governments, could change people’s DNA without their permission or knowledge.
Scientists can foresee great benefits ahead—even a “final frontier of molecular liberty,” as Christopher Mason, a “space geneticist” at Weill Cornell Medicine in New York, characterizes it. Mason works with newer types of gene editors that can turn genes on or off temporarily. He is using these in his lab to make cells resistant to radiation damage. The technology could be helpful to astronauts or, he says, for a weekend of “recreational genomics”—say, boosting your repair genes in preparation to visit the site of the Chernobyl power plant. The technique is “getting to be, I actually think it is, a euphoric application of genetic technologies,” says Mason. “We can say, hey, find a spot on the genome and flip a light switch on or off on any given gene to control its expression at a whim.”
Easy delivery of gene editors to adult bodies could give rise to policy questions just as urgent as the ones raised by the CRISPR babies. Whether we encourage genetic enhancement—in particular, free-market genome upgrades—is one of them. Several online health influencers have already been touting an unsanctioned gene therapy, offered in Honduras, that its creators claim increases muscle mass. Another risk: If changing people’s DNA gets easy enough, gene terrorists or governments could do it without their permission or knowledge. One genetic treatment for a skin disease, approved in the US last year, is formulated as a cream—the first rub-on gene therapy (though not a gene editor).
Some scientists believe new delivery tools should be kept purposefully complex and cumbersome, so that only experts can use them—a biological version of “security through obscurity.” But that’s not likely to happen. “Building a gene editor to make these changes is no longer, you know, the kind of technology that’s in the realm of 100 people who can do it. This is out there,” says Urnov. “And as delivery improves, I don’t know how we will be able to regulate that.”
In our conversation, Urnov frequently returned to that list of superpowers—genetic variants that make some people outliers in one way or another. There is a mutation that allows people to get by on five hours of sleep a night, with no ill effects. There is a woman in Scotland whose genetic peculiarity means she feels no pain and is perpetually happy, though also forgetful. Then there is Eero Mäntyranta, the cross-country ski champion who won three medals at the 1964 Winter Olympics and who turned out to have an inordinate number of red blood cells thanks to an alteration in a gene called the EPO receptor. It’s basically a blueprint for anyone seeking to join the Enhanced Games, the libertarian plan for a pro-doping international sports competition that critics call “borderline criminal” but which has the backing of billionaire Peter Thiel, among others.
All these are possibilities for the future of the human genome, and we won’t even necessarily need to change embryos to get there. Some researchers even expect that with some yet-to-be-conceived technology, updating a person’s DNA could become as simple as sending a document via Wi-Fi, with today’s viruses or nanoparticles becoming anachronisms like floppy disks. I asked Church for his prediction about where gene-editing technology is going in the long term. “Eventually you’d get shot up with a whole bunch of things when you’re born, or it could even be introduced during pregnancy,” he said. “You’d have all the advantages without the disadvantages of being stuck with heritable changes.”
Whether it’s based on hallucinatory beliefs or not, an artificial-intelligence gold rush has started over the last several months to mine the anticipated business opportunities from generative AI models like ChatGPT. App developers, venture-backed startups, and some of the world’s largest corporations are all scrambling to make sense of the sensational text-generating bot released by OpenAI last November.
You can practically hear the shrieks from corner offices around the world: “What is our ChatGPT play? How do we make money off this?”
But while companies and executives see a clear chance to cash in, the likely impact of the technology on workers and the economy on the whole is far less obvious. Despite their limitations—chief among of them their propensity for making stuff up—ChatGPT and other recently released generative AI models hold the promise of automating all sorts of tasks that were previously thought to be solely in the realm of human creativity and reasoning, from writing to creating graphics to summarizing and analyzing data. That has left economists unsure how jobs and overall productivity might be affected.
For all the amazing advances in AI and other digital tools over the last decade, their record in improving prosperity and spurring widespread economic growth is discouraging. Although a few investors and entrepreneurs have become very rich, most people haven’t benefited. Some have even been automated out of their jobs.
What productivity growth there has been in that time is largely confined to a few sectors, such as information services, and in the US to a few cities—think San Jose, San Francisco, Seattle, and Boston.
Will ChatGPT make the already troubling income and wealth inequality in the US and many other countries even worse? Or could it help? Could it in fact provide a much-needed boost to productivity?
ChatGPT, with its human-like writing abilities, and OpenAI’s other recent release DALL-E 2, which generates images on demand, use large language models trained on huge amounts of data. The same is true of rivals such as Claude from Anthropic and Bard from Google. These so-called foundational models, such as GPT-3.5 from OpenAI, which ChatGPT is based on, or Google’s competing language model LaMDA, which powers Bard, have evolved rapidly in recent years.
They keep getting more powerful: they’re trained on ever more data, and the number of parameters—the variables in the models that get tweaked—is rising dramatically. Earlier this month, OpenAI released its newest version, GPT-4. While OpenAI won’t say exactly how much bigger it is, one can guess; GPT-3, with some 175 billion parameters, was about 100 times larger than GPT-2.
But it was the release of ChatGPT late last year that changed everything for many users. It’s incredibly easy to use and compelling in its ability to rapidly create human-like text, including recipes, workout plans, and—perhaps most surprising—computer code. For many non-experts, including a growing number of entrepreneurs and businesspeople, the user-friendly chat model—less abstract and more practical than the impressive but often esoteric advances that have been brewing in academia and a handful of high-tech companies over the last few years—is clear evidence that the AI revolution has real potential.
Venture capitalists and other investors are pouring billions into companies based on generative AI, and the list of apps and services driven by large language models is growing longer every day.
Will ChatGPT make the already troubling income and wealth inequality in the US and many other countries even worse? Or could it help?
Among the big players, Microsoft has invested a reported $10 billion in OpenAI and its ChatGPT, hoping the technology will bring new life to its long-struggling Bing search engine and fresh capabilities to its Office products. In early March, Salesforce said it will introduce a ChatGPT app in its popular Slackproduct; at the same time, it announced a $250 million fund to invest in generative AI startups. The list goes on, from Coca-Cola to GM. Everyone has a ChatGPT play.
Meanwhile, Google announced it is going to use its new generative AI tools in Gmail, Docs, and some of its other widely used products.
Still, there are no obvious killer apps yet. And as businesses scramble for ways to use the technology, economists say a rare window has opened for rethinking how to get the most benefits from the new generation of AI.
“We’re talking in such a moment because you can touch this technology. Now you can play with it without needing any coding skills. A lot of people can start imagining how this impacts their workflow, their job prospects,” says Katya Klinova, the head of research on AI, labor, and the economy at the Partnership on AI in San Francisco.
“The question is who is going to benefit? And who will be left behind?” says Klinova, who is working on a report outlining the potential job impacts of generative AI and providing recommendations for using it to increase shared prosperity.
The optimistic view: it will prove to be a powerful tool for many workers, improving their capabilities and expertise, while providing a boost to the overall economy. The pessimistic one: companies will simply use it to destroy what once looked like automation-proof jobs, well-paying ones that require creative skills and logical reasoning; a few high-tech companies and tech elites will get even richer, but it will do little for overall economic growth.
Helping the least skilled
The question of ChatGPT’s impact on the workplace isn’t just a theoretical one.
In the most recent analysis, OpenAI’s Tyna Eloundou, Sam Manning, and Pamela Mishkin, with the University of Pennsylvania’s Daniel Rock,found that large language models such as GPT could have some effect on 80% of the US workforce. They further estimated that the AI models, including GPT-4 and other anticipated software tools, would heavily affect 19% of jobs, with at least 50% of the tasks in those jobs “exposed.” In contrast to what we saw in earlier waves of automation, higher-income jobs would be most affected, they suggest. Some of the people whose jobs are most vulnerable: writers, web and digital designers, financial quantitative analysts, and—just in case you were thinking of a career change—blockchain engineers.
Who will control the future of this amazing technology?
“There is no question that [generative AI] is going to be used—it’s not just a novelty,” says David Autor, an MIT labor economist and a leading expert on the impact of technology on jobs. “Law firms are already using it, and that’s just one example. It opens up a range of tasks that can be automated.”
Autor has spent years documenting how advanced digital technologies have destroyed many manufacturing and routine clerical jobs that once paid well. But he says ChatGPT and other examples of generative AI have changed the calculation.
Previously, AI had automated some office work, but it was those rote step-by-step tasks that could be coded for a machine. Now it can perform tasks that we have viewed as creative, such as writing and producing graphics. “It’s pretty apparent to anyone who’s paying attention that generative AI opens the door to computerization of a lot of kinds of tasks that we think of as not easily automated,” he says.
Generative AI could help a wide swath of people gain the skills to compete with those who have more education and expertise.
The worry is not so much that ChatGPT will lead to large-scale unemployment—as Autor points out, there are plenty of jobs in the US—but that companies will replace relatively well-paying white-collar jobs with this new form of automation, sending those workers off to lower-paying service employment while the few who are best able to exploit the new technology reap all the benefits.
In this scenario, tech-savvy workers and companies could quickly take up the AI tools, becoming so much more productive that they dominate their workplaces and their sectors. Those with fewer skills and little technical acumen to begin with would be left further behind.
But Autor also sees a more positive possible outcome: generative AI could help a wide swath of people gain the skills to compete with those who have more education and expertise.
Two MIT economics graduate students, Shakked Noy and Whitney Zhang, ran an experiment involving hundreds of college-educated professionals working in areas like marketing and HR; they asked half to use ChatGPT in their daily tasks and the others not to. ChatGPT raised overall productivity (not too surprisingly), but here’s the really interesting result: the AI tool helped the least skilled and accomplished workers the most, decreasing the performance gap between employees. In other words, the poor writers got much better; the good writers simply got a little faster.
The preliminary findings suggest that ChatGPT and other generative AIs could, in the jargon of economists, “upskill” people who are having trouble finding work. There are lots of experienced workers “lying fallow” after being displaced from office and manufacturing jobs over the last few decades, Autor says. If generative AI can be used as a practical tool to broaden their expertise and provide them with the specialized skills required in areas such as health care or teaching, where there are plenty of jobs, it could revitalize our workforce.
Determining which scenario wins out will require a more deliberate effort to think about how we want to exploit the technology.
“I don’t think we should take it as the technology is loose on the world and we must adapt to it. Because it’s in the process of being created, it can be used and developed in a variety of ways,” says Autor. “It’s hard to overstate the importance of designing what it’s there for.”
Simply put, we are at a juncture where either less-skilled workers will increasingly be able to take on what is now thought of as knowledge work, or the most talented knowledge workers will radically scale up their existing advantages over everyone else. Which outcome we get depends largely on how employers implement tools like ChatGPT. But the more hopeful option is well within our reach.
The pursuit of human-like capabilities, Brynjolfsson argued, has led to technologies that simply replace people with machines, driving down wages and exacerbating inequality of wealth and income. It is, he wrote, “the single biggest explanation” for the rising concentration of wealth.
Erik Brynjolfsson NEILSON BARNARD/GETTY IMAGES
A year later, he says ChatGPT, with its human-sounding outputs, “is like the poster child for what I warned about”: it has “turbocharged” the discussion around how the new technologies can be used to give people new abilities rather than simply replacing them.
Despite his worries that AI developers will continue to blindly outdo each other in mimicking human-like capabilities in their creations, Brynjolfsson, the director of the Stanford Digital Economy Lab, is generally a techno-optimist when it comes to artificial intelligence. Two years ago, he predicted a productivity boom from AI and other digital technologies, and these days he’s bullish on the impact of the new AI models.
Much of Brynjolfsson’s optimism comes from the conviction that businesses could greatly benefit from using generative AI such as ChatGPT to expand their offerings and improve the productivity of their workforce. “It’s a great creativity tool. It’s great at helping you to do novel things. It’s not simply doing the same thing cheaper,” says Brynjolfsson. As long as companies and developers can “stay away from the mentality of thinking that humans aren’t needed,” he says, “it’s going to be very important.”
Within a decade, he predicts, generative AI could add trillions of dollars in economic growth in the US. “A majority of our economy is basically knowledge workers and information workers,” he says. “And it’s hard to think of any type of information workers that won’t be at least partly affected.”
When that productivity boost will come—if it does—is an economic guessing game. Maybe we just need to be patient.
In 1987, Robert Solow, the MIT economist who won the Nobel Prize that year for explaining how innovation drives economic growth, famously said, “You can see the computer age everywhere except in the productivity statistics.” It wasn’t until later, in the mid and late 1990s, that the impacts—particularly from advances in semiconductors—began showing up in the productivity data as businesses found ways to take advantage of ever cheaper computational power and related advances in software.
Could the same thing happen with AI? Avi Goldfarb, an economist at the University of Toronto, says it depends on whether we can figure out how to use the latest technology to transform businesses as we did in the earlier computer age.
So far, he says, companies have just been dropping in AI to do tasks a little bit better: “It’ll increase efficiency—it might incrementally increase productivity—but ultimately, the net benefits are going to be small. Because all you’re doing is the same thing a little bit better.” But, he says, “the technology doesn’t just allow us to do what we’ve always done a little bit better or a little bit cheaper. It might allow us to create new processes to create value to customers.”
The verdict on when—even if—that will happen with generative AI remains uncertain. “Once we figure out what good writing at scale allows industries to do differently, or—in the context of Dall-E—what graphic design at scale allows us to do differently, that’s when we’re going to experience the big productivity boost,” Goldfarb says. “But if that is next week or next year or 10 years from now, I have no idea.”
Power struggle
When Anton Korinek, an economist at the University of Virginia and a fellow at the Brookings Institution, got access to the new generation of large language models such as ChatGPT, he did what a lot of us did: he began playing around with them to see how they might help his work. He carefully documented their performance in a paper in February, noting how well they handled 25 “use cases,” from brainstorming and editing text (very useful) to coding (pretty good with some help) to doing math (not great).
ChatGPT did explain one of the most fundamental principles in economics incorrectly, says Korinek: “It screwed up really badly.” But the mistake, easily spotted, was quickly forgiven in light of the benefits. “I can tell you that it makes me, as a cognitive worker, more productive,” he says. “Hands down, no question for me that I’m more productive when I use a language model.”
When GPT-4 came out, he tested its performance on the same 25 questions that he documented in February, and it performed far better. There were fewer instances of making stuff up; it also did much better on the math assignments, says Korinek.
Since ChatGPT and other AI bots automate cognitive work, as opposed to physical tasks that require investments in equipment and infrastructure, a boost to economic productivity could happen far more quickly than in past technological revolutions, says Korinek. “I think we may see a greater boost to productivity by the end of the year—certainly by 2024,” he says.
What’s more, he says, in the longer term, the way the AI models can make researchers like himself more productive has the potential to drive technological progress.
That potential of large language models is already turning up in research in the physical sciences. Berend Smit, who runs a chemical engineering lab at EPFL in Lausanne, Switzerland, is an expert on using machine learning to discover new materials. Last year, after one of his graduate students, Kevin Maik Jablonka, showed some interesting results using GPT-3, Smit asked him to demonstrate that GPT-3 is, in fact, useless for the kinds of sophisticated machine-learning studies his group does to predict the properties of compounds.
“He failed completely,” jokes Smit.
It turns out that after being fine-tuned for a few minutes with a few relevant examples, the model performs as well as advanced machine-learning tools specially developed for chemistry in answering basic questions about things like the solubility of a compound or its reactivity. Simply give it the name of a compound, and it can predict various properties based on the structure.
As in other areas of work, large language models could help expand the expertise and capabilities of non-experts—in this case, chemists with little knowledge of complex machine-learning tools. Because it’s as simple as a literature search, Jablonka says, “it could bring machine learning to the masses of chemists.”
These impressive—and surprising—results are just a tantalizing hint of how powerful the new forms of AI could be across a wide swath of creative work, including scientific discovery, and how shockingly easy they are to use. But this also points to some fundamental questions.
As the potential impact of generative AI on the economy and jobs becomes more imminent, who will define the vision for how these tools should be designed and deployed? Who will control the future of this amazing technology?
Diane Coyle, an economist at Cambridge University in the UK, says one concern is the potential for large language models to be dominated by the same big companies that rule much of the digital world. Google and Meta are offering their own large language models alongside OpenAI, she points out, and the large computational costs required to run the software create a barrier to entry for anyone looking to compete.
The worry is that these companies have similar “advertising-driven business models,” Coyle says. “So obviously you get a certain uniformity of thought, if you don’t have different kinds of people with different kinds of incentives.”
Coyle acknowledges that there are no easy fixes, but she says one possibility is a publicly funded international research organization for generative AI, modeled after CERN, the Geneva-based intergovernmental European nuclear research body where the World Wide Web was created in 1989. It would be equipped with the huge computing power needed to run the models and the scientific expertise to further develop the technology.
Such an effort outside of Big Tech, says Coyle, would “bring some diversity to the incentives that the creators of the models face when they’re producing them.”
While it remains uncertain which public policies would help make sure that large language models best serve the public interest, says Coyle, it’s becoming clear that the choices about how we use the technology can’t be left to a few dominant companies and the market alone.
History provides us with plenty of examples of how important government-funded research can be in developing technologies that bring about widespread prosperity. Long before the invention of the web at CERN, another publicly funded effort in the late 1960s gave rise to the internet, when the US Department of Defense supported ARPANET, which pioneered ways for multiple computers to communicate with each other.
In Power and Progress: Our 1000-Year Struggle Over Technology & Prosperity, the MIT economists Daron Acemoglu and Simon Johnson provide a compelling walk through the history of technological progress and its mixed record in creating widespread prosperity. Their point is that it’s critical to deliberately steer technological advances in ways that provide broad benefits and don’t just make the elite richer.
From the decades after World War II until the early 1970s, the US economy was marked by rapid technological changes; wages for most workers rose while income inequality dropped sharply. The reason, Acemoglu and Johnson say, is that technological advances were used to create new tasks and jobs, while social and political pressures helped ensure that workers shared the benefits more equally with their employers than they do now.
In contrast, they write, the more recent rapid adoption of manufacturing robots in “the industrial heartland of the American economy in the Midwest” over the last few decades simply destroyed jobs and led to a “prolonged regional decline.”
The book, which comes out in May, is particularly relevant for understanding what today’s rapid progress in AI could bring and how decisions about the best way to use the breakthroughs will affect us all going forward. In a recent interview, Acemoglu said they were writing the book when GPT-3 was first released. And, he adds half-jokingly, “we foresaw ChatGPT.”
Acemoglu maintains that the creators of AI “are going in the wrong direction.” The entire architecture behind the AI “is in the automation mode,” he says. “But there is nothing inherent about generative AI or AI in general that should push us in this direction. It’s the business models and the vision of the people in OpenAI and Microsoft and the venture capital community.”
If you believe we can steer a technology’s trajectory, then an obvious question is: Who is “we”? And this is where Acemoglu and Johnson are most provocative. They write: “Society and its powerful gatekeepers need to stop being mesmerized by tech billionaires and their agenda … One does not need to be an AI expert to have a say about the direction of progress and the future of our society forged by these technologies.”
The creators of ChatGPT and the businesspeople involved in bringing it to market, notably OpenAI’s CEO, Sam Altman, deserve much credit for offering the new AI sensation to the public. Its potential is vast. But that doesn’t mean we must accept their vision and aspirations for where we want the technology to go and how it should be used.
According to their narrative, the end goal is artificial general intelligence, which, if all goes well, will lead to great economic wealth and abundances. Altman, for one, has promoted the vision at great length recently, providing further justification for his longtime advocacy of a universal basic income (UBI) to feed the non-technocrats among us. For some, it sounds tempting. No work and free money! Sweet!
It’s the assumptions underlying the narrative that are most troubling—namely, that AI is headed on an inevitable job-destroying path and most of us are just along for the (free?) ride. This view barely acknowledges the possibility that generative AI could lead to a creativity and productivity boom for workers far beyond the tech-savvy elites by helping to unlock their talents and brains. There is little discussion of the idea of using the technology to produce widespread prosperity by expanding human capabilities and expertise throughout the working population.
Companies can decide to use ChatGPT to give workers more abilities—or to simply cut jobs and trim costs.
As Acemoglu and Johnson write: “We are heading toward greater inequality not inevitably but because of faulty choices about who has power in society and the direction of technology … In fact, UBI fully buys into the vision of the business and tech elite that they are the enlightened, talented people who should generously finance the rest.”
Acemoglu and Johnson write of various tools for achieving “a more balanced technology portfolio,” from tax reforms and other government policies that might encourage the creation of more worker-friendly AI to reforms that might wean academia off Big Tech’s funding for computer science research and business schools.
But, the economists acknowledge, such reforms are “a tall order,” and a social push to redirect technological change is “not just around the corner.”
The good news is that, in fact, we can decide how we choose to use ChatGPT and other large language models. As countless apps based on the technology are rushed to market, businesses and individual users will have a chance to choose how they want to exploit it; companies can decide to use ChatGPT to give workers more abilities—or to simply cut jobs and trim costs.
Another positive development: there is at least some momentum behind open-source projects in generative AI, which could break Big Tech’s grip on the models. Notably, last year more than a thousand international researchers collaborated on a large language model called Bloom that can create text in languages such as French, Spanish, and Arabic. And if Coyle and others are right, increased public funding for AI research could help change the course of future breakthroughs.
Stanford’s Brynjolfsson refuses to say he’s optimistic about how it will play out. Still, his enthusiasm for the technology these days is clear. “We can have one of the best decades ever if we use the technology in the right direction,” he says. “But it’s not inevitable.”
BO LI, an associate professor at the University of Chicago who specializes in stress testing and provoking AI models to uncover misbehavior, has become a go-to source for some consulting firms. These consultancies are often now less concerned with how smart AI models are than with how problematic—legally, ethically, and in terms of regulatory compliance—they can be.
Li and colleagues from several other universities, as well as Virtue AI, cofounded by Li, and Lapis Labs, recently developed a taxonomy of AI risks along with a benchmark that reveals how rule-breaking different large language models are. “We need some principles for AI safety, in terms of regulatory compliance and ordinary usage,” Li tells WIRED.
Theresearchers analyzedgovernment AI regulations and guidelines, including those of the US, China, and the EU, and studied the usage policies of 16 major AI companies from around the world.
The researchers also built AIR-Bench 2024, a benchmark that uses thousands of prompts to determine how popular AI models fare in terms of specific risks. It shows, for example, that Anthropic’s Claude 3 Opus ranks highly when it comes to refusing to generate cybersecurity threats, while Google’s Gemini 1.5 Pro ranks highly in terms of avoiding generating nonconsensual sexual nudity.
Anthropic, Google, and Databricks did not immediately respond to a request for comment.
Understanding the risk landscape, as well as the pros and cons of specific models, may become increasingly important for companies looking to deploy AI in certain markets or for certain use cases. A company looking to use a LLM for customer service, for instance, might care more about a model’s propensity to produce offensive language when provoked than how capable it is of designing a nuclear device.
Bo says the analysis also reveals some interesting issues with how AI is being developed and regulated. For instance, the researchers found government rules to be less comprehensive than companies’ policies overall, suggesting that there is room for regulations to be tightened.
The analysis also suggests that some companies could do more to ensure their models are safe. “If you test some models against a company’s own policies, they are not necessarily compliant,” Bo says. “This means there is a lot of room for them to improve.”
Other researchers are trying to bring order to a messy and confusing AI risk landscape. This week, two researchers at MIT revealed their own database of AI dangers, compiled from 43 different AI risk frameworks. “Many organizations are still pretty early in that process of adopting AI,” meaning they need guidance on the possible perils, says Neil Thompson, a research scientist at MIT involved with the project.
Peter Slattery, lead on the project and a researcher at MIT’s FutureTech group, which studies progress in computing, says the database highlights the fact that some AI risks get more attention than others. More than 70 percent of frameworks mention privacy and security issues, for instance, but only around 40 percent refer to misinformation.
Efforts to catalog and measure AI risks will have to evolve as AI does. Li says it will be important to explore emerging issues such as the emotional stickiness of AI models. Her company recently analyzed the largest and most powerful version of Meta’s Llama 3.1 model. It found that although the model is more capable, it is not much safer, something that reflects a broader disconnect. “Safety is not really improving significantly,” Li says.
Our research describes the role of artificial intelligence (AI) models in digital advertising, highlighting their use in targeted persuasion. First we inspected digital marketing techniques that utilise AI-generated content and revealed cases of manipulative use of AI to conduct precision persuasion campaigns. Then we modelled a red team experiment to gain a deeper comprehension of current capabilities and tactics that adversaries can exploit while designing and conducting precision persuasion campaigns on social media.
To investigate why artificial intelligence and machine learning (AI/ML) projects fail, the authors interviewed 65 data scientists and engineers with at least five years of experience in building AI/ML models in industry or academia. The authors identified five leading root causes for the failure of AI projects and synthesized the experts’ experiences to develop recommendations to make AI projects more likely to succeed in industry settings and in academia.
By some estimates, more than 80 percent of AI projects fail — twice the rate of failure for information technology projects that do not involve AI. Thus, understanding how to translate AI’s enormous potential into concrete results remains an urgent challenge. The findings and recommendations of this report should be of interest to the U.S. Department of Defense, which has been actively looking for ways to use AI, along with other leaders in government and the private sector who are considering using AI/ML. The lessons from earlier efforts to build and apply AI/ML will help others avoid the same pitfalls.
Key Findings
Five leading root causes of the failure of AI projects were identified
First, industry stakeholders often misunderstand — or miscommunicate — what problem needs to be solved using AI.
Second, many AI projects fail because the organization lacks the necessary data to adequately train an effective AI model.
Third, in some cases, AI projects fail because the organization focuses more on using the latest and greatest technology than on solving real problems for their intended users.
Fourth, organizations might not have adequate infrastructure to manage their data and deploy completed AI models, which increases the likelihood of project failure.
Finally, in some cases, AI projects fail because the technology is applied to problems that are too difficult for AI to solve.
Recommendations
Industry leaders should ensure that technical staff understand the project purpose and domain context: Misunderstandings and miscommunications about the intent and purpose of the project are the most common reasons for AI project failure.
Industry leaders should choose enduring problems: AI projects require time and patience to complete. Before they begin any AI project, leaders should be prepared to commit each product team to solving a specific problem for at least a year.
Industry leaders should focus on the problem, not the technology: Successful projects are laser-focused on the problem to be solved, not the technology used to solve it.
Industry leaders should invest in infrastructure: Up-front investments in infrastructure to support data governance and model deployment can reduce the time required to complete AI projects and can increase the volume of high-quality data available to train effective AI models.
Industry leaders should understand AI’s limitations: When considering a potential AI project, leaders need to include technical experts to assess the project’s feasibility.
Academia leaders should overcome data-collection barriers through partnerships with government: Partnerships between academia and government agencies could give researchers access to data of the provenance needed for academic research.
Academia leaders should expand doctoral programs in data science for practitioners: Computer science and data science program leaders should learn from disciplines, such as international relations, in which practitioner doctoral programs often exist side by side at universities to provide pathways for researchers to apply their findings to urgent problems.
The first post-quantum cryptographic algorithms were officially released today, with more to come from ongoing public-private sector collaborations.
The first series of algorithms suited for post-quantum cryptographic needs debuted today, the culmination of public and private sector partnerships spearheaded by the National Institute of Standards and Technology.
Three algorithms, ML-KEM, formerly labeled CRYSTALS-Kyber, and ML-DSA, formerly labeled CRYSTAL-Dilithium, and SLH-DSA, initially labeled SPHINCS+, were all approved for standardization and are ready for implementation into existing digital networks. A fourth algorithm that made it to the final rounds of NIST’s standardization process, FALCON, is slated for debut later this year.
As the field of quantum information sciences and information continues to accelerate, cybersecurity officials have stressed the need to prepare digital networks for the advent of a fault-tolerant quantum computer that could potentially break through modern cryptography.
Should a quantum computer breakthrough current digital defenses, sensitive data and information would be vulnerable targets to malicious cyber actors. This led to NIST beginning its efforts in 2016 to develop new cryptography that would stand resilient to a potential post-quantum threat.
“NIST’s newly published standards are designed to safeguard data exchanged across public networks, as well as for digital signatures for identity authentication,” IBM said in a press release. “Now formalized, they will set the standard as the blueprints for governments and industries worldwide to begin adopting post-quantum cybersecurity strategies.”
IBM was one of the private sector companies that contributed to the development of both ML-KEM and ML-DSA. The company was one of the many entities that aided in the development of the algorithms, along with academic institutions and international partners.
“IBM’s mission in quantum computing is two-fold: to bring useful quantum computing to the world and to make the world quantum-safe. We are excited about the incredible progress we have made with today’s quantum computers, which are being used across global industries to explore problems as we push towards fully error-corrected systems,” said Jay Gambetta, Vice President, IBM Quantum. “However, we understand these advancements could herald an upheaval in the security of our most sensitive data and systems. NIST’s publication of the world’s first three post-quantum cryptography standards marks a significant step in efforts to build a quantum-safe future alongside quantum computing.”
This significant achievement underscores China’s growing capabilities in high-performance computing and artificial intelligence (AI).
Purpose-built for AI tasks:The Cixin P1 is specifically designed to handle the demanding computational requirements of artificial intelligence applications.
Potential for high performance:While specific benchmarks and performance metrics are yet to be fully disclosed, the processor is expected to deliver impressive results in AI-related workloads.
Domestic chip manufacturing:This development is a crucial step in China’s efforts to reduce reliance on foreign chipmakers and achieve self-sufficiency in the semiconductor industry.
With its state-of-the-art specifications and competitive features, the Cixin P1 is poised to make a substantial impact on the global semiconductor landscape.
Introducing the Cixin P1
Cixin Technology’s latest innovation, the Cixin P1, represents a major leap forward in China’s efforts to achieve technological self-sufficiency. This processor is based on ARM architecture, a design that has become increasingly popular in modern computing.
China has unveiled the Cixin P1, its first domestically developed AI PC processor. With a 12-core ARM architecture, 45 TOPS NPU, and support for up to 64GB of LPDDR5 memory, the Cixin P1 promises to rival global competitors.
Key Specifications
The Cixin P1 boasts a 12-core configuration, divided into eight performance cores and four efficiency cores. This setup allows for robust multitasking and high-performance computing.
The processor can reach a boost clock speed of up to 3.2 GHz, providing significant power for demanding applications.
It is manufactured using a 6nm process node, which ensures improved efficiency and performance compared to older process technologies.
AI Capabilities and Performance
A standout feature of the Cixin P1 is its integrated Neural Processing Unit (NPU), which delivers up to 45 TOPS (trillions of operations per second) in AIperformance. This places it on par with some of the latest AI-focused processors from global competitors.
The NPU is designed to handle intensive AI tasks, making the Cixin P1 well-suited for applications in machine learning, computer vision, and natural language processing.
The AI capabilities of the Cixin P1 are expected to drive innovation in various sectors, including smart devices, autonomous systems, and data analytics.
Its ability to process complex AI workloads efficiently could position it as a key player in the rapidly evolving AI landscape.
Memory and Display Support
The Cixin P1 supports up to 64GB of LPDDR5-6400 memory, providing ample bandwidth for high-performance computing tasks.
This is particularly advantageous for applications requiring substantial memory capacity, such as high-definition video processing and gaming.
Additionally, the processor can drive a 4K 120Hz display, enabling smooth and high-resolution visuals.
This feature is essential for applications that demand high-definition output, such as virtual reality (VR) and advanced gaming.
Connectivity and Expansion
The Cixin P1 includes support for PCIe Gen4, which offers faster data transfer rates compared to its predecessors.
This enhancement is crucial for applications requiring high-speed data access and storage.
The processor also features USB-C support, although it remains unclear whether this is limited to USB 3.2 or includes the more advanced USB4 standard.
USB-C connectivity is becoming increasingly important for versatile and high-speed data transfer, and clarity on this feature will be important for users and developers.
Significance and Market Impact
The Cixin P1’s launch is a landmark event for China’s semiconductor industry. The ability to develop and manufacture advanced processors domestically reduces the country’s reliance on foreign technology, enhancing its technological sovereignty.
This is particularly significant in the context of ongoing geopolitical tensions and trade restrictions, especially those involving the United States.
The Cixin P1 is expected to have a broad range of applications, including in consumer electronics, industrial automation, and data centers.
Its high-performance specifications make it an attractive option for companies and industries looking to leverage advanced computing and AIcapabilities.
Challenges and Future Outlook
While the Cixin P1 represents a significant technological achievement, several challenges remain. One of the primary concerns is the lack of comprehensive performance data.
As of now, there are no detailed benchmarks available to fully assess the processor’s real-world performance. This data will be crucial in determining the processor’s competitiveness in the global market.
Additionally, Cixin Technology will need to ensure that the Cixin P1 is supported by a robust software ecosystem.
Software compatibility and support are critical factors in the widespread adoption of new processors, and the company will need to address this to ensure the success of the Cixin P1.
Market perception will also play a role in the processor’s success. Gaining the trust of global consumers and businesses will require effective branding and marketing strategies.
The Cixin P1’s performance, combined with strategic positioning, will be key to its acceptance and success in the international market.
Conclusion
The Cixin P1 is a groundbreaking development for China’s semiconductor industry, showcasing the country’s growing capabilities in AI and advanced computing technologies.
With its impressive specifications and potential applications, the Cixin P1 has the potential to make a significant impact on the global processor market.
As more details emerge and performance benchmarks become available, the Cixin P1 could redefine the landscape of AI processors, offering a competitive alternative to established global players.
The launch of this processor highlights China’s commitment to innovation and technological advancement, setting the stage for further developments in the semiconductor industry.
For ongoing updates and detailed analyses of the Cixin P1 and other technological advancements, stay tuned to our coverage.